 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparseAD: Sparse Query-Centric Paradigm for Efficient End-to-End Autonomous Driving
Apr 10, 2024



End-to-End paradigms use a unified framework to implement multi-tasks in an autonomous driving system. Despite simplicity and clarity, the performance of end-to-end autonomous driving methods on sub-tasks is still far behind the single-task methods. Meanwhile, the widely used dense BEV features in previous end-to-end methods make it costly to extend to more modalities or tasks. In this paper, we propose a Sparse query-centric paradigm for end-to-end Autonomous Driving (SparseAD), where the sparse queries completely represent the whole driving scenario across space, time and tasks without any dense BEV representation. Concretely, we design a unified sparse architecture for perception tasks including detection, tracking, and online mapping. Moreover, we revisit motion prediction and planning, and devise a more justifiable motion planner framework. On the challenging nuScenes dataset, SparseAD achieves SOTA full-task performance among end-to-end methods and significantly narrows the performance gap between end-to-end paradigms and single-task methods. Codes will be released soon.
A Fast and Lightweight Network for Low-Light Image Enhancement
Apr 06, 2023
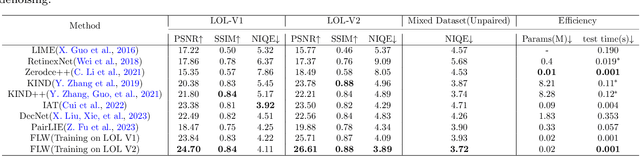
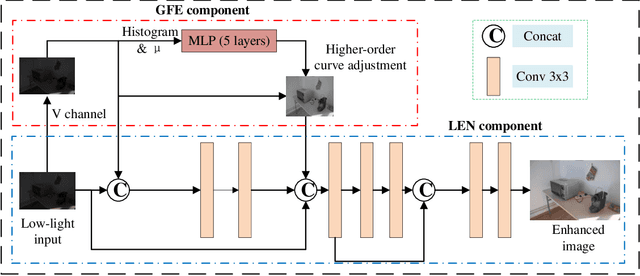
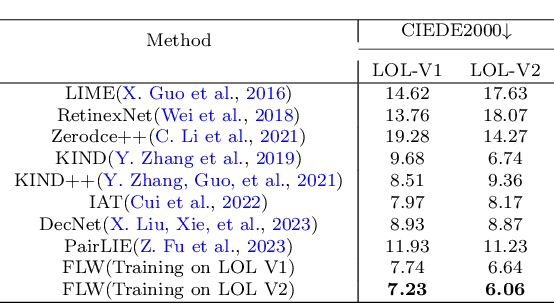
Low-light images often suffer from severe noise, low brightness, low contrast, and color deviation. While several low-light image enhancement methods have been proposed, there remains a lack of efficient methods that can simultaneously solve all of these problems. In this paper, we introduce FLW-Net, a Fast and LightWeight Network for low-light image enhancement that significantly improves processing speed and overall effect. To achieve efficient low-light image enhancement, we recognize the challenges of the lack of an absolute reference and the need for a large receptive field to obtain global contrast. Therefore, we propose an efficient global feature information extraction component and design loss functions based on relative information to overcome these challenges. Finally, we conduct comparative experiments to demonstrate the effectiveness of the proposed method, and the results confirm that FLW-Net can significantly reduce the complexity of supervised low-light image enhancement networks while improving processing effect. Code is available at https://github.com/hitzhangyu/FLW-Net
A Simple Self-calibration Method for The Internal Time Synchronization of MEMS LiDAR
Sep 26, 2021

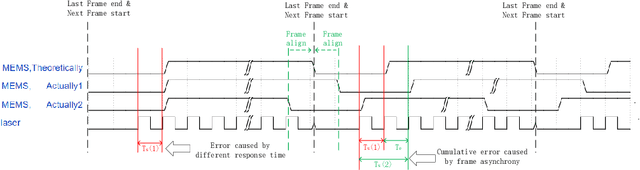
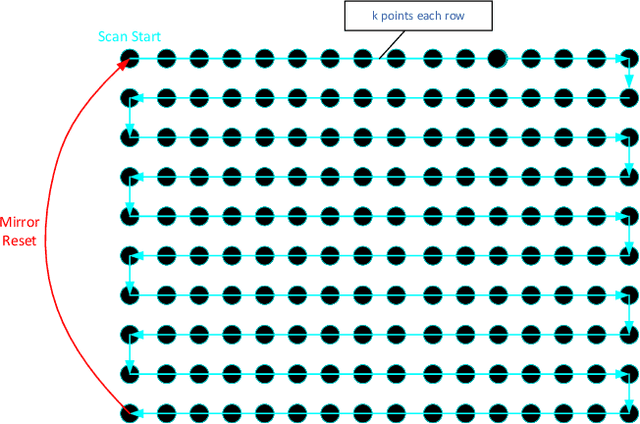
This paper proposes a simple self-calibration method for the internal time synchronization of MEMS(Micro-electromechanical systems) LiDAR during research and development. Firstly, we introduced the problem of internal time misalignment in MEMS lidar. Then, a robust Minimum Vertical Gradient(MVG) prior is proposed to calibrate the time difference between the laser and MEMS mirror, which can be calculated automatically without any artificial participation or specially designed cooperation target. Finally, actual experiments on MEMS LiDARs are implemented to demonstrate the effectiveness of the proposed method. It should be noted that the calibration can be implemented in a simple laboratory environment without any ranging equipment and artificial participation, which greatly accelerate the progress of research and development in practical applications.
Self-supervised Low Light Image Enhancement and Denoising
Mar 01, 2021
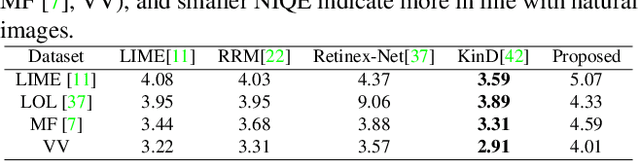
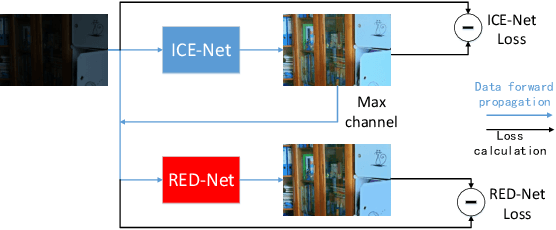
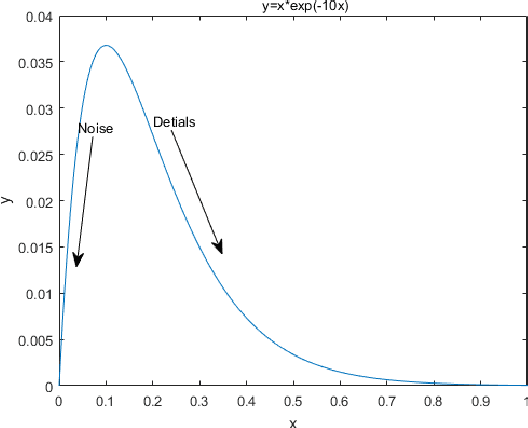
This paper proposes a self-supervised low light image enhancement method based on deep learning, which can improve the image contrast and reduce noise at the same time to avoid the blur caused by pre-/post-denoising. The method contains two deep sub-networks, an Image Contrast Enhancement Network (ICE-Net) and a Re-Enhancement and Denoising Network (RED-Net). The ICE-Net takes the low light image as input and produces a contrast enhanced image. The RED-Net takes the result of ICE-Net and the low light image as input, and can re-enhance the low light image and denoise at the same time. Both of the networks can be trained with low light images only, which is achieved by a Maximum Entropy based Retinex (ME-Retinex) model and an assumption that noises are independently distributed. In the ME-Retinex model, a new constraint on the reflectance image is introduced that the maximum channel of the reflectance image conforms to the maximum channel of the low light image and its entropy should be the largest, which converts the decomposition of reflectance and illumination in Retinex model to a non-ill-conditioned problem and allows the ICE-Net to be trained with a self-supervised way. The loss functions of RED-Net are carefully formulated to separate the noises and details during training, and they are based on the idea that, if noises are independently distributed, after the processing of smoothing filters (\eg mean filter), the gradient of the noise part should be smaller than the gradient of the detail part. It can be proved qualitatively and quantitatively through experiments that the proposed method is efficient.
Better Than Reference In Low Light Image Enhancement: Conditional Re-Enhancement Networks
Aug 26, 2020


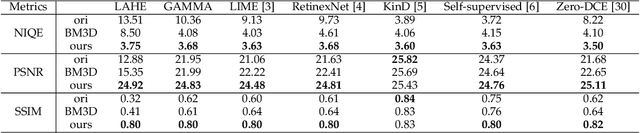
Low light images suffer from severe noise, low brightness, low contrast, etc. In previous researches, many image enhancement methods have been proposed, but few methods can deal with these problems simultaneously. In this paper, to solve these problems simultaneously, we propose a low light image enhancement method that can combined with supervised learning and previous HSV (Hue, Saturation, Value) or Retinex model based image enhancement methods. First, we analyse the relationship between the HSV color space and the Retinex theory, and show that the V channel (V channel in HSV color space, equals the maximum channel in RGB color space) of the enhanced image can well represent the contrast and brightness enhancement process. Then, a data-driven conditional re-enhancement network (denoted as CRENet) is proposed. The network takes low light images as input and the enhanced V channel as condition, then it can re-enhance the contrast and brightness of the low light image and at the same time reduce noise and color distortion. It should be noted that during the training process, any paired images with different exposure time can be used for training, and there is no need to carefully select the supervised images which will save a lot. In addition, it takes less than 20 ms to process a color image with the resolution 400*600 on a 2080Ti GPU. Finally, some comparative experiments are implemented to prove the effectiveness of the method. The results show that the method proposed in this paper can significantly improve the quality of the enhanced image, and by combining with other image contrast enhancement methods, the final enhancement result can even be better than the reference image in contrast and brightness. (Code will be available at https://github.com/hitzhangyu/image-enhancement-with-denoise)
Leveraging Undiagnosed Data for Glaucoma Classification with Teacher-Student Learning
Jul 22, 2020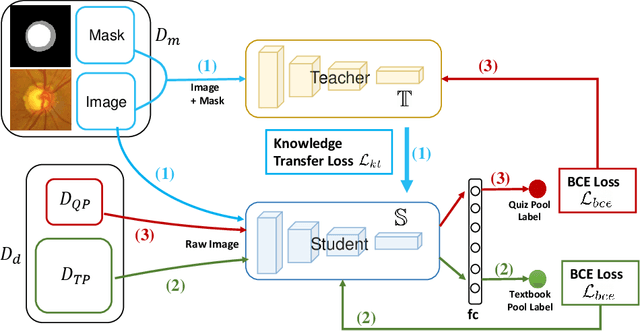
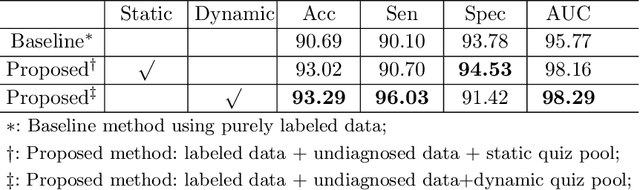
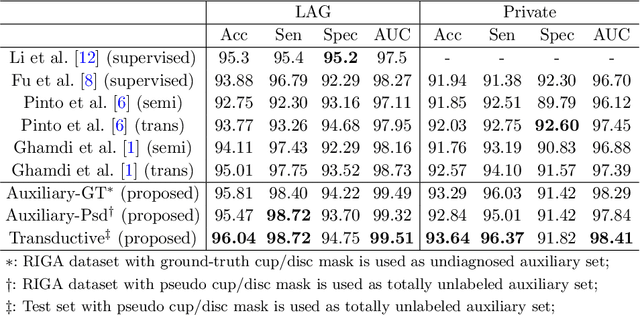
Recently, deep learning has been adopted to the glaucoma classification task with performance comparable to that of human experts. However, a well trained deep learning model demands a large quantity of properly labeled data, which is relatively expensive since the accurate labeling of glaucoma requires years of specialist training. In order to alleviate this problem, we propose a glaucoma classification framework which takes advantage of not only the properly labeled images, but also undiagnosed images without glaucoma labels. To be more specific, the proposed framework is adapted from the teacher-student-learning paradigm. The teacher model encodes the wrapped information of undiagnosed images to a latent feature space, meanwhile the student model learns from the teacher through knowledge transfer to improve the glaucoma classification. For the model training procedure, we propose a novel training strategy that simulates the real-world teaching practice named as 'Learning To Teach with Knowledge Transfer (L2T-KT)', and establish a 'Quiz Pool' as the teacher's optimization target. Experiments show that the proposed framework is able to utilize the undiagnosed data effectively to improve the glaucoma prediction performance.
Learning an Adaptive Model for Extreme Low-light Raw Image Processing
Apr 22, 2020


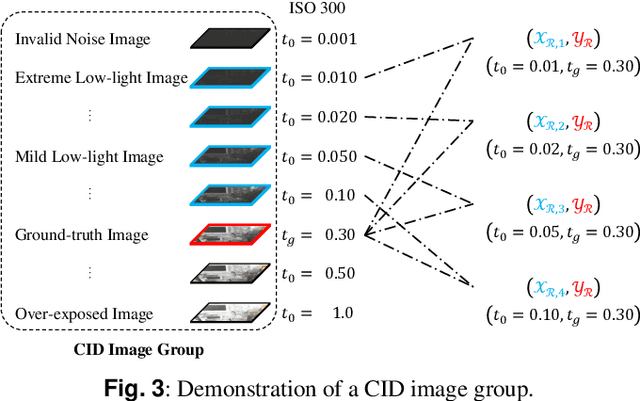
Low-light images suffer from severe noise and low illumination. Current deep learning models that are trained with real-world images have excellent noise reduction, but a ratio parameter must be chosen manually to complete the enhancement pipeline. In this work, we propose an adaptive low-light raw image enhancement network to avoid parameter-handcrafting and to improve image quality. The proposed method can be divided into two sub-models: Brightness Prediction (BP) and Exposure Shifting (ES). The former is designed to control the brightness of the resulting image by estimating a guideline exposure time $t_1$. The latter learns to approximate an exposure-shifting operator $ES$, converting a low-light image with real exposure time $t_0$ to a noise-free image with guideline exposure time $t_1$. Additionally, structural similarity (SSIM) loss and Image Enhancement Vector (IEV) are introduced to promote image quality, and a new Campus Image Dataset (CID) is proposed to overcome the limitations of the existing datasets and to supervise the training of the proposed model. Using the proposed model, we can achieve high-quality low-light image enhancement from a single raw image. In quantitative tests, it is shown that the proposed method has the lowest Noise Level Estimation (NLE) score compared with the state-of-the-art low-light algorithms, suggesting a superior denoising performance. Furthermore, those tests illustrate that the proposed method is able to adaptively control the global image brightness according to the content of the image scene. Lastly, the potential application in video processing is briefly discussed.
TanhExp: A Smooth Activation Function with High Convergence Speed for Lightweight Neural Networks
Mar 22, 2020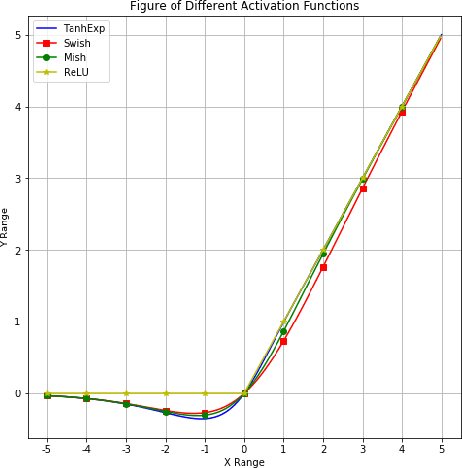
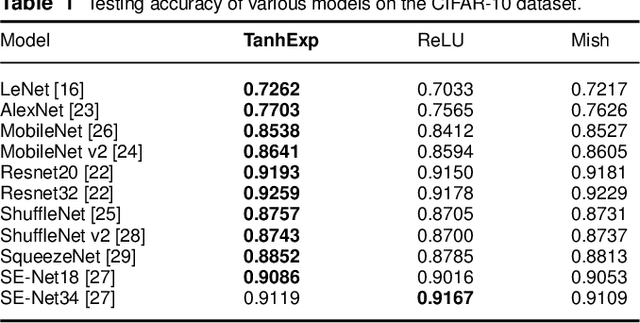
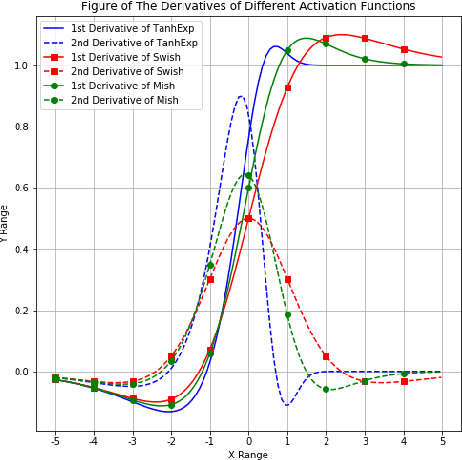

Lightweight or mobile neural networks used for real-time computer vision tasks contain fewer parameters than normal networks, which lead to a constrained performance. In this work, we proposed a novel activation function named Tanh Exponential Activation Function (TanhExp) which can improve the performance for these networks on image classification task significantly. The definition of TanhExp is f(x) = xtanh(e^x). We demonstrate the simplicity, efficiency, and robustness of TanhExp on various datasets and network models and TanhExp outperforms its counterparts in both convergence speed and accuracy. Its behaviour also remains stable even with noise added and dataset altered. We show that without increasing the size of the network, the capacity of lightweight neural networks can be enhanced by TanhExp with only a few training epochs and no extra parameters added.
Self-supervised Image Enhancement Network: Training with Low Light Images Only
Feb 26, 2020
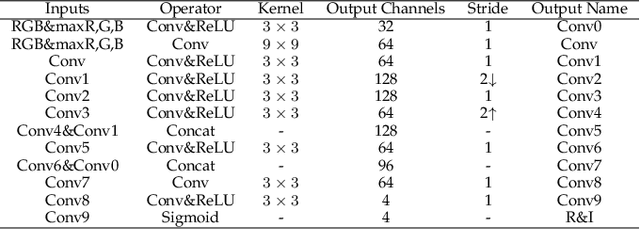
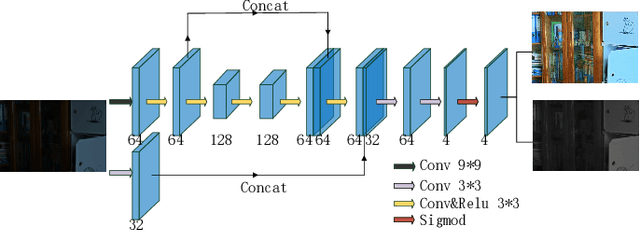
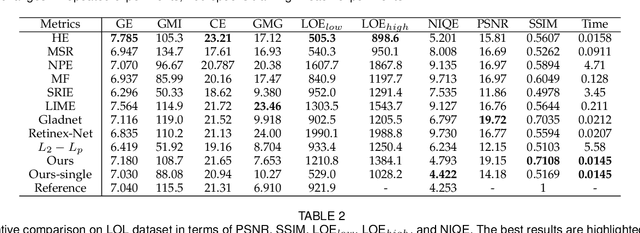
This paper proposes a self-supervised low light image enhancement method based on deep learning. Inspired by information entropy theory and Retinex model, we proposed a maximum entropy based Retinex model. With this model, a very simple network can separate the illumination and reflectance, and the network can be trained with low light images only. We introduce a constraint that the maximum channel of the reflectance conforms to the maximum channel of the low light image and its entropy should be largest in our model to achieve self-supervised learning. Our model is very simple and does not rely on any well-designed data set (even one low light image can complete the training). The network only needs minute-level training to achieve image enhancement. It can be proved through experiments that the proposed method has reached the state-of-the-art in terms of processing speed and effect.
Learning deep neural networks in blind deblurring framework
Mar 07, 2019

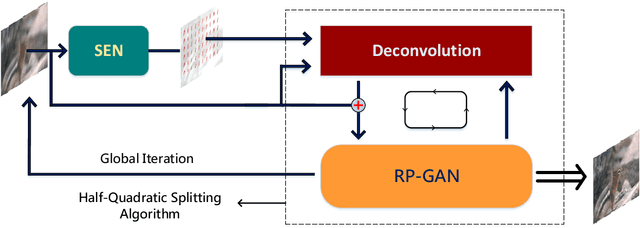
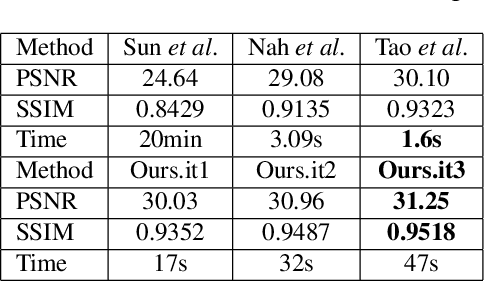
Recently, end-to-end learning methods based on deep neural network (DNN) have been proven effective for blind deblurring. Without human-made assumptions and numerical algorithms, they are able to restore blurry images with fewer artifacts and better perceptual quality. However, without the theoretical guidance, these methods sometimes generate unreasonable results and often perform worse when the motion is complex. In this paper, for overcoming these drawbacks, we integrate deep convolution neural networks into conventional deblurring framework. Specifically, we build Stacked Estimate Residual Net (SEN) to estimate the motion flow map and Recurrent Prior Generative and Adversarial Net (RP-GAN) to learn an image prior constrained term in half-quadratic splitting algorithm. The generator and discriminators are also designed to be adaptive to the iterative optimization. Comparing with state-of-the-art end-to-end learning based methods, our method restores reasonable details and shows better generalization ability.