 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRan Score: a LLM-based Evaluation Score for Radiology Report Generation
Mar 24, 2026Chest X-ray report generation and automated evaluation are limited by poor recognition of low-prevalence abnormalities and inadequate handling of clinically important language, including negation and ambiguity. We develop a clinician-guided framework combining human expertise and large language models for multi-label finding extraction from free-text chest X-ray reports and use it to define Ran Score, a finding-level metric for report evaluation. Using three non-overlapping MIMIC-CXR-EN cohorts from a public chest X-ray dataset and an independent ChestX-CN validation cohort, we optimize prompts, establish radiologist-derived reference labels and evaluate report generation models. The optimized framework improves the macro-averaged score from 0.753 to 0.956 on the MIMIC-CXR-EN development cohort, exceeds the CheXbert benchmark by 15.7 percentage points on directly comparable labels, and shows robust generalization on the ChestX-CN validation cohort. Here we show that clinician-guided prompt optimization improves agreement with a radiologist-derived reference standard and that Ran Score enables finding-level evaluation of report fidelity, particularly for low-prevalence abnormalities.
Scale-Aware Relay and Scale-Adaptive Loss for Tiny Object Detection in Aerial Images
Nov 13, 2025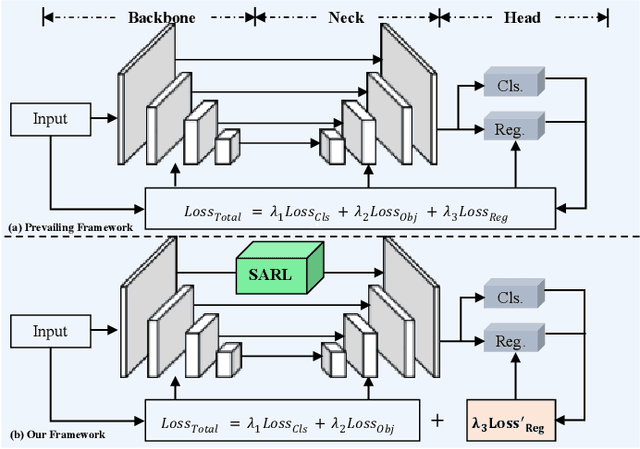
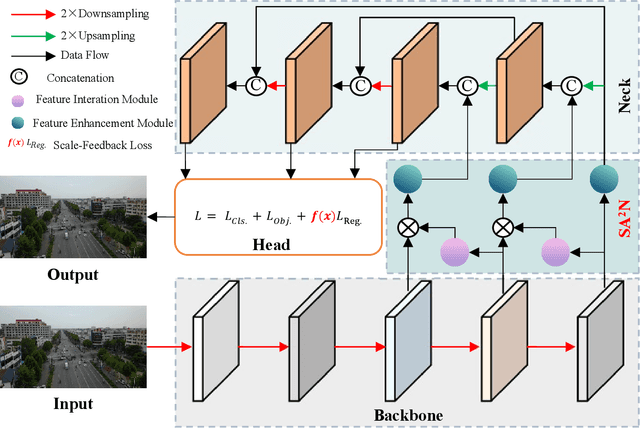
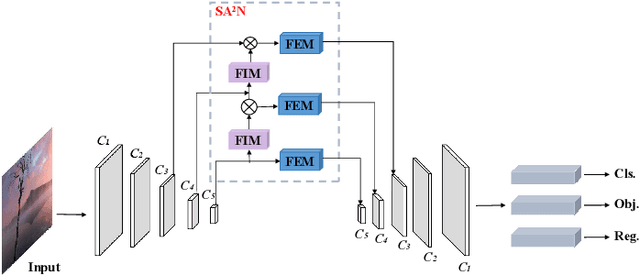
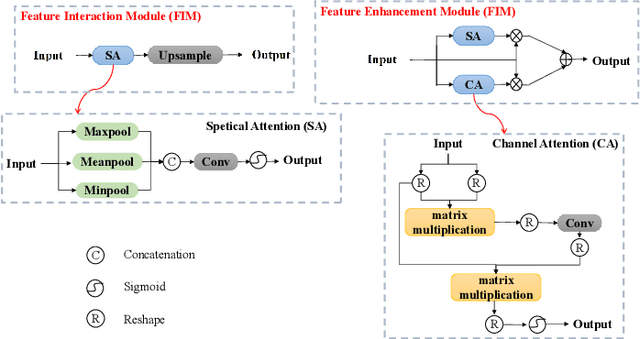
Recently, despite the remarkable advancements in object detection, modern detectors still struggle to detect tiny objects in aerial images. One key reason is that tiny objects carry limited features that are inevitably degraded or lost during long-distance network propagation. Another is that smaller objects receive disproportionately greater regression penalties than larger ones during training. To tackle these issues, we propose a Scale-Aware Relay Layer (SARL) and a Scale-Adaptive Loss (SAL) for tiny object detection, both of which are seamlessly compatible with the top-performing frameworks. Specifically, SARL employs a cross-scale spatial-channel attention to progressively enrich the meaningful features of each layer and strengthen the cross-layer feature sharing. SAL reshapes the vanilla IoU-based losses so as to dynamically assign lower weights to larger objects. This loss is able to focus training on tiny objects while reducing the influence on large objects. Extensive experiments are conducted on three benchmarks (\textit{i.e.,} AI-TOD, DOTA-v2.0 and VisDrone2019), and the results demonstrate that the proposed method boosts the generalization ability by 5.5\% Average Precision (AP) when embedded in YOLOv5 (anchor-based) and YOLOx (anchor-free) baselines. Moreover, it also promotes the robust performance with 29.0\% AP on the real-world noisy dataset (\textit{i.e.,} AI-TOD-v2.0).
Robust Point Cloud Registration via Geometric Overlapping Guided Rotation Search
Aug 24, 2025Point cloud registration based on correspondences computes the rigid transformation that maximizes the number of inliers constrained within the noise threshold. Current state-of-the-art (SOTA) methods employing spatial compatibility graphs or branch-and-bound (BnB) search mainly focus on registration under high outlier ratios. However, graph-based methods require at least quadratic space and time complexity for graph construction, while multi-stage BnB search methods often suffer from inaccuracy due to local optima between decomposed stages. This paper proposes a geometric maximum overlapping registration framework via rotation-only BnB search. The rigid transformation is decomposed using Chasles' theorem into a translation along rotation axis and a 2D rigid transformation. The optimal rotation axis and angle are searched via BnB, with residual parameters formulated as range maximum query (RMQ) problems. Firstly, the top-k candidate rotation axes are searched within a hemisphere parameterized by cube mapping, and the translation along each axis is estimated through interval stabbing of the correspondences projected onto that axis. Secondly, the 2D registration is relaxed to 1D rotation angle search with 2D RMQ of geometric overlapping for axis-aligned rectangles, which is solved deterministically in polynomial time using sweep line algorithm with segment tree. Experimental results on 3DMatch, 3DLoMatch, and KITTI datasets demonstrate superior accuracy and efficiency over SOTA methods, while the time complexity is polynomial and the space complexity increases linearly with the number of points, even in the worst case.
Sculpting Margin Penalty: Intra-Task Adapter Merging and Classifier Calibration for Few-Shot Class-Incremental Learning
Aug 07, 2025Real-world applications often face data privacy constraints and high acquisition costs, making the assumption of sufficient training data in incremental tasks unrealistic and leading to significant performance degradation in class-incremental learning. Forward-compatible learning, which prospectively prepares for future tasks during base task training, has emerged as a promising solution for Few-Shot Class-Incremental Learning (FSCIL). However, existing methods still struggle to balance base-class discriminability and new-class generalization. Moreover, limited access to original data during incremental tasks often results in ambiguous inter-class decision boundaries. To address these challenges, we propose SMP (Sculpting Margin Penalty), a novel FSCIL method that strategically integrates margin penalties at different stages within the parameter-efficient fine-tuning paradigm. Specifically, we introduce the Margin-aware Intra-task Adapter Merging (MIAM) mechanism for base task learning. MIAM trains two sets of low-rank adapters with distinct classification losses: one with a margin penalty to enhance base-class discriminability, and the other without margin constraints to promote generalization to future new classes. These adapters are then adaptively merged to improve forward compatibility. For incremental tasks, we propose a Margin Penalty-based Classifier Calibration (MPCC) strategy to refine decision boundaries by fine-tuning classifiers on all seen classes' embeddings with a margin penalty. Extensive experiments on CIFAR100, ImageNet-R, and CUB200 demonstrate that SMP achieves state-of-the-art performance in FSCIL while maintaining a better balance between base and new classes.
MetaFE-DE: Learning Meta Feature Embedding for Depth Estimation from Monocular Endoscopic Images
Feb 05, 2025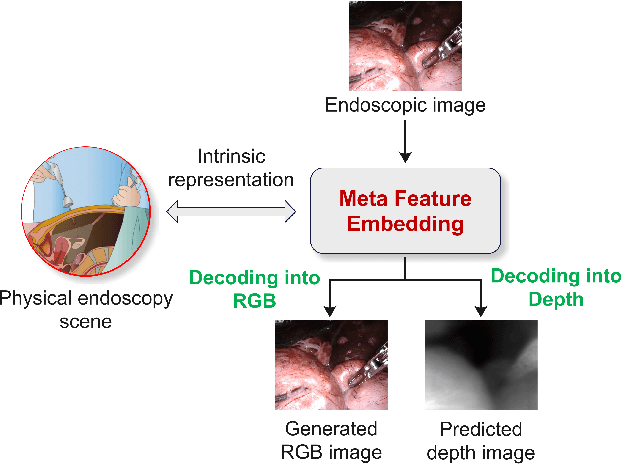

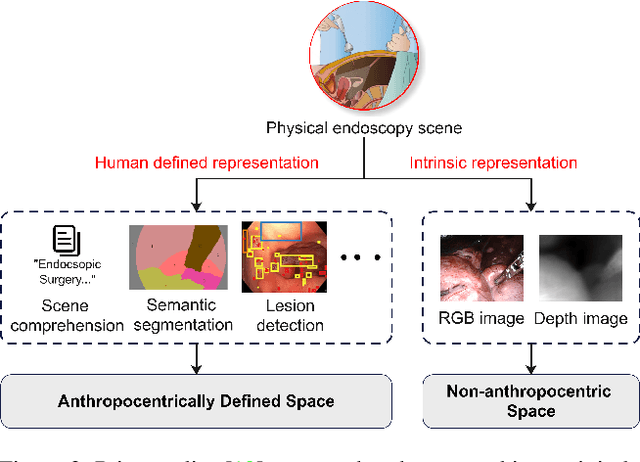

Depth estimation from monocular endoscopic images presents significant challenges due to the complexity of endoscopic surgery, such as irregular shapes of human soft tissues, as well as variations in lighting conditions. Existing methods primarily estimate the depth information from RGB images directly, and often surffer the limited interpretability and accuracy. Given that RGB and depth images are two views of the same endoscopic surgery scene, in this paper, we introduce a novel concept referred as ``meta feature embedding (MetaFE)", in which the physical entities (e.g., tissues and surgical instruments) of endoscopic surgery are represented using the shared features that can be alternatively decoded into RGB or depth image. With this concept, we propose a two-stage self-supervised learning paradigm for the monocular endoscopic depth estimation. In the first stage, we propose a temporal representation learner using diffusion models, which are aligned with the spatial information through the cross normalization to construct the MetaFE. In the second stage, self-supervised monocular depth estimation with the brightness calibration is applied to decode the meta features into the depth image. Extensive evaluation on diverse endoscopic datasets demonstrates that our approach outperforms the state-of-the-art method in depth estimation, achieving superior accuracy and generalization. The source code will be publicly available.
Efficient Non-Exemplar Class-Incremental Learning with Retrospective Feature Synthesis
Nov 03, 2024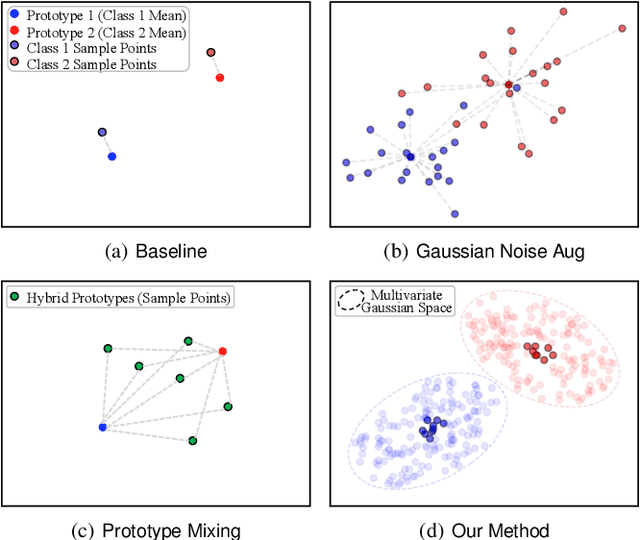
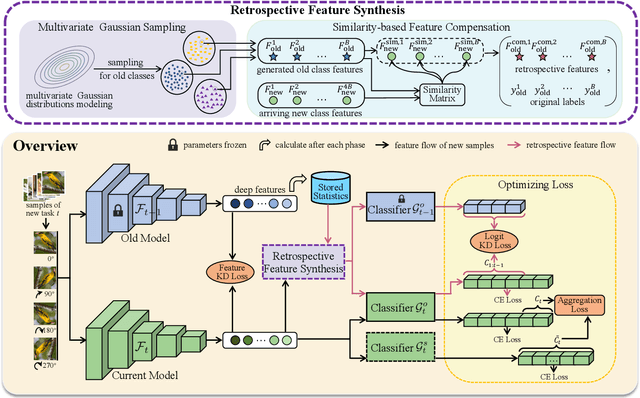
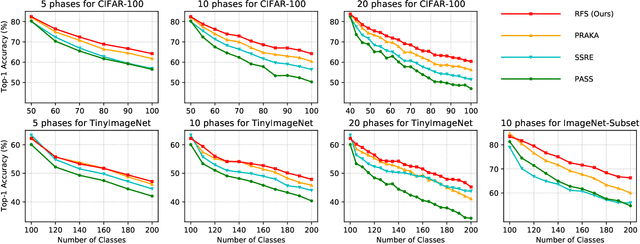
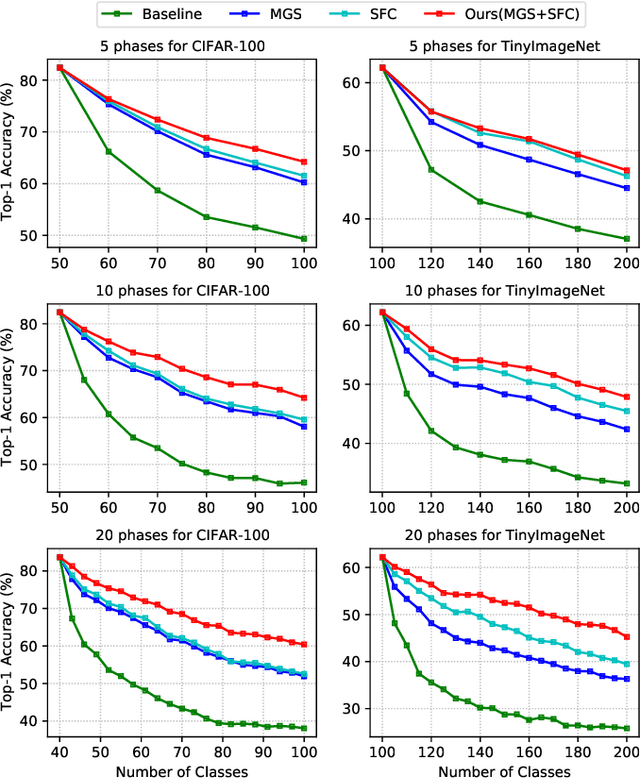
Despite the outstanding performance in many individual tasks, deep neural networks suffer from catastrophic forgetting when learning from continuous data streams in real-world scenarios. Current Non-Exemplar Class-Incremental Learning (NECIL) methods mitigate forgetting by storing a single prototype per class, which serves to inject previous information when sequentially learning new classes. However, these stored prototypes or their augmented variants often fail to simultaneously capture spatial distribution diversity and precision needed for representing old classes. Moreover, as the model acquires new knowledge, these prototypes gradually become outdated, making them less effective. To overcome these limitations, we propose a more efficient NECIL method that replaces prototypes with synthesized retrospective features for old classes. Specifically, we model each old class's feature space using a multivariate Gaussian distribution and generate deep representations by sampling from high-likelihood regions. Additionally, we introduce a similarity-based feature compensation mechanism that integrates generated old class features with similar new class features to synthesize robust retrospective representations. These retrospective features are then incorporated into our incremental learning framework to preserve the decision boundaries of previous classes while learning new ones. Extensive experiments on CIFAR-100, TinyImageNet, and ImageNet-Subset demonstrate that our method significantly improves the efficiency of non-exemplar class-incremental learning and achieves state-of-the-art performance.
Double-Shot 3D Shape Measurement with a Dual-Branch Network
Jul 19, 2024



The structured light (SL)-based 3D measurement techniques with deep learning have been widely studied, among which speckle projection profilometry (SPP) and fringe projection profilometry (FPP) are two popular methods. However, they generally use a single projection pattern for reconstruction, resulting in fringe order ambiguity or poor reconstruction accuracy. To alleviate these problems, we propose a parallel dual-branch Convolutional Neural Network (CNN)-Transformer network (PDCNet), to take advantage of convolutional operations and self-attention mechanisms for processing different SL modalities. Within PDCNet, a Transformer branch is used to capture global perception in the fringe images, while a CNN branch is designed to collect local details in the speckle images. To fully integrate complementary features, we design a double-stream attention aggregation module (DAAM) that consist of a parallel attention subnetwork for aggregating multi-scale spatial structure information. This module can dynamically retain local and global representations to the maximum extent. Moreover, an adaptive mixture density head with bimodal Gaussian distribution is proposed for learning a representation that is precise near discontinuities. Compared to the standard disparity regression strategy, this adaptive mixture head can effectively improves performance at object boundaries. Extensive experiments demonstrate that our method can reduce fringe order ambiguity while producing high-accuracy results on a self-made dataset. We also show that the proposed architecture reveals the potential in infrared-visible image fusion task.
Refined Response Distillation for Class-Incremental Player Detection
May 01, 2023

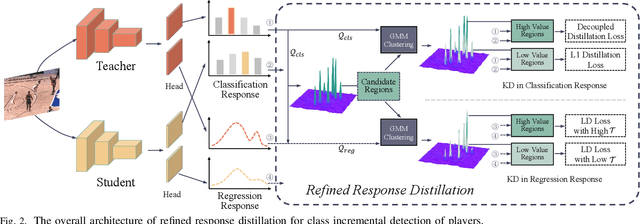

Detecting players from sports broadcast videos is essential for intelligent event analysis. However, existing methods assume fixed player categories, incapably accommodating the real-world scenarios where categories continue to evolve. Directly fine-tuning these methods on newly emerging categories also exist the catastrophic forgetting due to the non-stationary distribution. Inspired by recent research on incremental object detection (IOD), we propose a Refined Response Distillation (R^2D) method to effectively mitigate catastrophic forgetting for IOD tasks of the players. Firstly, we design a progressive coarse-to-fine distillation region dividing scheme, separating high-value and low-value regions from classification and regression responses for precise and fine-grained regional knowledge distillation. Subsequently, a tailored refined distillation strategy is developed on regions with varying significance to address the performance limitations posed by pronounced feature homogeneity in the IOD tasks of the players. Furthermore, we present the NBA-IOD and Volleyball-IOD datasets as the benchmark and investigate the IOD tasks of the players systematically. Extensive experiments conducted on benchmarks demonstrate that our method achieves state-of-the-art results.The code and datasets are available at https://github.com/beiyan1911/Players-IOD.
High-Resolution Boundary Detection for Medical Image Segmentation with Piece-Wise Two-Sample T-Test Augmented Loss
Nov 04, 2022



Deep learning methods have contributed substantially to the rapid advancement of medical image segmentation, the quality of which relies on the suitable design of loss functions. Popular loss functions, including the cross-entropy and dice losses, often fall short of boundary detection, thereby limiting high-resolution downstream applications such as automated diagnoses and procedures. We developed a novel loss function that is tailored to reflect the boundary information to enhance the boundary detection. As the contrast between segmentation and background regions along the classification boundary naturally induces heterogeneity over the pixels, we propose the piece-wise two-sample t-test augmented (PTA) loss that is infused with the statistical test for such heterogeneity. We demonstrate the improved boundary detection power of the PTA loss compared to benchmark losses without a t-test component.
Rethinking the Artificial Neural Networks: A Mesh of Subnets with a Central Mechanism for Storing and Predicting the Data
Jan 05, 2019
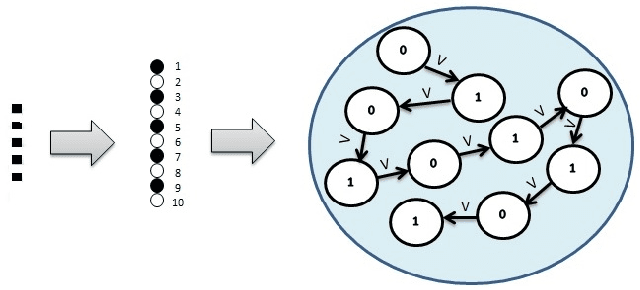
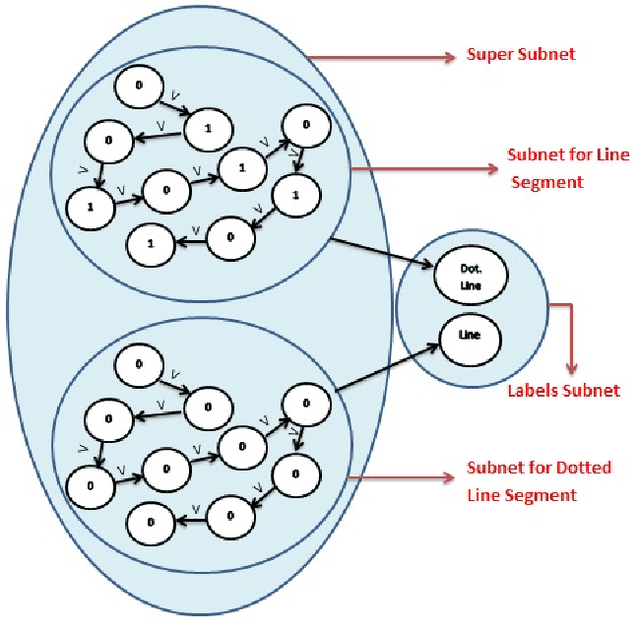
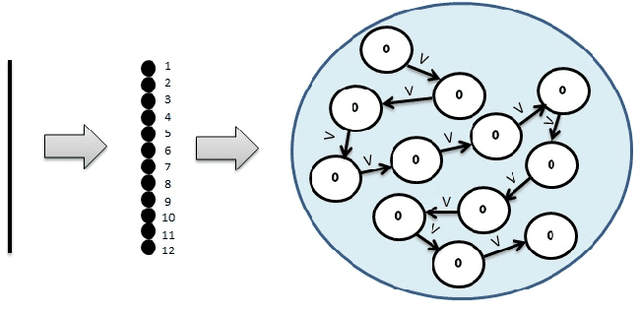
The Artificial Neural Networks (ANNs) have been originally designed to function like a biological neural network, but does an ANN really work in the same way as a biological neural network? As we know, the human brain holds information in its memory cells, so if the ANNs use the same model as our brains, they should store datasets in a similar manner. The most popular type of ANN architecture is based on a layered structure of neurons, whereas a human brain has trillions of complex interconnections of neurons continuously establishing new connections, updating existing ones, and removing the irrelevant connections across different parts of the brain. In this paper, we propose a novel approach to building ANNs which are truly inspired by the biological network containing a mesh of subnets controlled by a central mechanism. A subnet is a network of neurons that hold the dataset values. We attempt to address the following fundamental questions: (1) What is the architecture of the ANN model? Whether the layered architecture is the most appropriate choice? (2) Whether a neuron is a process or a memory cell? (3) What is the best way of interconnecting neurons and what weight-assignment mechanism should be used? (4) How to incorporate prior knowledge, bias, and generalizations for features extraction and prediction? Our proposed ANN architecture leverages the accuracy on textual data and our experimental findings confirm the effectiveness of our model. We also collaborate with the construction of the ANN model for storing and processing the images.