 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Diffusion-Based Image Generators for Fundus Fluorescein Angiography Synthesis on Limited Data
Dec 17, 2024Fundus imaging is a critical tool in ophthalmology, with different imaging modalities offering unique advantages. For instance, fundus fluorescein angiography (FFA) can accurately identify eye diseases. However, traditional invasive FFA involves the injection of sodium fluorescein, which can cause discomfort and risks. Generating corresponding FFA images from non-invasive fundus images holds significant practical value but also presents challenges. First, limited datasets constrain the performance and effectiveness of models. Second, previous studies have primarily focused on generating FFA for single diseases or single modalities, often resulting in poor performance for patients with various ophthalmic conditions. To address these issues, we propose a novel latent diffusion model-based framework, Diffusion, which introduces a fine-tuning protocol to overcome the challenge of limited medical data and unleash the generative capabilities of diffusion models. Furthermore, we designed a new approach to tackle the challenges of generating across different modalities and disease types. On limited datasets, our framework achieves state-of-the-art results compared to existing methods, offering significant potential to enhance ophthalmic diagnostics and patient care. Our code will be released soon to support further research in this field.
ETSCL: An Evidence Theory-Based Supervised Contrastive Learning Framework for Multi-modal Glaucoma Grading
Jul 19, 2024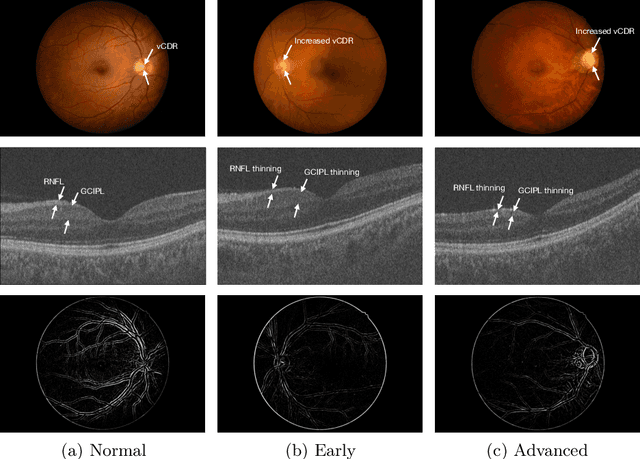

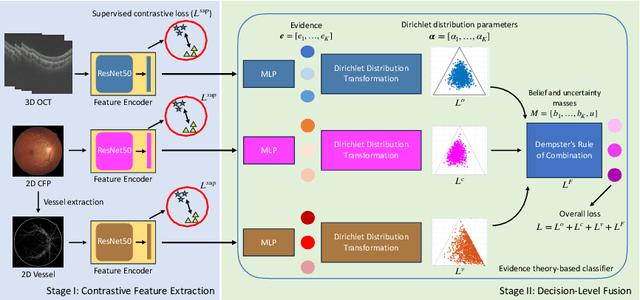
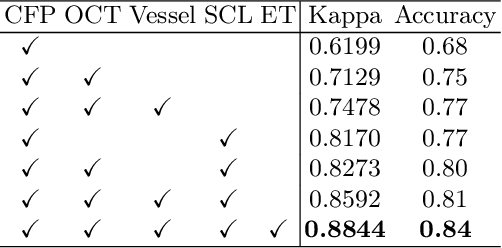
Glaucoma is one of the leading causes of vision impairment. Digital imaging techniques, such as color fundus photography (CFP) and optical coherence tomography (OCT), provide quantitative and noninvasive methods for glaucoma diagnosis. Recently, in the field of computer-aided glaucoma diagnosis, multi-modality methods that integrate the CFP and OCT modalities have achieved greater diagnostic accuracy compared to single-modality methods. However, it remains challenging to extract reliable features due to the high similarity of medical images and the unbalanced multi-modal data distribution. Moreover, existing methods overlook the uncertainty estimation of different modalities, leading to unreliable predictions. To address these challenges, we propose a novel framework, namely ETSCL, which consists of a contrastive feature extraction stage and a decision-level fusion stage. Specifically, the supervised contrastive loss is employed to enhance the discriminative power in the feature extraction process, resulting in more effective features. In addition, we utilize the Frangi vesselness algorithm as a preprocessing step to incorporate vessel information to assist in the prediction. In the decision-level fusion stage, an evidence theory-based multi-modality classifier is employed to combine multi-source information with uncertainty estimation. Extensive experiments demonstrate that our method achieves state-of-the-art performance. The code is available at \url{https://github.com/master-Shix/ETSCL}.
PALM: Open Fundus Photograph Dataset with Pathologic Myopia Recognition and Anatomical Structure Annotation
May 13, 2023Pathologic myopia (PM) is a common blinding retinal degeneration suffered by highly myopic population. Early screening of this condition can reduce the damage caused by the associated fundus lesions and therefore prevent vision loss. Automated diagnostic tools based on artificial intelligence methods can benefit this process by aiding clinicians to identify disease signs or to screen mass populations using color fundus photographs as inputs. This paper provides insights about PALM, our open fundus imaging dataset for pathological myopia recognition and anatomical structure annotation. Our databases comprises 1200 images with associated labels for the pathologic myopia category and manual annotations of the optic disc, the position of the fovea and delineations of lesions such as patchy retinal atrophy (including peripapillary atrophy) and retinal detachment. In addition, this paper elaborates on other details such as the labeling process used to construct the database, the quality and characteristics of the samples and provides other relevant usage notes.
Medical SAM Adapter: Adapting Segment Anything Model for Medical Image Segmentation
May 11, 2023


The Segment Anything Model (SAM) has recently gained popularity in the field of image segmentation. Thanks to its impressive capabilities in all-round segmentation tasks and its prompt-based interface, SAM has sparked intensive discussion within the community. It is even said by many prestigious experts that image segmentation task has been "finished" by SAM. However, medical image segmentation, although an important branch of the image segmentation family, seems not to be included in the scope of Segmenting "Anything". Many individual experiments and recent studies have shown that SAM performs subpar in medical image segmentation. A natural question is how to find the missing piece of the puzzle to extend the strong segmentation capability of SAM to medical image segmentation. In this paper, instead of fine-tuning the SAM model, we propose Med SAM Adapter, which integrates the medical specific domain knowledge to the segmentation model, by a simple yet effective adaptation technique. Although this work is still one of a few to transfer the popular NLP technique Adapter to computer vision cases, this simple implementation shows surprisingly good performance on medical image segmentation. A medical image adapted SAM, which we have dubbed Medical SAM Adapter (MSA), shows superior performance on 19 medical image segmentation tasks with various image modalities including CT, MRI, ultrasound image, fundus image, and dermoscopic images. MSA outperforms a wide range of state-of-the-art (SOTA) medical image segmentation methods, such as nnUNet, TransUNet, UNetr, MedSegDiff, and also outperforms the fully fine-turned MedSAM with a considerable performance gap. Code will be released at: https://github.com/WuJunde/Medical-SAM-Adapter.
Multi-rater Prism: Learning self-calibrated medical image segmentation from multiple raters
Dec 01, 2022



In medical image segmentation, it is often necessary to collect opinions from multiple experts to make the final decision. This clinical routine helps to mitigate individual bias. But when data is multiply annotated, standard deep learning models are often not applicable. In this paper, we propose a novel neural network framework, called Multi-Rater Prism (MrPrism) to learn the medical image segmentation from multiple labels. Inspired by the iterative half-quadratic optimization, the proposed MrPrism will combine the multi-rater confidences assignment task and calibrated segmentation task in a recurrent manner. In this recurrent process, MrPrism can learn inter-observer variability taking into account the image semantic properties, and finally converges to a self-calibrated segmentation result reflecting the inter-observer agreement. Specifically, we propose Converging Prism (ConP) and Diverging Prism (DivP) to process the two tasks iteratively. ConP learns calibrated segmentation based on the multi-rater confidence maps estimated by DivP. DivP generates multi-rater confidence maps based on the segmentation masks estimated by ConP. The experimental results show that by recurrently running ConP and DivP, the two tasks can achieve mutual improvement. The final converged segmentation result of MrPrism outperforms state-of-the-art (SOTA) strategies on a wide range of medical image segmentation tasks.
ExpNet: A unified network for Expert-Level Classification
Nov 29, 2022



Different from the general visual classification, some classification tasks are more challenging as they need the professional categories of the images. In the paper, we call them expert-level classification. Previous fine-grained vision classification (FGVC) has made many efforts on some of its specific sub-tasks. However, they are difficult to expand to the general cases which rely on the comprehensive analysis of part-global correlation and the hierarchical features interaction. In this paper, we propose Expert Network (ExpNet) to address the unique challenges of expert-level classification through a unified network. In ExpNet, we hierarchically decouple the part and context features and individually process them using a novel attentive mechanism, called Gaze-Shift. In each stage, Gaze-Shift produces a focal-part feature for the subsequent abstraction and memorizes a context-related embedding. Then we fuse the final focal embedding with all memorized context-related embedding to make the prediction. Such an architecture realizes the dual-track processing of partial and global information and hierarchical feature interactions. We conduct the experiments over three representative expert-level classification tasks: FGVC, disease classification, and artwork attributes classification. In these experiments, superior performance of our ExpNet is observed comparing to the state-of-the-arts in a wide range of fields, indicating the effectiveness and generalization of our ExpNet. The code will be made publicly available.
MedSegDiff: Medical Image Segmentation with Diffusion Probabilistic Model
Nov 16, 2022



Diffusion probabilistic model (DPM) recently becomes one of the hottest topic in computer vision. Its image generation application such as Imagen, Latent Diffusion Models and Stable Diffusion have shown impressive generation capabilities, which aroused extensive discussion in the community. Many recent studies also found it useful in many other vision tasks, like image deblurring, super-resolution and anomaly detection. Inspired by the success of DPM, we propose the first DPM based model toward general medical image segmentation tasks, which we named MedSegDiff. In order to enhance the step-wise regional attention in DPM for the medical image segmentation, we propose dynamic conditional encoding, which establishes the state-adaptive conditions for each sampling step. We further propose Feature Frequency Parser (FF-Parser), to eliminate the negative effect of high-frequency noise component in this process. We verify MedSegDiff on three medical segmentation tasks with different image modalities, which are optic cup segmentation over fundus images, brain tumor segmentation over MRI images and thyroid nodule segmentation over ultrasound images. The experimental results show that MedSegDiff outperforms state-of-the-art (SOTA) methods with considerable performance gap, indicating the generalization and effectiveness of the proposed model.
Learning to screen Glaucoma like the ophthalmologists
Sep 23, 2022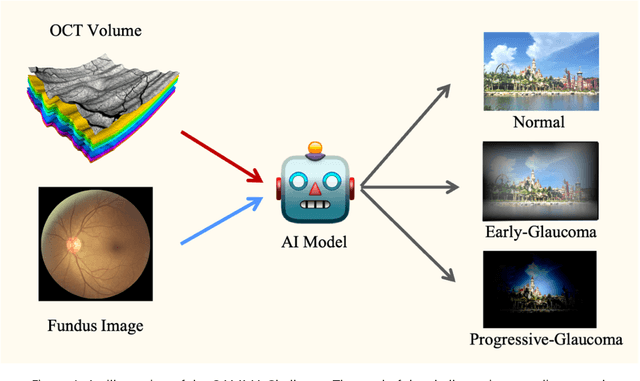
GAMMA Challenge is organized to encourage the AI models to screen the glaucoma from a combination of 2D fundus image and 3D optical coherence tomography volume, like the ophthalmologists.
Calibrate the inter-observer segmentation uncertainty via diagnosis-first principle
Aug 05, 2022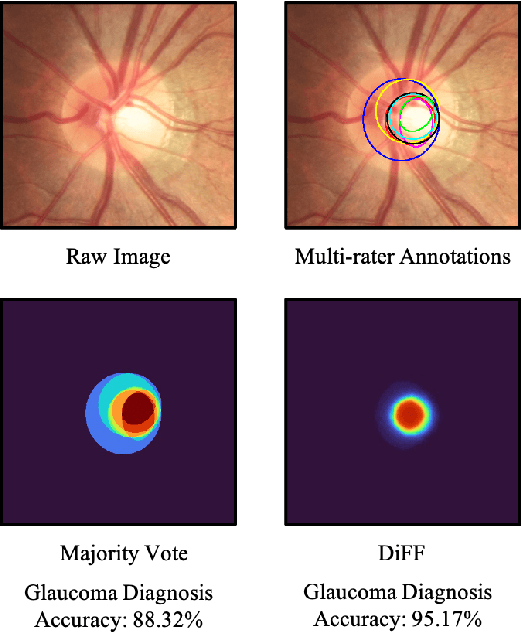
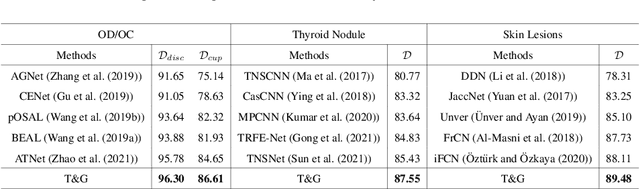
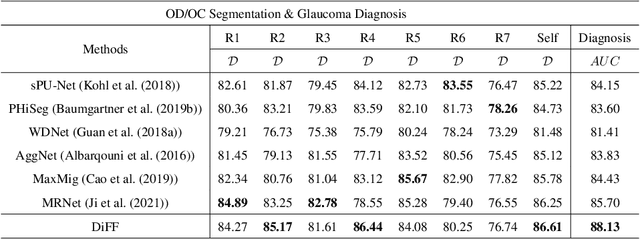
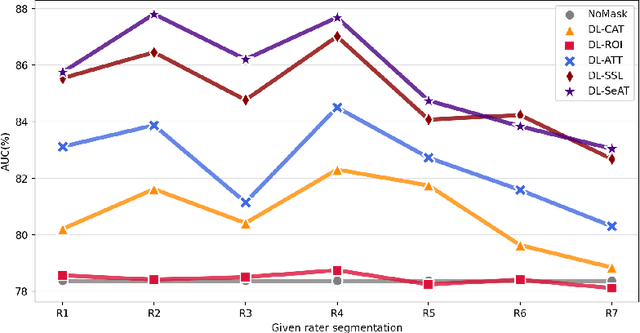
On the medical images, many of the tissues/lesions may be ambiguous. That is why the medical segmentation is typically annotated by a group of clinical experts to mitigate the personal bias. However, this clinical routine also brings new challenges to the application of machine learning algorithms. Without a definite ground-truth, it will be difficult to train and evaluate the deep learning models. When the annotations are collected from different graders, a common choice is majority vote. However such a strategy ignores the difference between the grader expertness. In this paper, we consider the task of predicting the segmentation with the calibrated inter-observer uncertainty. We note that in clinical practice, the medical image segmentation is usually used to assist the disease diagnosis. Inspired by this observation, we propose diagnosis-first principle, which is to take disease diagnosis as the criterion to calibrate the inter-observer segmentation uncertainty. Following this idea, a framework named Diagnosis First segmentation Framework (DiFF) is proposed to estimate diagnosis-first segmentation from the raw images.Specifically, DiFF will first learn to fuse the multi-rater segmentation labels to a single ground-truth which could maximize the disease diagnosis performance. We dubbed the fused ground-truth as Diagnosis First Ground-truth (DF-GT).Then, we further propose Take and Give Modelto segment DF-GT from the raw image. We verify the effectiveness of DiFF on three different medical segmentation tasks: OD/OC segmentation on fundus images, thyroid nodule segmentation on ultrasound images, and skin lesion segmentation on dermoscopic images. Experimental results show that the proposed DiFF is able to significantly facilitate the corresponding disease diagnosis, which outperforms previous state-of-the-art multi-rater learning methods.
Dataset and Evaluation algorithm design for GOALS Challenge
Jul 29, 2022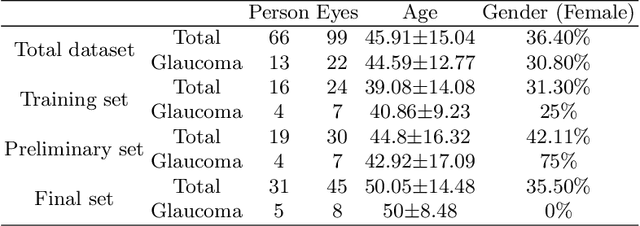
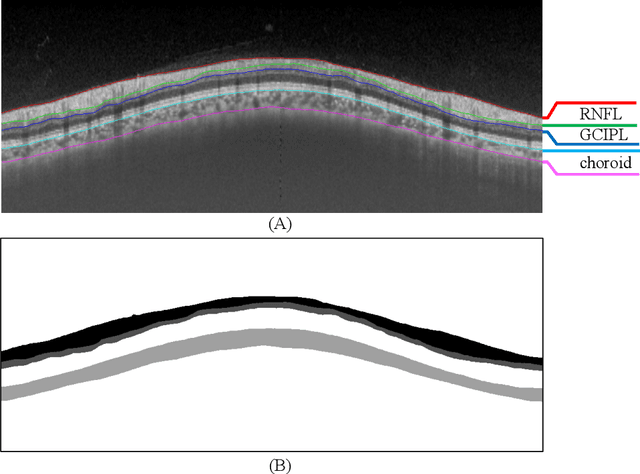
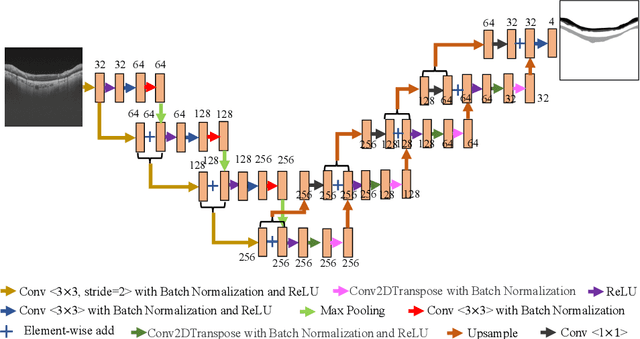
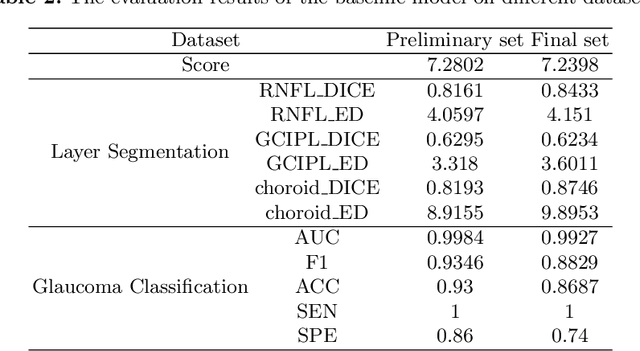
Glaucoma causes irreversible vision loss due to damage to the optic nerve, and there is no cure for glaucoma.OCT imaging modality is an essential technique for assessing glaucomatous damage since it aids in quantifying fundus structures. To promote the research of AI technology in the field of OCT-assisted diagnosis of glaucoma, we held a Glaucoma OCT Analysis and Layer Segmentation (GOALS) Challenge in conjunction with the International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI) 2022 to provide data and corresponding annotations for researchers studying layer segmentation from OCT images and the classification of glaucoma. This paper describes the released 300 circumpapillary OCT images, the baselines of the two sub-tasks, and the evaluation methodology. The GOALS Challenge is accessible at https://aistudio.baidu.com/aistudio/competition/detail/230.