 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSDFP: Speculative Decoding with FIT-Pruned Models for Training-Free and Plug-and-Play LLM Acceleration
Feb 05, 2026Large language models (LLMs) underpin interactive multimedia applications such as captioning, retrieval, recommendation, and creative content generation, yet their autoregressive decoding incurs substantial latency. Speculative decoding reduces latency using a lightweight draft model, but deployment is often limited by the cost and complexity of acquiring, tuning, and maintaining an effective draft model. Recent approaches usually require auxiliary training or specialization, and even training-free methods incur costly search or optimization. We propose SDFP, a fully training-free and plug-and-play framework that builds the draft model via Fisher Information Trace (FIT)-based layer pruning of a given LLM. Using layer sensitivity as a proxy for output perturbation, SDFP removes low-impact layers to obtain a compact draft while preserving compatibility with the original model for standard speculative verification. SDFP needs no additional training, hyperparameter tuning, or separately maintained drafts, enabling rapid, deployment-friendly draft construction. Across benchmarks, SDFP delivers 1.32x-1.5x decoding speedup without altering the target model's output distribution, supporting low-latency multimedia applications.
DRL-Enabled Trajectory Planing for UAV-Assisted VLC: Optimal Altitude and Reward Design
Jan 30, 2026Recently, the integration of unmanned aerial vehicle (UAV) and visible light communication (VLC) technologies has emerged as a promising solution to offer flexible communication and efficient lighting. This letter investigates the three-dimensional trajectory planning in a UAV-assisted VLC system, where a UAV is dispatched to collect data from ground users (GUs). The core objective is to develop a trajectory planning framework that minimizes UAV flight distance, which is equivalent to maximizing the data collection efficiency. This issue is formulated as a challenging mixed-integer non-convex optimization problem. To tackle it, we first derive a closed-form optimal flight altitude under specific VLC channel gain threshold. Subsequently, we optimize the UAV horizontal trajectory by integrating a novel pheromone-driven reward mechanism with the twin delayed deep deterministic policy gradient algorithm, which enables adaptive UAV motion strategy in complex environments. Simulation results validate that the derived optimal altitude effectively reduces the flight distance by up to 35% compared to baseline methods. Additionally, the proposed reward mechanism significantly shortens the convergence steps by approximately 50%, demonstrating notable efficiency gains in the context of UAV-assisted VLC data collection.
Bayesian Beamforming for Integrated Sensing and Communication Systems
Feb 10, 2025
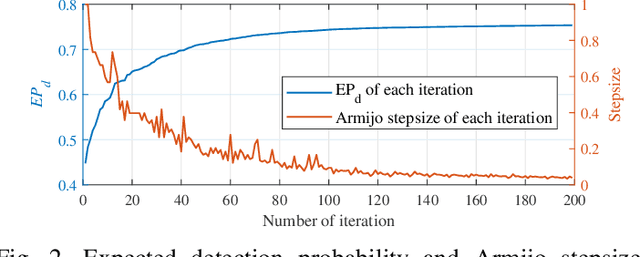


The uncertainty of the sensing target brings great challenge to the beamforming design of the integrated sensing and communication (ISAC) system. To address this issue, we model the scattering coefficient and azimuth angle of the target as random variables and introduce a novel metric, expected detection probability (EPd), to quantify the average detection performance from a Bayesian perspective. Furthermore, we design a Bayesian beamforming scheme to optimize the expected detection probability under the limited power budget and communication performance constraints. A successive convex approximation and semidefinite relaxation-based (SCA-SDR) algorithm is developed for the complicated non-convex optimization problem corresponding to the beamforming scheme. Simulation results show that the proposed scheme outperforms other benchmarks and exhibits robust detection performance when parameters of the target are unknown and random.
MR-COGraphs: Communication-efficient Multi-Robot Open-vocabulary Mapping System via 3D Scene Graphs
Dec 24, 2024Collaborative perception in unknown environments is crucial for multi-robot systems. With the emergence of foundation models, robots can now not only perceive geometric information but also achieve open-vocabulary scene understanding. However, existing map representations that support open-vocabulary queries often involve large data volumes, which becomes a bottleneck for multi-robot transmission in communication-limited environments. To address this challenge, we develop a method to construct a graph-structured 3D representation called COGraph, where nodes represent objects with semantic features and edges capture their spatial relationships. Before transmission, a data-driven feature encoder is applied to compress the feature dimensions of the COGraph. Upon receiving COGraphs from other robots, the semantic features of each node are recovered using a decoder. We also propose a feature-based approach for place recognition and translation estimation, enabling the merging of local COGraphs into a unified global map. We validate our framework using simulation environments built on Isaac Sim and real-world datasets. The results demonstrate that, compared to transmitting semantic point clouds and 512-dimensional COGraphs, our framework can reduce the data volume by two orders of magnitude, without compromising mapping and query performance. For more details, please visit our website at https://github.com/efc-robot/MR-COGraphs.
Joint Beamforming for Multi-target Detection and Multi-user Communication in ISAC Systems
Nov 01, 2024



Detecting weak targets is one of the main challenges for integrated sensing and communication (ISAC) systems. Sensing and communication suffer from a performance trade-off in ISAC systems. As the communication demand increases, sensing ability, especially weak target detection performance, will inevitably reduce. Traditional approaches fail to address this issue. In this paper, we develop a joint beamforming scheme and formulate it as a max-min problem to maximize the detection probability of the weakest target under the constraint of the signal-to-interference-plus-noise ratio (SINR) of multi-user communication. An alternating optimization (AO) algorithm is developed for solving the complicated non-convex problem to obtain the joint beamformer. The proposed scheme can direct the transmit energy toward the multiple targets properly to ensure robust multi-target detection performance. Numerical results show that the proposed beamforming scheme can effectively increase the detection probability of the weakest target compared to baseline approaches while ensuring communication performance.
Joint Beamforming for Backscatter Integrated Sensing and Communication
Sep 04, 2024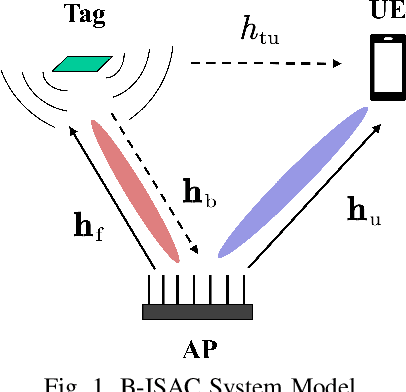
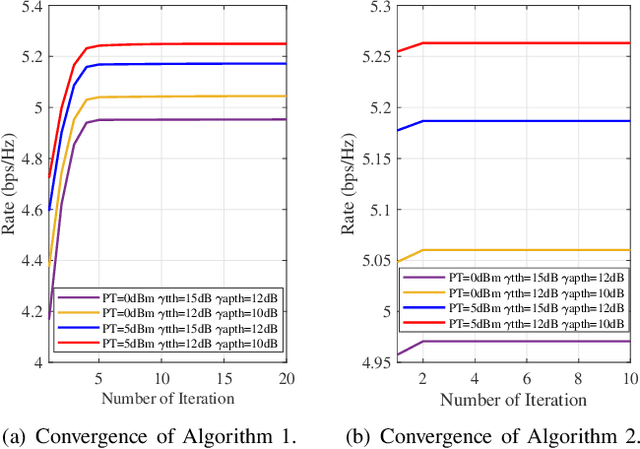
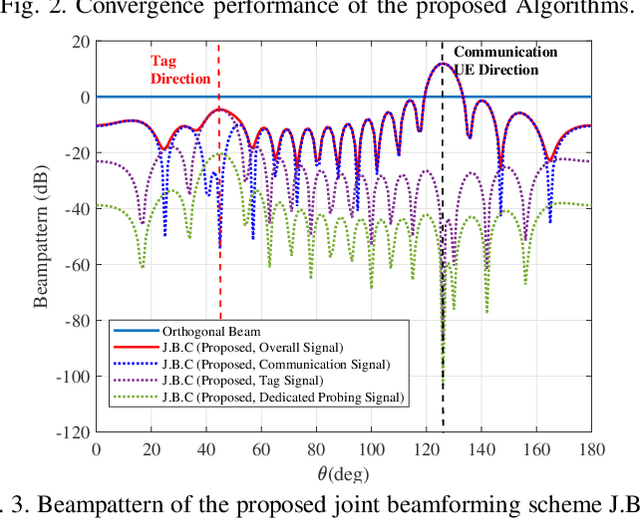
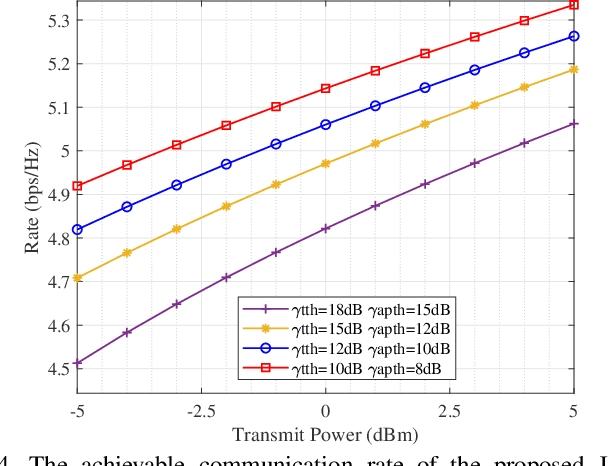
Integrated sensing and communication (ISAC) is a key technology of next generation wireless communication. Backscatter communication (BackCom) plays an important role for internet of things (IoT). Then the integration of ISAC with BackCom technology enables low-power data transmission while enhancing the system sensing ability, which is expected to provide a potentially revolutionary solution for IoT applications. In this paper, we propose a novel backscatter-ISAC (B-ISAC) system and focus on the joint beamforming design for the system. We formulate the communication and sensing model of the B-ISAC system and derive the metrics of communication and sensing performance respectively, i.e., communication rate and detection probability. We propose a joint beamforming scheme aiming to optimize the communication rate under sensing constraint and power budget. A successive convex approximation (SCA) based algorithm and an iterative algorithm are developed for solving the complicated non-convex optimization problem. Numerical results validate the effectiveness of the proposed scheme and associated algorithms. The proposed B-ISAC system has broad application prospect in IoT scenarios.
Misaligned Over-The-Air Computation of Multi-Sensor Data with Wiener-Denoiser Network
Sep 01, 2024In data driven deep learning, distributed sensing and joint computing bring heavy load for computing and communication. To face the challenge, over-the-air computation (OAC) has been proposed for multi-sensor data aggregation, which enables the server to receive a desired function of massive sensing data during communication. However, the strict synchronization and accurate channel estimation constraints in OAC are hard to be satisfied in practice, leading to time and channel-gain misalignment. The paper formulates the misalignment problem as a non-blind image deblurring problem. At the receiver side, we first use the Wiener filter to deblur, followed by a U-Net network designed for further denoising. Our method is capable to exploit the inherent correlations in the signal data via learning, thus outperforms traditional methods in term of accuracy. Our code is available at https://github.com/auto-Dog/MOAC_deep
B-ISAC: Backscatter Integrated Sensing and Communication for 6G IoE Applications
Jul 27, 2024The integration of backscatter communication (BackCom) technology with integrated sensing and communication (ISAC) technology not only enhances the system sensing performance, but also enables low-power information transmission. This is expected to provide a new paradigm for communication and sensing in internet of everything (IoE) applications. Existing works only consider sensing rate and detection performance, while none consider the estimation performance. The design of the system in different task modes also needs to be further studied. In this paper, we propose a novel system called backscatter-ISAC (B-ISAC) and design a joint beamforming framework for different stages (task modes). We derive communication performance metrics of the system in terms of the signal-to-interference-plus-noise ratio (SINR) and communication rate, and derive sensing performance metrics of the system in terms of probability of detection, estimation error of linear least squares (LS) estimation, and the estimation error of linear minimum mean square error (LMMSE) estimation. The proposed joint beamforming framework consists of three stages: tag detection, tag estimation, and communication enhancement. We develop corresponding joint beamforming schemes aimed at enhancing the performance objectives of their respective stages by solving complex non-convex optimization problems. Extensive simulation results demonstrate the effectiveness of the proposed joint beamforming schemes. The proposed B-ISAC system has broad application prospect in sixth generation (6G) IoE scenarios.
A Survey on Efficient Inference for Large Language Models
Apr 22, 2024Large Language Models (LLMs) have attracted extensive attention due to their remarkable performance across various tasks. However, the substantial computational and memory requirements of LLM inference pose challenges for deployment in resource-constrained scenarios. Efforts within the field have been directed towards developing techniques aimed at enhancing the efficiency of LLM inference. This paper presents a comprehensive survey of the existing literature on efficient LLM inference. We start by analyzing the primary causes of the inefficient LLM inference, i.e., the large model size, the quadratic-complexity attention operation, and the auto-regressive decoding approach. Then, we introduce a comprehensive taxonomy that organizes the current literature into data-level, model-level, and system-level optimization. Moreover, the paper includes comparative experiments on representative methods within critical sub-fields to provide quantitative insights. Last but not least, we provide some knowledge summary and discuss future research directions.
FlashDecoding++: Faster Large Language Model Inference on GPUs
Nov 10, 2023



As the Large Language Model (LLM) becomes increasingly important in various domains. However, the following challenges still remain unsolved in accelerating LLM inference: (1) Synchronized partial softmax update. The softmax operation requires a synchronized update operation among each partial softmax result, leading to ~20% overheads for the attention computation in LLMs. (2) Under-utilized computation of flat GEMM. The shape of matrices performing GEMM in LLM inference is flat, leading to under-utilized computation and >50% performance loss after padding zeros in previous designs. (3) Performance loss due to static dataflow. Kernel performance in LLM depends on varied input data features, hardware configurations, etc. A single and static dataflow may lead to a 50.25% performance loss for GEMMs of different shapes in LLM inference. We present FlashDecoding++, a fast LLM inference engine supporting mainstream LLMs and hardware back-ends. To tackle the above challenges, FlashDecoding++ creatively proposes: (1) Asynchronized softmax with unified max value. FlashDecoding++ introduces a unified max value technique for different partial softmax computations to avoid synchronization. (2) Flat GEMM optimization with double buffering. FlashDecoding++ points out that flat GEMMs with different shapes face varied bottlenecks. Then, techniques like double buffering are introduced. (3) Heuristic dataflow with hardware resource adaptation. FlashDecoding++ heuristically optimizes dataflow using different hardware resource considering input dynamics. Due to the versatility of optimizations in FlashDecoding++, FlashDecoding++ can achieve up to 4.86x and 2.18x speedup on both NVIDIA and AMD GPUs compared to Hugging Face implementations. FlashDecoding++ also achieves an average speedup of 1.37x compared to state-of-the-art LLM inference engines on mainstream LLMs.