 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Fundus-Specific Foundation Models for Diabetic Macular Edema Detection
Oct 08, 2025Diabetic Macular Edema (DME) is a leading cause of vision loss among patients with Diabetic Retinopathy (DR). While deep learning has shown promising results for automatically detecting this condition from fundus images, its application remains challenging due the limited availability of annotated data. Foundation Models (FM) have emerged as an alternative solution. However, it is unclear if they can cope with DME detection in particular. In this paper, we systematically compare different FM and standard transfer learning approaches for this task. Specifically, we compare the two most popular FM for retinal images--RETFound and FLAIR--and an EfficientNet-B0 backbone, across different training regimes and evaluation settings in IDRiD, MESSIDOR-2 and OCT-and-Eye-Fundus-Images (OEFI). Results show that despite their scale, FM do not consistently outperform fine-tuned CNNs in this task. In particular, an EfficientNet-B0 ranked first or second in terms of area under the ROC and precision/recall curves in most evaluation settings, with RETFound only showing promising results in OEFI. FLAIR, on the other hand, demonstrated competitive zero-shot performance, achieving notable AUC-PR scores when prompted appropriately. These findings reveal that FM might not be a good tool for fine-grained ophthalmic tasks such as DME detection even after fine-tuning, suggesting that lightweight CNNs remain strong baselines in data-scarce environments.
Learning normal asymmetry representations for homologous brain structures
Jun 27, 2023Although normal homologous brain structures are approximately symmetrical by definition, they also have shape differences due to e.g. natural ageing. On the other hand, neurodegenerative conditions induce their own changes in this asymmetry, making them more pronounced or altering their location. Identifying when these alterations are due to a pathological deterioration is still challenging. Current clinical tools rely either on subjective evaluations, basic volume measurements or disease-specific deep learning models. This paper introduces a novel method to learn normal asymmetry patterns in homologous brain structures based on anomaly detection and representation learning. Our framework uses a Siamese architecture to map 3D segmentations of left and right hemispherical sides of a brain structure to a normal asymmetry embedding space, learned using a support vector data description objective. Being trained using healthy samples only, it can quantify deviations-from-normal-asymmetry patterns in unseen samples by measuring the distance of their embeddings to the center of the learned normal space. We demonstrate in public and in-house sets that our method can accurately characterize normal asymmetries and detect pathological alterations due to Alzheimer's disease and hippocampal sclerosis, even though no diseased cases were accessed for training. Our source code is available at https://github.com/duiliod/DeepNORHA.
PALM: Open Fundus Photograph Dataset with Pathologic Myopia Recognition and Anatomical Structure Annotation
May 13, 2023Pathologic myopia (PM) is a common blinding retinal degeneration suffered by highly myopic population. Early screening of this condition can reduce the damage caused by the associated fundus lesions and therefore prevent vision loss. Automated diagnostic tools based on artificial intelligence methods can benefit this process by aiding clinicians to identify disease signs or to screen mass populations using color fundus photographs as inputs. This paper provides insights about PALM, our open fundus imaging dataset for pathological myopia recognition and anatomical structure annotation. Our databases comprises 1200 images with associated labels for the pathologic myopia category and manual annotations of the optic disc, the position of the fovea and delineations of lesions such as patchy retinal atrophy (including peripapillary atrophy) and retinal detachment. In addition, this paper elaborates on other details such as the labeling process used to construct the database, the quality and characteristics of the samples and provides other relevant usage notes.
A ResNet is All You Need? Modeling A Strong Baseline for Detecting Referable Diabetic Retinopathy in Fundus Images
Oct 06, 2022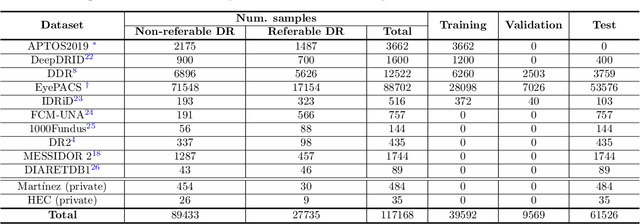

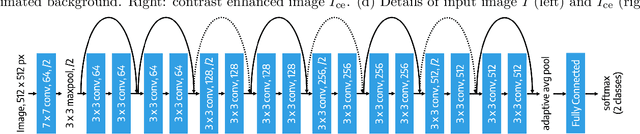
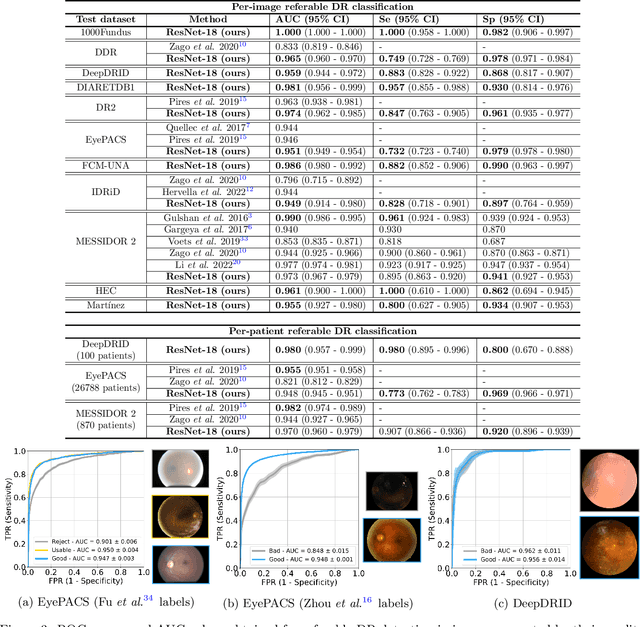
Deep learning is currently the state-of-the-art for automated detection of referable diabetic retinopathy (DR) from color fundus photographs (CFP). While the general interest is put on improving results through methodological innovations, it is not clear how good these approaches perform compared to standard deep classification models trained with the appropriate settings. In this paper we propose to model a strong baseline for this task based on a simple and standard ResNet-18 architecture. To this end, we built on top of prior art by training the model with a standard preprocessing strategy but using images from several public sources and an empirically calibrated data augmentation setting. To evaluate its performance, we covered multiple clinically relevant perspectives, including image and patient level DR screening, discriminating responses by input quality and DR grade, assessing model uncertainties and analyzing its results in a qualitative manner. With no other methodological innovation than a carefully designed training, our ResNet model achieved an AUC = 0.955 (0.953 - 0.956) on a combined test set of 61007 test images from different public datasets, which is in line or even better than what other more complex deep learning models reported in the literature. Similar AUC values were obtained in 480 images from two separate in-house databases specially prepared for this study, which emphasize its generalization ability. This confirms that standard networks can still be strong baselines for this task if properly trained.
A deep learning model for brain vessel segmentation in 3DRA with arteriovenous malformations
Oct 05, 2022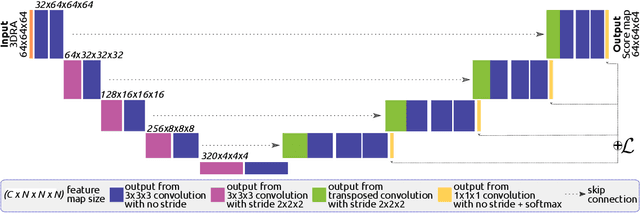
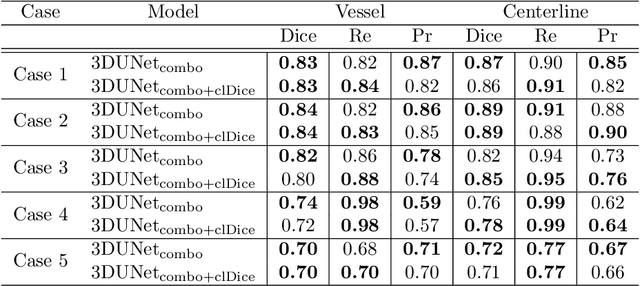
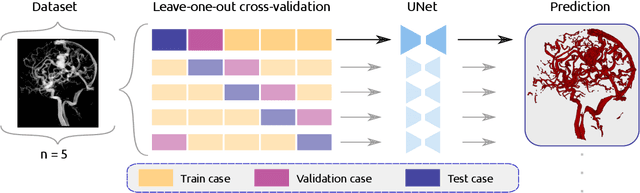

Segmentation of brain arterio-venous malformations (bAVMs) in 3D rotational angiographies (3DRA) is still an open problem in the literature, with high relevance for clinical practice. While deep learning models have been applied for segmenting the brain vasculature in these images, they have never been used in cases with bAVMs. This is likely caused by the difficulty to obtain sufficiently annotated data to train these approaches. In this paper we introduce a first deep learning model for blood vessel segmentation in 3DRA images of patients with bAVMs. To this end, we densely annotated 5 3DRA volumes of bAVM cases and used these to train two alternative 3DUNet-based architectures with different segmentation objectives. Our results show that the networks reach a comprehensive coverage of relevant structures for bAVM analysis, much better than what is obtained using standard methods. This is promising for achieving a better topological and morphological characterisation of the bAVM structures of interest. Furthermore, the models have the ability to segment venous structures even when missing in the ground truth labelling, which is relevant for planning interventional treatments. Ultimately, these results could be used as more reliable first initial guesses, alleviating the cumbersome task of creating manual labels.
Assessing Coarse-to-Fine Deep Learning Models for Optic Disc and Cup Segmentation in Fundus Images
Sep 28, 2022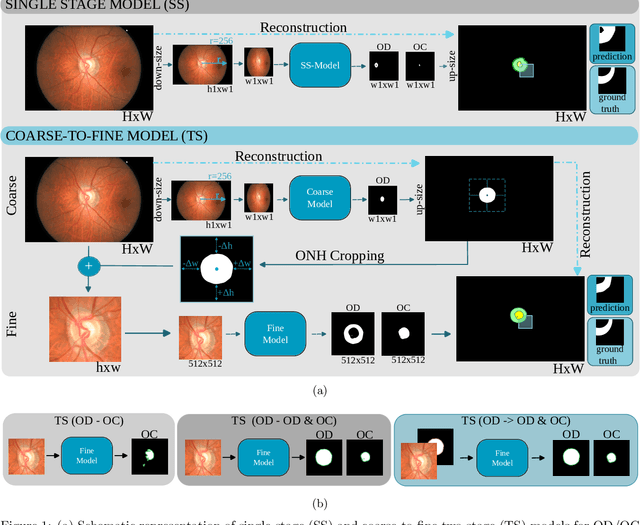
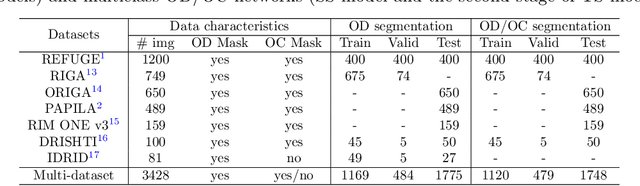
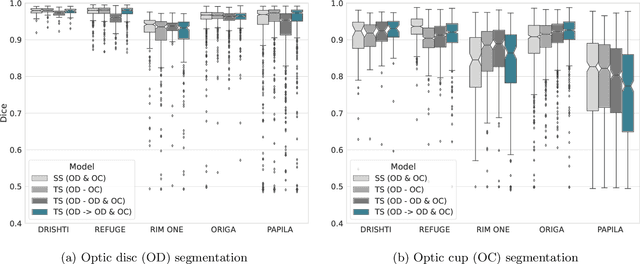
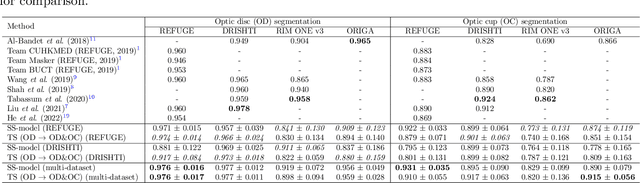
Automated optic disc (OD) and optic cup (OC) segmentation in fundus images is relevant to efficiently measure the vertical cup-to-disc ratio (vCDR), a biomarker commonly used in ophthalmology to determine the degree of glaucomatous optic neuropathy. In general this is solved using coarse-to-fine deep learning algorithms in which a first stage approximates the OD and a second one uses a crop of this area to predict OD/OC masks. While this approach is widely applied in the literature, there are no studies analyzing its real contribution to the results. In this paper we present a comprehensive analysis of different coarse-to-fine designs for OD/OC segmentation using 5 public databases, both from a standard segmentation perspective and for estimating the vCDR for glaucoma assessment. Our analysis shows that these algorithms not necessarily outperfom standard multi-class single-stage models, especially when these are learned from sufficiently large and diverse training sets. Furthermore, we noticed that the coarse stage achieves better OD segmentation results than the fine one, and that providing OD supervision to the second stage is essential to ensure accurate OC masks. Moreover, both the single-stage and two-stage models trained on a multi-dataset setting showed results in pair or even better than other state-of-the-art alternatives, while ranking first in REFUGE for OD/OC segmentation. Finally, we evaluated the models for vCDR prediction in comparison with six ophthalmologists on a subset of AIROGS images, to understand them in the context of inter-observer variability. We noticed that vCDR estimates recovered both from single-stage and coarse-to-fine models can obtain good glaucoma detection results even when they are not highly correlated with manual measurements from experts.
REFUGE2 Challenge: Treasure for Multi-Domain Learning in Glaucoma Assessment
Feb 24, 2022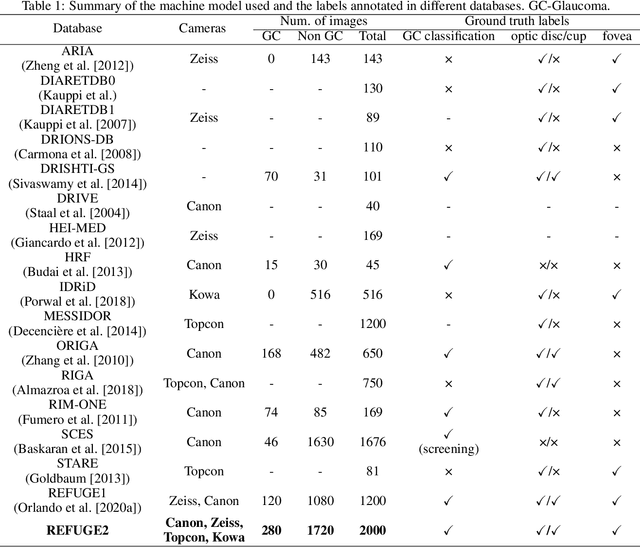
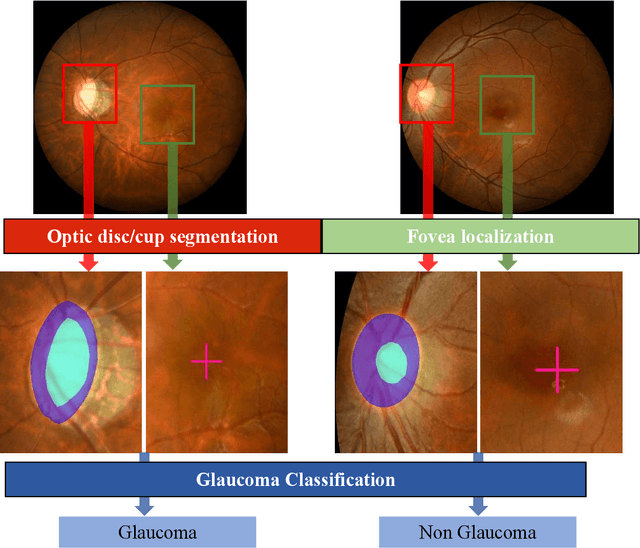
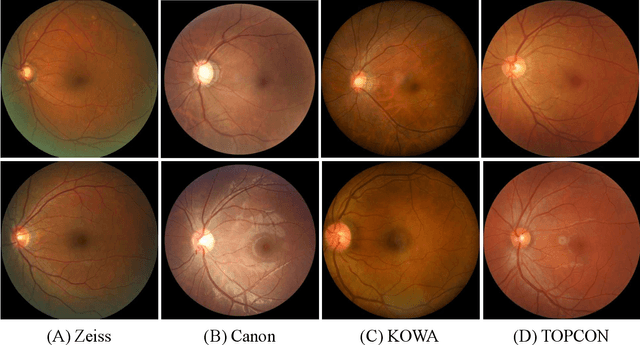
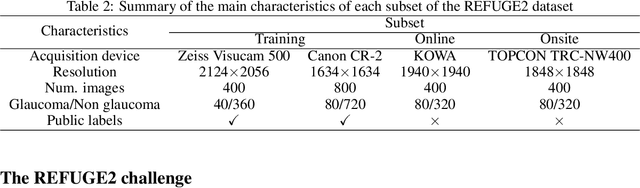
Glaucoma is the second leading cause of blindness and is the leading cause of irreversible blindness disease in the world. Early screening for glaucoma in the population is significant. Color fundus photography is the most cost effective imaging modality to screen for ocular diseases. Deep learning network is often used in color fundus image analysis due to its powful feature extraction capability. However, the model training of deep learning method needs a large amount of data, and the distribution of data should be abundant for the robustness of model performance. To promote the research of deep learning in color fundus photography and help researchers further explore the clinical application signification of AI technology, we held a REFUGE2 challenge. This challenge released 2,000 color fundus images of four models, including Zeiss, Canon, Kowa and Topcon, which can validate the stabilization and generalization of algorithms on multi-domain. Moreover, three sub-tasks were designed in the challenge, including glaucoma classification, cup/optic disc segmentation, and macular fovea localization. These sub-tasks technically cover the three main problems of computer vision and clinicly cover the main researchs of glaucoma diagnosis. Over 1,300 international competitors joined the REFUGE2 challenge, 134 teams submitted more than 3,000 valid preliminary results, and 22 teams reached the final. This article summarizes the methods of some of the finalists and analyzes their results. In particular, we observed that the teams using domain adaptation strategies had high and robust performance on the dataset with multi-domain. This indicates that UDA and other multi-domain related researches will be the trend of deep learning field in the future, and our REFUGE2 datasets will play an important role in these researches.
ADAM Challenge: Detecting Age-related Macular Degeneration from Fundus Images
Feb 18, 2022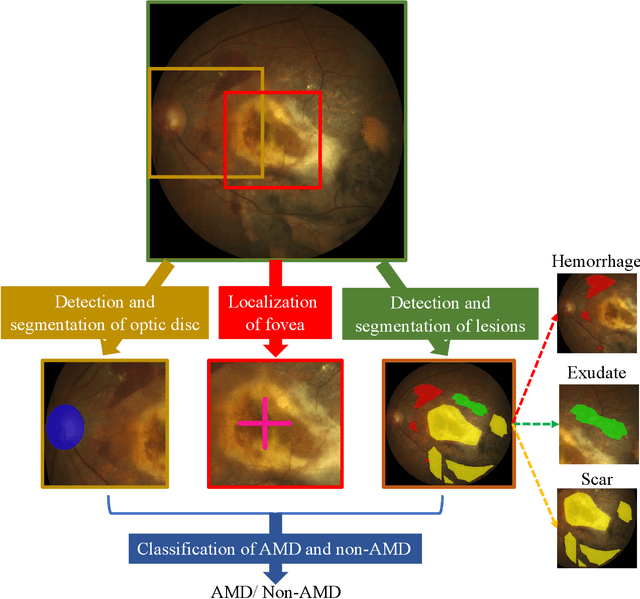

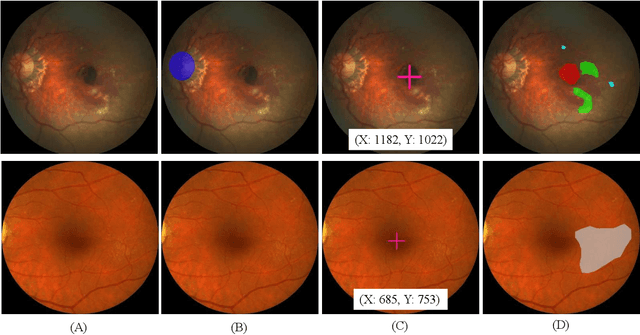
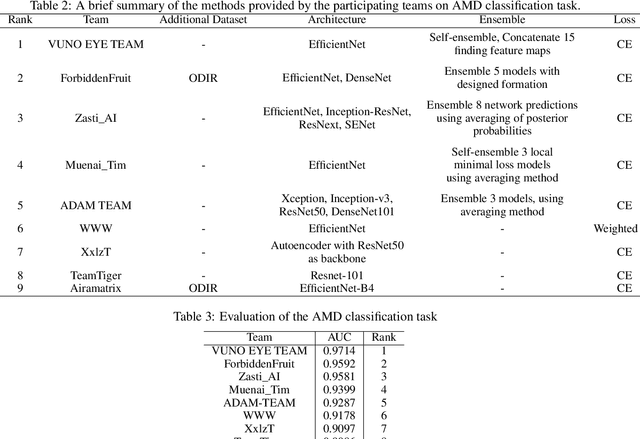
Age-related macular degeneration (AMD) is the leading cause of visual impairment among elderly in the world. Early detection of AMD is of great importance as the vision loss caused by AMD is irreversible and permanent. Color fundus photography is the most cost-effective imaging modality to screen for retinal disorders. \textcolor{red}{Recently, some algorithms based on deep learning had been developed for fundus image analysis and automatic AMD detection. However, a comprehensive annotated dataset and a standard evaluation benchmark are still missing.} To deal with this issue, we set up the Automatic Detection challenge on Age-related Macular degeneration (ADAM) for the first time, held as a satellite event of the ISBI 2020 conference. The ADAM challenge consisted of four tasks which cover the main topics in detecting AMD from fundus images, including classification of AMD, detection and segmentation of optic disc, localization of fovea, and detection and segmentation of lesions. The ADAM challenge has released a comprehensive dataset of 1200 fundus images with the category labels of AMD, the pixel-wise segmentation masks of the full optic disc and lesions (drusen, exudate, hemorrhage, scar, and other), as well as the location coordinates of the macular fovea. A uniform evaluation framework has been built to make a fair comparison of different models. During the ADAM challenge, 610 results were submitted for online evaluation, and finally, 11 teams participated in the onsite challenge. This paper introduces the challenge, dataset, and evaluation methods, as well as summarizes the methods and analyzes the results of the participating teams of each task. In particular, we observed that ensembling strategy and clinical prior knowledge can better improve the performances of the deep learning models.
GAMMA Challenge:Glaucoma grAding from Multi-Modality imAges
Feb 16, 2022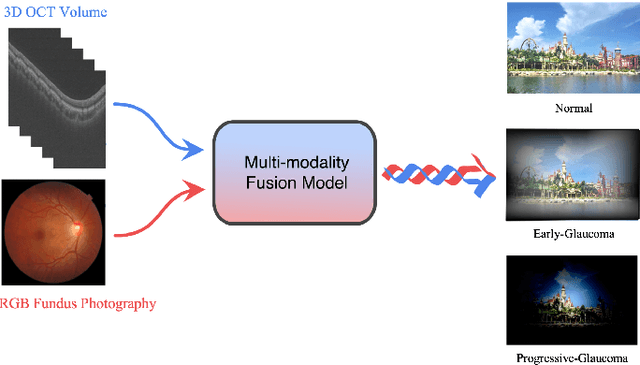
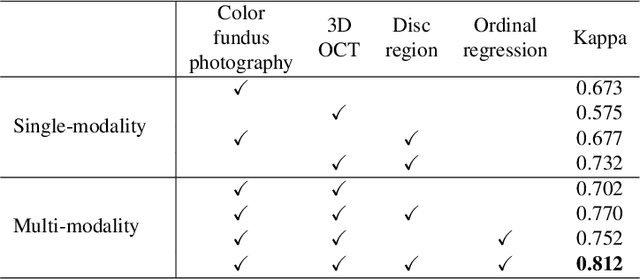
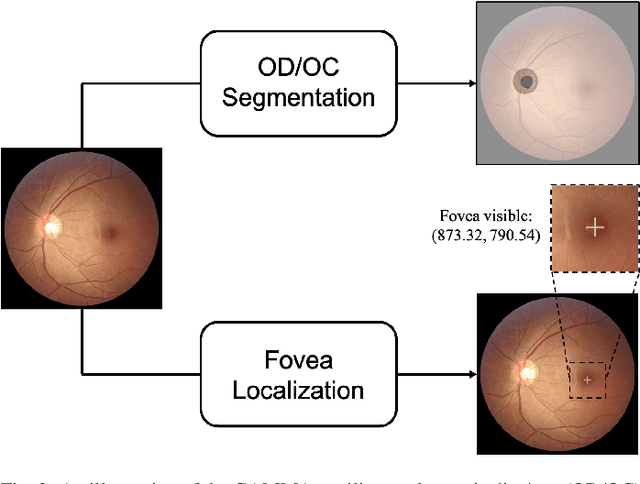
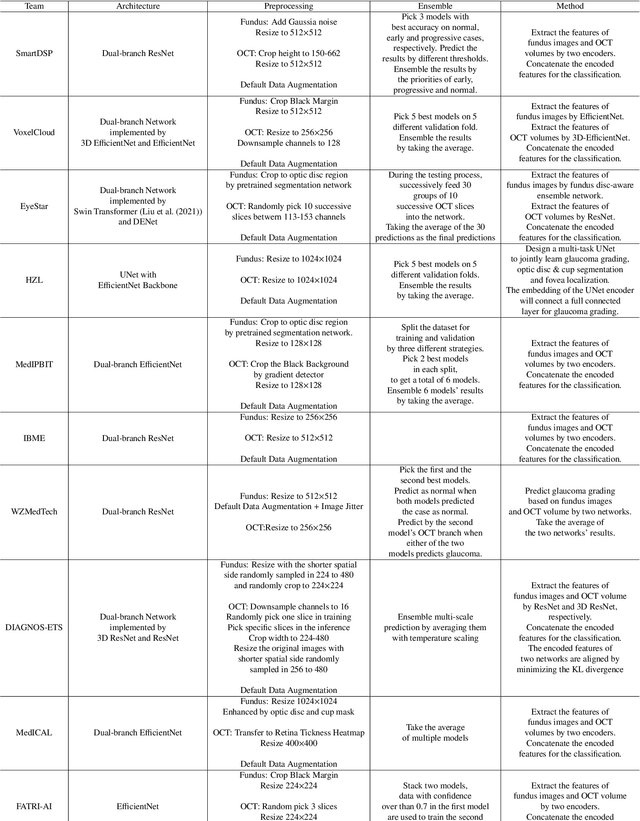
Color fundus photography and Optical Coherence Tomography (OCT) are the two most cost-effective tools for glaucoma screening. Both two modalities of images have prominent biomarkers to indicate glaucoma suspected. Clinically, it is often recommended to take both of the screenings for a more accurate and reliable diagnosis. However, although numerous algorithms are proposed based on fundus images or OCT volumes in computer-aided diagnosis, there are still few methods leveraging both of the modalities for the glaucoma assessment. Inspired by the success of Retinal Fundus Glaucoma Challenge (REFUGE) we held previously, we set up the Glaucoma grAding from Multi-Modality imAges (GAMMA) Challenge to encourage the development of fundus \& OCT-based glaucoma grading. The primary task of the challenge is to grade glaucoma from both the 2D fundus images and 3D OCT scanning volumes. As part of GAMMA, we have publicly released a glaucoma annotated dataset with both 2D fundus color photography and 3D OCT volumes, which is the first multi-modality dataset for glaucoma grading. In addition, an evaluation framework is also established to evaluate the performance of the submitted methods. During the challenge, 1272 results were submitted, and finally, top-10 teams were selected to the final stage. We analysis their results and summarize their methods in the paper. Since all these teams submitted their source code in the challenge, a detailed ablation study is also conducted to verify the effectiveness of the particular modules proposed. We find many of the proposed techniques are practical for the clinical diagnosis of glaucoma. As the first in-depth study of fundus \& OCT multi-modality glaucoma grading, we believe the GAMMA Challenge will be an essential starting point for future research.
SketchZooms: Deep multi-view descriptors for matching line drawings
Nov 29, 2019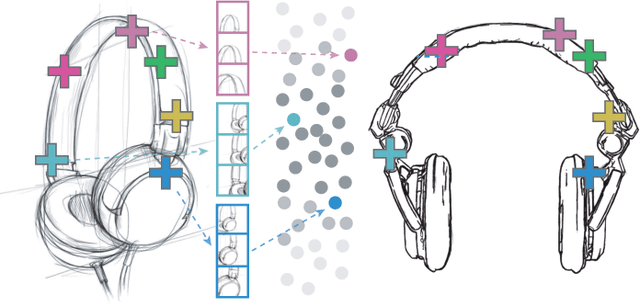
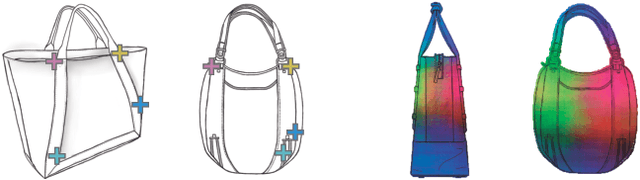
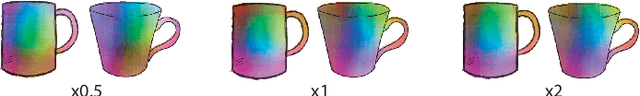
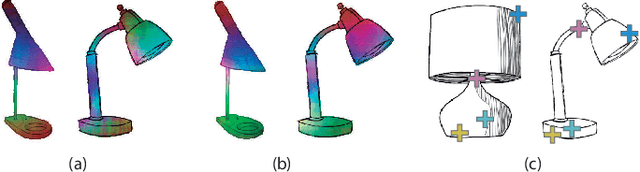
Finding point-wise correspondences between images is a long-standing problem in computer vision. Corresponding sketch images is particularly challenging due to the varying nature of human style, projection distortions and viewport changes. In this paper we present a feature descriptor targeting line drawings learned from a 3D shape data set. Our descriptors are designed to locally match image pairs where the object of interest belongs to the same semantic category, yet still differ drastically in shape and projection angle. We build our descriptors by means of a Convolutional Neural Network (CNN) trained in a triplet fashion. The goal is to embed semantically similar anchor points close to one another, and to pull the embeddings of different points far apart. To learn the descriptors space, the network is fed with a succession of zoomed views from the input sketches. We have specifically crafted a data set of synthetic sketches using a non-photorealistic rendering algorithm over a large collection of part-based registered 3D models. Once trained, our network can generate descriptors for every pixel in an input image. Furthermore, our network is able to generalize well to unseen sketches hand-drawn by humans, outperforming state-of-the-art descriptors on the evaluated matching tasks. Our descriptors can be used to obtain sparse and dense correspondences between image pairs. We evaluate our method against a baseline of correspondences data collected from expert designers, in addition to comparisons with descriptors that have been proven effective in sketches. Finally, we demonstrate applications showing the usefulness of our multi-view descriptors.