 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrasp-Then-Plan with Failure Attribution: A Closed Two-Stage Framework for Precise and Generalizable Robotic Manipulation
Jun 02, 2026In robotic manipulation, the tight coupling between grasping and motion planning often obscures the true source of failure, leading to inefficient trial-and-error. To enable efficient long-horizon manipulation, we propose GTP-FA (Grasp-Then-Plan with Failure Attribution), a task-oriented two-stage grasp-then-plan framework that generates grasp candidates and performs downstream motion planning conditioned on the selected grasp. Given a failed manipulation trajectory, we learn a failure attribution model that generalizes to unseen grasps and produces a stable distribution over failure modes for diagnosis-guided optimization. Based on these attribution results, we then optimize both modules in a diagnosis-driven manner: on the grasping side, we inject task-level priors and risk penalties into grasp candidate scoring and optimization to suppress unstable or task-incompatible grasps; on the planning side, we target high-risk initial states through data collection and fine-tuning to address genuine planning bottlenecks. We evaluate the proposed framework in both simulation and real-robot experiments, and show that GTP-FA improves the corresponding base learners across RL, IL, diffusion-policy, and VLA-based settings, achieving substantially higher overall task success rates.
The Latent Space: Foundation, Evolution, Mechanism, Ability, and Outlook
Apr 02, 2026Latent space is rapidly emerging as a native substrate for language-based models. While modern systems are still commonly understood through explicit token-level generation, an increasing body of work shows that many critical internal processes are more naturally carried out in continuous latent space than in human-readable verbal traces. This shift is driven by the structural limitations of explicit-space computation, including linguistic redundancy, discretization bottlenecks, sequential inefficiency, and semantic loss. This survey aims to provide a unified and up-to-date landscape of latent space in language-based models. We organize the survey into five sequential perspectives: Foundation, Evolution, Mechanism, Ability, and Outlook. We begin by delineating the scope of latent space, distinguishing it from explicit or verbal space and from the latent spaces commonly studied in generative visual models. We then trace the field's evolution from early exploratory efforts to the current large-scale expansion. To organize the technical landscape, we examine existing work through the complementary lenses of mechanism and ability. From the perspective of Mechanism, we identify four major lines of development: Architecture, Representation, Computation, and Optimization. From the perspective of Ability, we show how latent space supports a broad capability spectrum spanning Reasoning, Planning, Modeling, Perception, Memory, Collaboration, and Embodiment. Beyond consolidation, we discuss the key open challenges, and outline promising directions for future research. We hope this survey serves not only as a reference for existing work, but also as a foundation for understanding latent space as a general computational and systems paradigm for next-generation intelligence.
Ran Score: a LLM-based Evaluation Score for Radiology Report Generation
Mar 24, 2026Chest X-ray report generation and automated evaluation are limited by poor recognition of low-prevalence abnormalities and inadequate handling of clinically important language, including negation and ambiguity. We develop a clinician-guided framework combining human expertise and large language models for multi-label finding extraction from free-text chest X-ray reports and use it to define Ran Score, a finding-level metric for report evaluation. Using three non-overlapping MIMIC-CXR-EN cohorts from a public chest X-ray dataset and an independent ChestX-CN validation cohort, we optimize prompts, establish radiologist-derived reference labels and evaluate report generation models. The optimized framework improves the macro-averaged score from 0.753 to 0.956 on the MIMIC-CXR-EN development cohort, exceeds the CheXbert benchmark by 15.7 percentage points on directly comparable labels, and shows robust generalization on the ChestX-CN validation cohort. Here we show that clinician-guided prompt optimization improves agreement with a radiologist-derived reference standard and that Ran Score enables finding-level evaluation of report fidelity, particularly for low-prevalence abnormalities.
UPA: Unsupervised Prompt Agent via Tree-Based Search and Selection
Jan 30, 2026Prompt agents have recently emerged as a promising paradigm for automated prompt optimization, framing refinement as a sequential decision-making problem over a structured prompt space. While this formulation enables the use of advanced planning algorithms, these methods typically assume access to supervised reward signals, which are often unavailable in practical scenarios. In this work, we propose UPA, an Unsupervised Prompt Agent that realizes structured search and selection without relying on supervised feedback. Specifically, during search, UPA iteratively constructs an evolving tree structure to navigate the prompt space, guided by fine-grained and order-invariant pairwise comparisons from Large Language Models (LLMs). Crucially, as these local comparisons do not inherently yield a consistent global scale, we decouple systematic prompt exploration from final selection, introducing a two-stage framework grounded in the Bradley-Terry-Luce (BTL) model. This framework first performs path-wise Bayesian aggregation of local comparisons to filter candidates under uncertainty, followed by global tournament-style comparisons to infer latent prompt quality and identify the optimal prompt. Experiments across multiple tasks demonstrate that UPA consistently outperforms existing prompt optimization methods, showing that agent-style optimization remains highly effective even in fully unsupervised settings.
Think-at-Hard: Selective Latent Iterations to Improve Reasoning Language Models
Nov 11, 2025Improving reasoning capabilities of Large Language Models (LLMs), especially under parameter constraints, is crucial for real-world applications. Prior work proposes recurrent transformers, which allocate a fixed number of extra iterations per token to improve generation quality. After the first, standard forward pass, instead of verbalization, last-layer hidden states are fed back as inputs for additional iterations to refine token predictions. Yet we identify a latent overthinking phenomenon: easy token predictions that are already correct after the first pass are sometimes revised into errors in additional iterations. To address this, we propose Think-at-Hard (TaH), a dynamic latent thinking method that iterates deeper only at hard tokens. It employs a lightweight neural decider to trigger latent iterations only at tokens that are likely incorrect after the standard forward pass. During latent iterations, Low-Rank Adaptation (LoRA) modules shift the LLM objective from general next-token prediction to focused hard-token refinement. We further introduce a duo-causal attention mechanism that extends attention from the token sequence dimension to an additional iteration depth dimension. This enables cross-iteration information flow while maintaining full sequential parallelism. Experiments show that TaH boosts LLM reasoning performance across five challenging benchmarks while maintaining the same parameter count. Compared with baselines that iterate twice for all output tokens, TaH delivers 8.1-11.3% accuracy gains while exempting 94% of tokens from the second iteration. Against strong single-iteration Qwen3 models finetuned with the same data, it also delivers 4.0-5.0% accuracy gains. When allowing less than 3% additional parameters from LoRA and the iteration decider, the gains increase to 8.5-12.6% and 5.3-5.4%, respectively. Our code is available at https://github.com/thu-nics/TaH.
Robust Point Cloud Registration via Geometric Overlapping Guided Rotation Search
Aug 24, 2025Point cloud registration based on correspondences computes the rigid transformation that maximizes the number of inliers constrained within the noise threshold. Current state-of-the-art (SOTA) methods employing spatial compatibility graphs or branch-and-bound (BnB) search mainly focus on registration under high outlier ratios. However, graph-based methods require at least quadratic space and time complexity for graph construction, while multi-stage BnB search methods often suffer from inaccuracy due to local optima between decomposed stages. This paper proposes a geometric maximum overlapping registration framework via rotation-only BnB search. The rigid transformation is decomposed using Chasles' theorem into a translation along rotation axis and a 2D rigid transformation. The optimal rotation axis and angle are searched via BnB, with residual parameters formulated as range maximum query (RMQ) problems. Firstly, the top-k candidate rotation axes are searched within a hemisphere parameterized by cube mapping, and the translation along each axis is estimated through interval stabbing of the correspondences projected onto that axis. Secondly, the 2D registration is relaxed to 1D rotation angle search with 2D RMQ of geometric overlapping for axis-aligned rectangles, which is solved deterministically in polynomial time using sweep line algorithm with segment tree. Experimental results on 3DMatch, 3DLoMatch, and KITTI datasets demonstrate superior accuracy and efficiency over SOTA methods, while the time complexity is polynomial and the space complexity increases linearly with the number of points, even in the worst case.
Sculpting Margin Penalty: Intra-Task Adapter Merging and Classifier Calibration for Few-Shot Class-Incremental Learning
Aug 07, 2025Real-world applications often face data privacy constraints and high acquisition costs, making the assumption of sufficient training data in incremental tasks unrealistic and leading to significant performance degradation in class-incremental learning. Forward-compatible learning, which prospectively prepares for future tasks during base task training, has emerged as a promising solution for Few-Shot Class-Incremental Learning (FSCIL). However, existing methods still struggle to balance base-class discriminability and new-class generalization. Moreover, limited access to original data during incremental tasks often results in ambiguous inter-class decision boundaries. To address these challenges, we propose SMP (Sculpting Margin Penalty), a novel FSCIL method that strategically integrates margin penalties at different stages within the parameter-efficient fine-tuning paradigm. Specifically, we introduce the Margin-aware Intra-task Adapter Merging (MIAM) mechanism for base task learning. MIAM trains two sets of low-rank adapters with distinct classification losses: one with a margin penalty to enhance base-class discriminability, and the other without margin constraints to promote generalization to future new classes. These adapters are then adaptively merged to improve forward compatibility. For incremental tasks, we propose a Margin Penalty-based Classifier Calibration (MPCC) strategy to refine decision boundaries by fine-tuning classifiers on all seen classes' embeddings with a margin penalty. Extensive experiments on CIFAR100, ImageNet-R, and CUB200 demonstrate that SMP achieves state-of-the-art performance in FSCIL while maintaining a better balance between base and new classes.
R2R: Efficiently Navigating Divergent Reasoning Paths with Small-Large Model Token Routing
May 27, 2025Large Language Models (LLMs) achieve impressive reasoning capabilities at the cost of substantial inference overhead, posing substantial deployment challenges. Although distilled Small Language Models (SLMs) significantly enhance efficiency, their performance suffers as they fail to follow LLMs' reasoning paths. Luckily, we reveal that only a small fraction of tokens genuinely diverge reasoning paths between LLMs and SLMs. Most generated tokens are either identical or exhibit neutral differences, such as minor variations in abbreviations or expressions. Leveraging this insight, we introduce **Roads to Rome (R2R)**, a neural token routing method that selectively utilizes LLMs only for these critical, path-divergent tokens, while leaving the majority of token generation to the SLM. We also develop an automatic data generation pipeline that identifies divergent tokens and generates token-level routing labels to train the lightweight router. We apply R2R to combine R1-1.5B and R1-32B models from the DeepSeek family, and evaluate on challenging math, coding, and QA benchmarks. With an average activated parameter size of 5.6B, R2R surpasses the average accuracy of R1-7B by 1.6x, outperforming even the R1-14B model. Compared to R1-32B, it delivers a 2.8x wall-clock speedup with comparable performance, advancing the Pareto frontier of test-time scaling efficiency. Our code is available at https://github.com/thu-nics/R2R.
MetaFE-DE: Learning Meta Feature Embedding for Depth Estimation from Monocular Endoscopic Images
Feb 05, 2025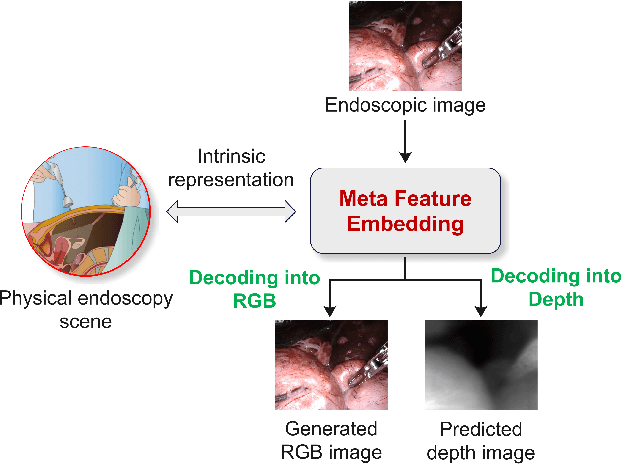

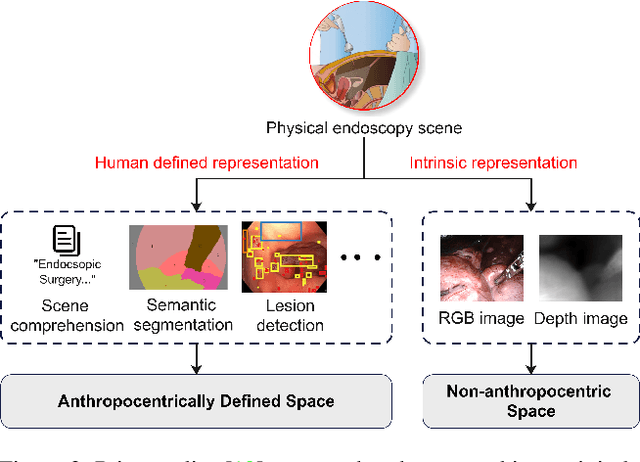

Depth estimation from monocular endoscopic images presents significant challenges due to the complexity of endoscopic surgery, such as irregular shapes of human soft tissues, as well as variations in lighting conditions. Existing methods primarily estimate the depth information from RGB images directly, and often surffer the limited interpretability and accuracy. Given that RGB and depth images are two views of the same endoscopic surgery scene, in this paper, we introduce a novel concept referred as ``meta feature embedding (MetaFE)", in which the physical entities (e.g., tissues and surgical instruments) of endoscopic surgery are represented using the shared features that can be alternatively decoded into RGB or depth image. With this concept, we propose a two-stage self-supervised learning paradigm for the monocular endoscopic depth estimation. In the first stage, we propose a temporal representation learner using diffusion models, which are aligned with the spatial information through the cross normalization to construct the MetaFE. In the second stage, self-supervised monocular depth estimation with the brightness calibration is applied to decode the meta features into the depth image. Extensive evaluation on diverse endoscopic datasets demonstrates that our approach outperforms the state-of-the-art method in depth estimation, achieving superior accuracy and generalization. The source code will be publicly available.
FrameFusion: Combining Similarity and Importance for Video Token Reduction on Large Visual Language Models
Dec 30, 2024
The increasing demand to process long and high-resolution videos significantly burdens Large Vision-Language Models (LVLMs) due to the enormous number of visual tokens. Existing token reduction methods primarily focus on importance-based token pruning, which overlooks the redundancy caused by frame resemblance and repetitive visual elements. In this paper, we analyze the high vision token similarities in LVLMs. We reveal that token similarity distribution condenses as layers deepen while maintaining ranking consistency. Leveraging the unique properties of similarity over importance, we introduce FrameFusion, a novel approach that combines similarity-based merging with importance-based pruning for better token reduction in LVLMs. FrameFusion identifies and merges similar tokens before pruning, opening up a new perspective for token reduction. We evaluate FrameFusion on diverse LVLMs, including Llava-Video-{7B,32B,72B}, and MiniCPM-V-8B, on video understanding, question-answering, and retrieval benchmarks. Experiments show that FrameFusion reduces vision tokens by 70$\%$, achieving 3.4-4.4x LLM speedups and 1.6-1.9x end-to-end speedups, with an average performance impact of less than 3$\%$. Our code is available at https://github.com/thu-nics/FrameFusion.