 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFP8-RL: A Practical and Stable Low-Precision Stack for LLM Reinforcement Learning
Jan 26, 2026Reinforcement learning (RL) for large language models (LLMs) is increasingly bottlenecked by rollout (generation), where long output sequence lengths make attention and KV-cache memory dominate end-to-end step time. FP8 offers an attractive lever for accelerating RL by reducing compute cost and memory traffic during rollout, but applying FP8 in RL introduces unique engineering and algorithmic challenges: policy weights change every step (requiring repeated quantization and weight synchronization into the inference engine) and low-precision rollouts can deviate from the higher-precision policy assumed by the trainer, causing train-inference mismatch and potential instability. This report presents a practical FP8 rollout stack for LLM RL, implemented in the veRL ecosystem with support for common training backends (e.g., FSDP/Megatron-LM) and inference engines (e.g., vLLM/SGLang). We (i) enable FP8 W8A8 linear-layer rollout using blockwise FP8 quantization, (ii) extend FP8 to KV-cache to remove long-context memory bottlenecks via per-step QKV scale recalibration, and (iii) mitigate mismatch using importance-sampling-based rollout correction (token-level TIS/MIS variants). Across dense and MoE models, these techniques deliver up to 44% rollout throughput gains while preserving learning behavior comparable to BF16 baselines.
Toward the Automated Construction of Probabilistic Knowledge Graphs for the Maritime Domain
May 04, 2023



International maritime crime is becoming increasingly sophisticated, often associated with wider criminal networks. Detecting maritime threats by means of fusing data purely related to physical movement (i.e., those generated by physical sensors, or hard data) is not sufficient. This has led to research and development efforts aimed at combining hard data with other types of data (especially human-generated or soft data). Existing work often assumes that input soft data is available in a structured format, or is focused on extracting certain relevant entities or concepts to accompany or annotate hard data. Much less attention has been given to extracting the rich knowledge about the situations of interest implicitly embedded in the large amount of soft data existing in unstructured formats (such as intelligence reports and news articles). In order to exploit the potentially useful and rich information from such sources, it is necessary to extract not only the relevant entities and concepts but also their semantic relations, together with the uncertainty associated with the extracted knowledge (i.e., in the form of probabilistic knowledge graphs). This will increase the accuracy of and confidence in, the extracted knowledge and facilitate subsequent reasoning and learning. To this end, we propose Maritime DeepDive, an initial prototype for the automated construction of probabilistic knowledge graphs from natural language data for the maritime domain. In this paper, we report on the current implementation of Maritime DeepDive, together with preliminary results on extracting probabilistic events from maritime piracy incidents. This pipeline was evaluated on a manually crafted gold standard, yielding promising results.
Domain Adaptation Meets Zero-Shot Learning: An Annotation-Efficient Approach to Multi-Modality Medical Image Segmentation
Mar 19, 2022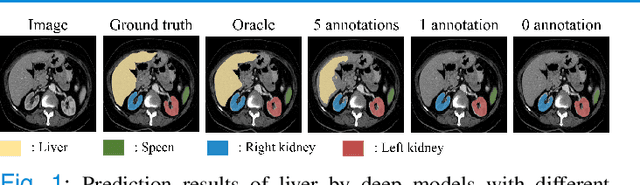
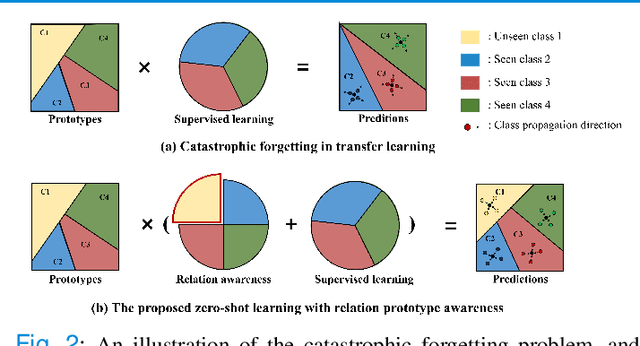
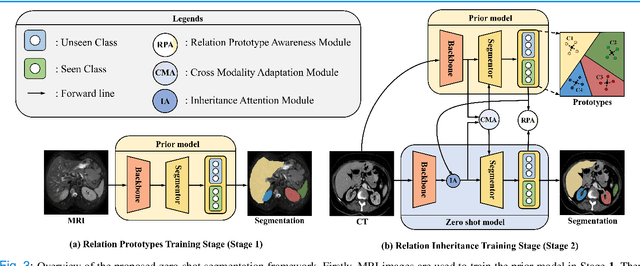
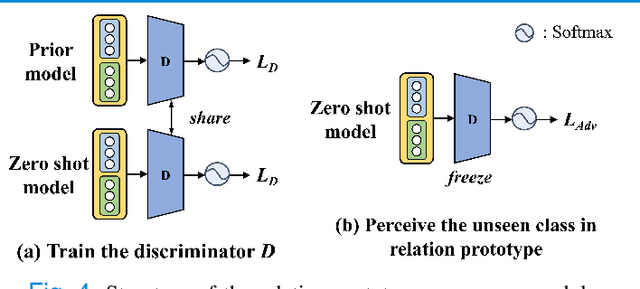
Due to the lack of properly annotated medical data, exploring the generalization capability of the deep model is becoming a public concern. Zero-shot learning (ZSL) has emerged in recent years to equip the deep model with the ability to recognize unseen classes. However, existing studies mainly focus on natural images, which utilize linguistic models to extract auxiliary information for ZSL. It is impractical to apply the natural image ZSL solutions directly to medical images, since the medical terminology is very domain-specific, and it is not easy to acquire linguistic models for the medical terminology. In this work, we propose a new paradigm of ZSL specifically for medical images utilizing cross-modality information. We make three main contributions with the proposed paradigm. First, we extract the prior knowledge about the segmentation targets, called relation prototypes, from the prior model and then propose a cross-modality adaptation module to inherit the prototypes to the zero-shot model. Second, we propose a relation prototype awareness module to make the zero-shot model aware of information contained in the prototypes. Last but not least, we develop an inheritance attention module to recalibrate the relation prototypes to enhance the inheritance process. The proposed framework is evaluated on two public cross-modality datasets including a cardiac dataset and an abdominal dataset. Extensive experiments show that the proposed framework significantly outperforms the state of the arts.
REFUGE2 Challenge: Treasure for Multi-Domain Learning in Glaucoma Assessment
Feb 24, 2022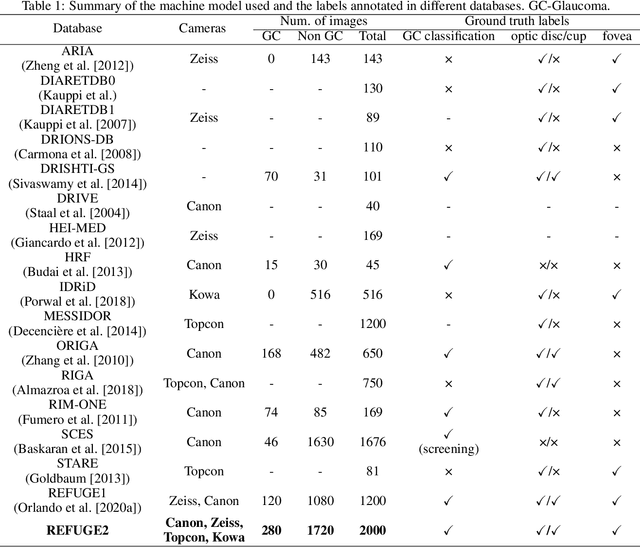
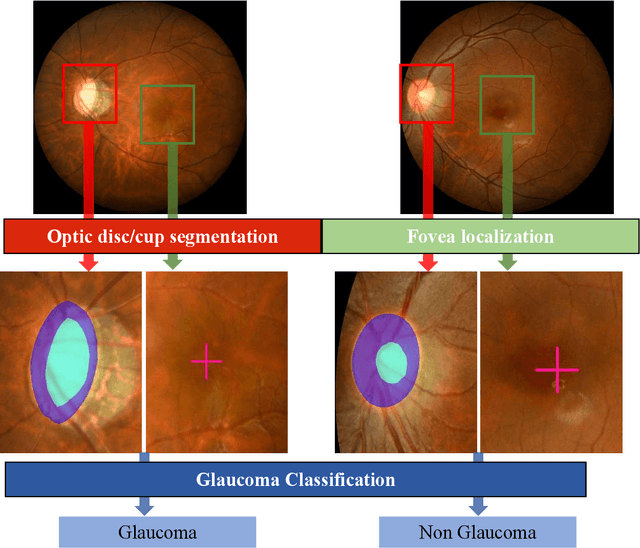
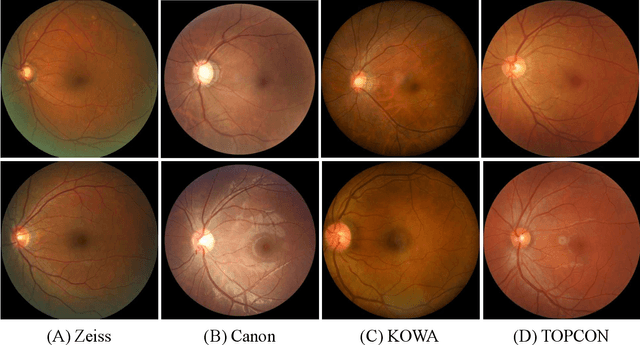
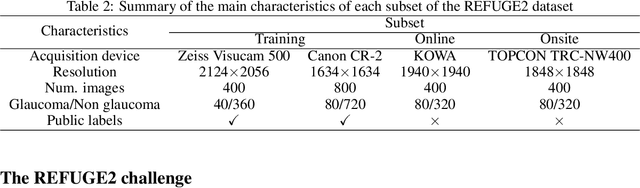
Glaucoma is the second leading cause of blindness and is the leading cause of irreversible blindness disease in the world. Early screening for glaucoma in the population is significant. Color fundus photography is the most cost effective imaging modality to screen for ocular diseases. Deep learning network is often used in color fundus image analysis due to its powful feature extraction capability. However, the model training of deep learning method needs a large amount of data, and the distribution of data should be abundant for the robustness of model performance. To promote the research of deep learning in color fundus photography and help researchers further explore the clinical application signification of AI technology, we held a REFUGE2 challenge. This challenge released 2,000 color fundus images of four models, including Zeiss, Canon, Kowa and Topcon, which can validate the stabilization and generalization of algorithms on multi-domain. Moreover, three sub-tasks were designed in the challenge, including glaucoma classification, cup/optic disc segmentation, and macular fovea localization. These sub-tasks technically cover the three main problems of computer vision and clinicly cover the main researchs of glaucoma diagnosis. Over 1,300 international competitors joined the REFUGE2 challenge, 134 teams submitted more than 3,000 valid preliminary results, and 22 teams reached the final. This article summarizes the methods of some of the finalists and analyzes their results. In particular, we observed that the teams using domain adaptation strategies had high and robust performance on the dataset with multi-domain. This indicates that UDA and other multi-domain related researches will be the trend of deep learning field in the future, and our REFUGE2 datasets will play an important role in these researches.
Multi-Anchor Active Domain Adaptation for Semantic Segmentation
Aug 18, 2021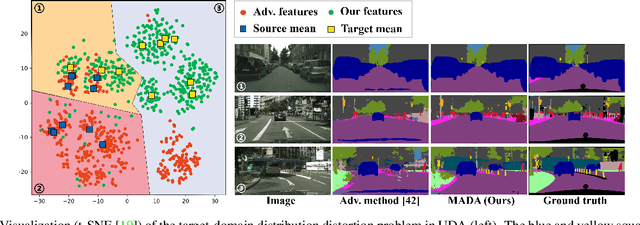
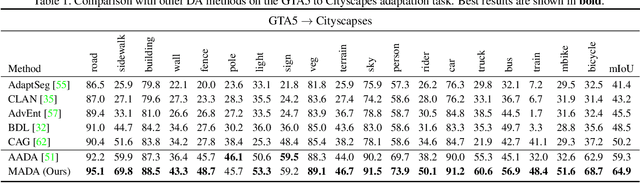
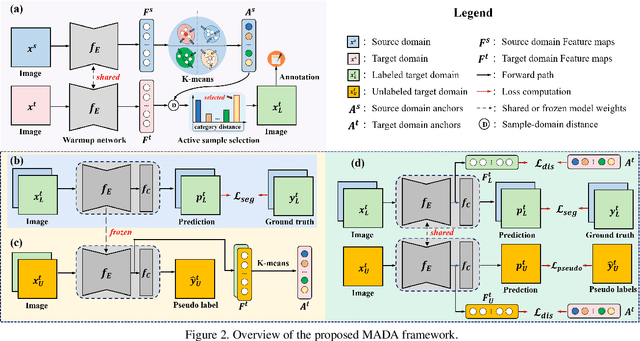
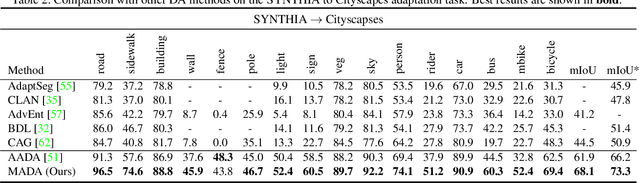
Unsupervised domain adaption has proven to be an effective approach for alleviating the intensive workload of manual annotation by aligning the synthetic source-domain data and the real-world target-domain samples. Unfortunately, mapping the target-domain distribution to the source-domain unconditionally may distort the essential structural information of the target-domain data. To this end, we firstly propose to introduce a novel multi-anchor based active learning strategy to assist domain adaptation regarding the semantic segmentation task. By innovatively adopting multiple anchors instead of a single centroid, the source domain can be better characterized as a multimodal distribution, thus more representative and complimentary samples are selected from the target domain. With little workload to manually annotate these active samples, the distortion of the target-domain distribution can be effectively alleviated, resulting in a large performance gain. The multi-anchor strategy is additionally employed to model the target-distribution. By regularizing the latent representation of the target samples compact around multiple anchors through a novel soft alignment loss, more precise segmentation can be achieved. Extensive experiments are conducted on public datasets to demonstrate that the proposed approach outperforms state-of-the-art methods significantly, along with thorough ablation study to verify the effectiveness of each component.
TR-GAN: Topology Ranking GAN with Triplet Loss for Retinal Artery/Vein Classification
Jul 29, 2020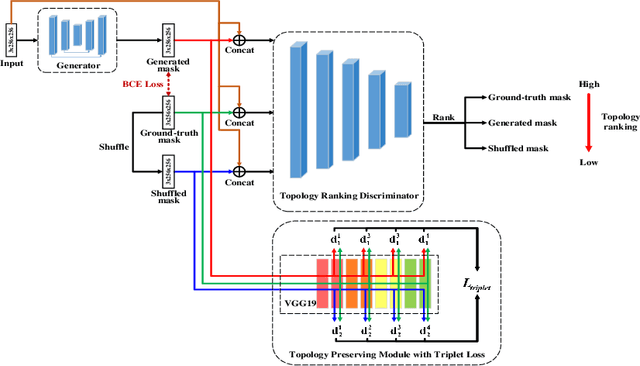
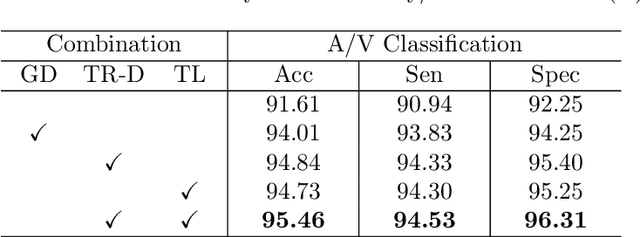
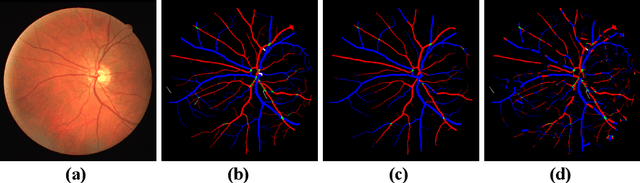
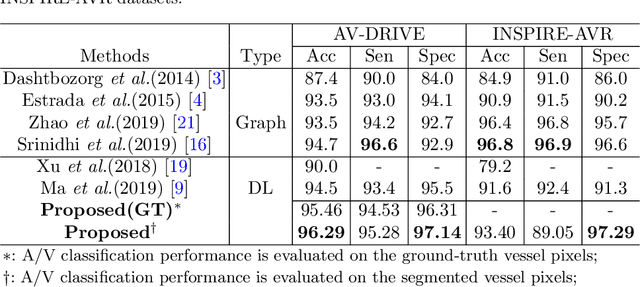
Retinal artery/vein (A/V) classification lays the foundation for the quantitative analysis of retinal vessels, which is associated with potential risks of various cardiovascular and cerebral diseases. The topological connection relationship, which has been proved effective in improving the A/V classification performance for the conventional graph based method, has not been exploited by the deep learning based method. In this paper, we propose a Topology Ranking Generative Adversarial Network (TR-GAN) to improve the topology connectivity of the segmented arteries and veins, and further to boost the A/V classification performance. A topology ranking discriminator based on ordinal regression is proposed to rank the topological connectivity level of the ground-truth, the generated A/V mask and the intentionally shuffled mask. The ranking loss is further back-propagated to the generator to generate better connected A/V masks. In addition, a topology preserving module with triplet loss is also proposed to extract the high-level topological features and further to narrow the feature distance between the predicted A/V mask and the ground-truth. The proposed framework effectively increases the topological connectivity of the predicted A/V masks and achieves state-of-the-art A/V classification performance on the publicly available AV-DRIVE dataset.
Difficulty-aware Glaucoma Classification with Multi-Rater Consensus Modeling
Jul 29, 2020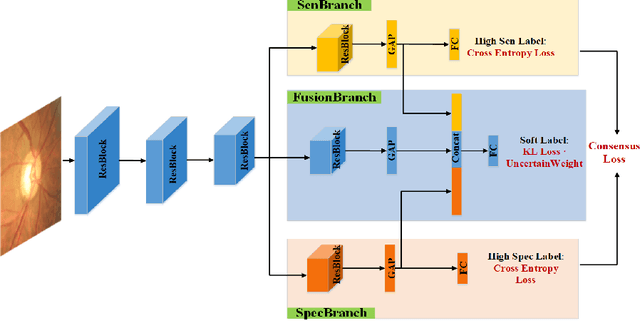
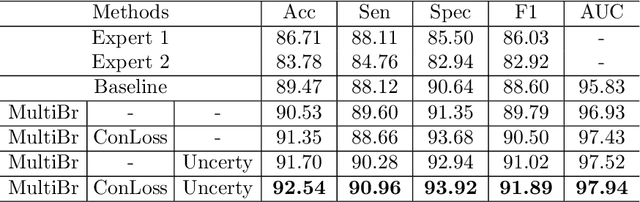
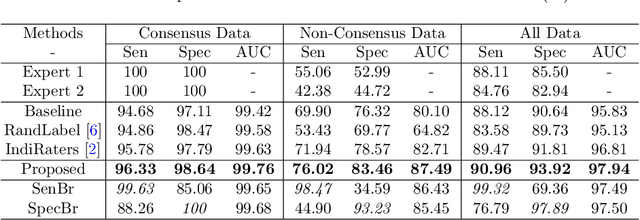
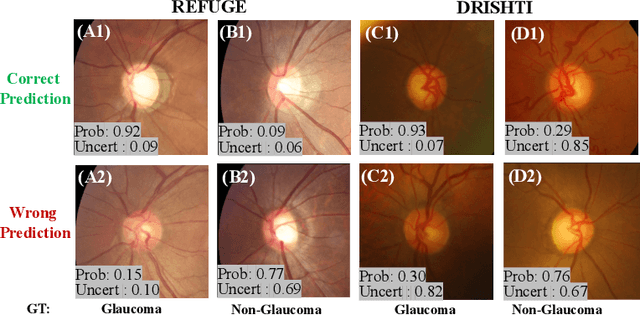
Medical images are generally labeled by multiple experts before the final ground-truth labels are determined. Consensus or disagreement among experts regarding individual images reflects the gradeability and difficulty levels of the image. However, when being used for model training, only the final ground-truth label is utilized, while the critical information contained in the raw multi-rater gradings regarding the image being an easy/hard case is discarded. In this paper, we aim to take advantage of the raw multi-rater gradings to improve the deep learning model performance for the glaucoma classification task. Specifically, a multi-branch model structure is proposed to predict the most sensitive, most specifical and a balanced fused result for the input images. In order to encourage the sensitivity branch and specificity branch to generate consistent results for consensus labels and opposite results for disagreement labels, a consensus loss is proposed to constrain the output of the two branches. Meanwhile, the consistency/inconsistency between the prediction results of the two branches implies the image being an easy/hard case, which is further utilized to encourage the balanced fusion branch to concentrate more on the hard cases. Compared with models trained only with the final ground-truth labels, the proposed method using multi-rater consensus information has achieved superior performance, and it is also able to estimate the difficulty levels of individual input images when making the prediction.
Leveraging Undiagnosed Data for Glaucoma Classification with Teacher-Student Learning
Jul 22, 2020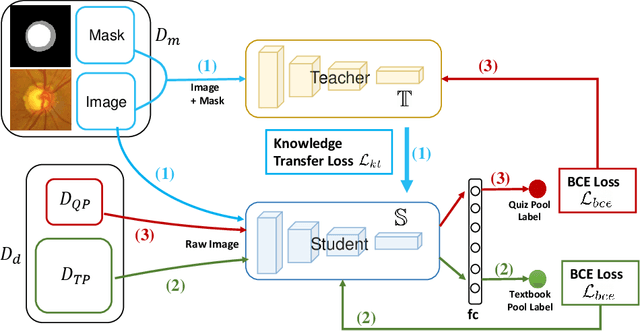
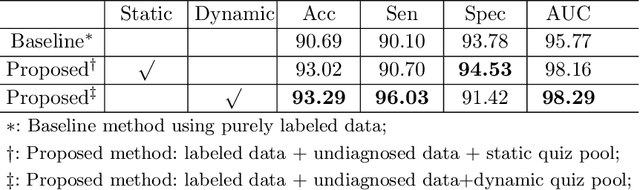
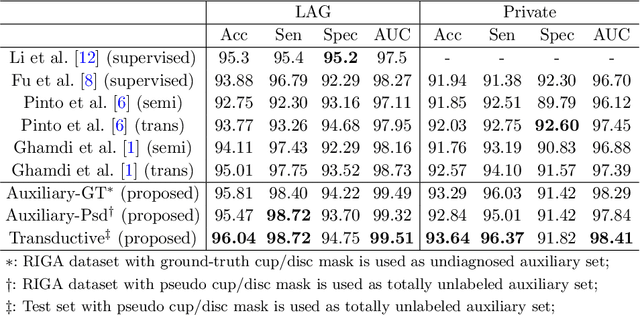
Recently, deep learning has been adopted to the glaucoma classification task with performance comparable to that of human experts. However, a well trained deep learning model demands a large quantity of properly labeled data, which is relatively expensive since the accurate labeling of glaucoma requires years of specialist training. In order to alleviate this problem, we propose a glaucoma classification framework which takes advantage of not only the properly labeled images, but also undiagnosed images without glaucoma labels. To be more specific, the proposed framework is adapted from the teacher-student-learning paradigm. The teacher model encodes the wrapped information of undiagnosed images to a latent feature space, meanwhile the student model learns from the teacher through knowledge transfer to improve the glaucoma classification. For the model training procedure, we propose a novel training strategy that simulates the real-world teaching practice named as 'Learning To Teach with Knowledge Transfer (L2T-KT)', and establish a 'Quiz Pool' as the teacher's optimization target. Experiments show that the proposed framework is able to utilize the undiagnosed data effectively to improve the glaucoma prediction performance.
Comparing to Learn: Surpassing ImageNet Pretraining on Radiographs By Comparing Image Representations
Jul 22, 2020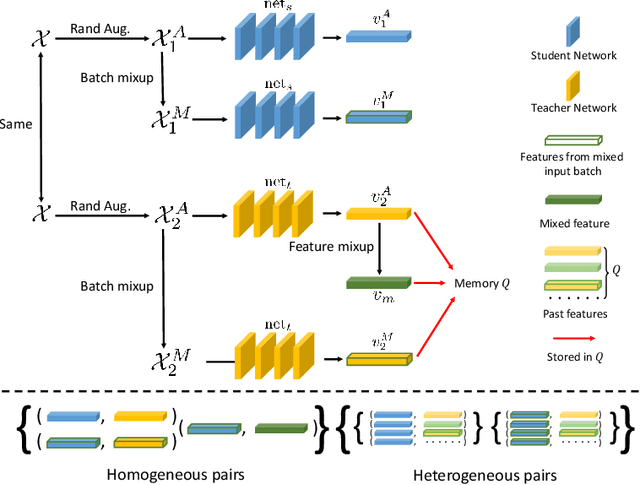


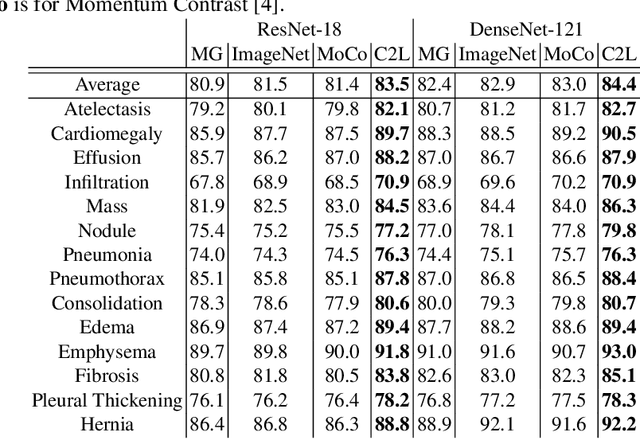
In deep learning era, pretrained models play an important role in medical image analysis, in which ImageNet pretraining has been widely adopted as the best way. However, it is undeniable that there exists an obvious domain gap between natural images and medical images. To bridge this gap, we propose a new pretraining method which learns from 700k radiographs given no manual annotations. We call our method as Comparing to Learn (C2L) because it learns robust features by comparing different image representations. To verify the effectiveness of C2L, we conduct comprehensive ablation studies and evaluate it on different tasks and datasets. The experimental results on radiographs show that C2L can outperform ImageNet pretraining and previous state-of-the-art approaches significantly. Code and models are available.
A Macro-Micro Weakly-supervised Framework for AS-OCT Tissue Segmentation
Jul 20, 2020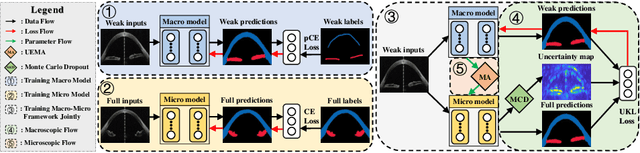
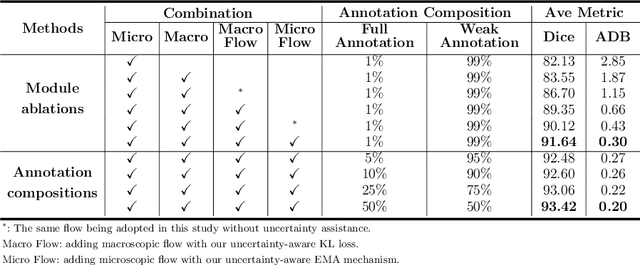
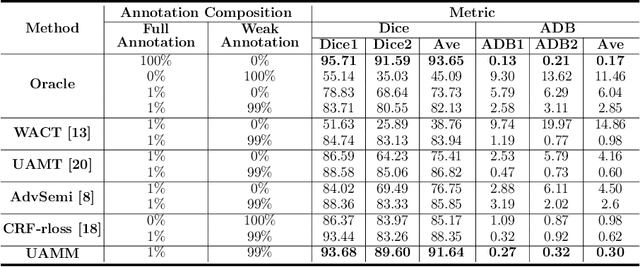
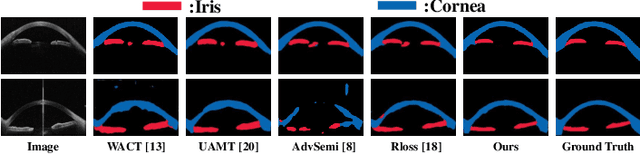
Primary angle closure glaucoma (PACG) is the leading cause of irreversible blindness among Asian people. Early detection of PACG is essential, so as to provide timely treatment and minimize the vision loss. In the clinical practice, PACG is diagnosed by analyzing the angle between the cornea and iris with anterior segment optical coherence tomography (AS-OCT). The rapid development of deep learning technologies provides the feasibility of building a computer-aided system for the fast and accurate segmentation of cornea and iris tissues. However, the application of deep learning methods in the medical imaging field is still restricted by the lack of enough fully-annotated samples. In this paper, we propose a novel framework to segment the target tissues accurately for the AS-OCT images, by using the combination of weakly-annotated images (majority) and fully-annotated images (minority). The proposed framework consists of two models which provide reliable guidance for each other. In addition, uncertainty guided strategies are adopted to increase the accuracy and stability of the guidance. Detailed experiments on the publicly available AGE dataset demonstrate that the proposed framework outperforms the state-of-the-art semi-/weakly-supervised methods and has a comparable performance as the fully-supervised method. Therefore, the proposed method is demonstrated to be effective in exploiting information contained in the weakly-annotated images and has the capability to substantively relieve the annotation workload.