 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic-VAE: Semantic-Alignment Latent Representation for Better Speech Synthesis
Sep 26, 2025While mel-spectrograms have been widely utilized as intermediate representations in zero-shot text-to-speech (TTS), their inherent redundancy leads to inefficiency in learning text-speech alignment. Compact VAE-based latent representations have recently emerged as a stronger alternative, but they also face a fundamental optimization dilemma: higher-dimensional latent spaces improve reconstruction quality and speaker similarity, but degrade intelligibility, while lower-dimensional spaces improve intelligibility at the expense of reconstruction fidelity. To overcome this dilemma, we propose Semantic-VAE, a novel VAE framework that utilizes semantic alignment regularization in the latent space. This design alleviates the reconstruction-generation trade-off by capturing semantic structure in high-dimensional latent representations. Extensive experiments demonstrate that Semantic-VAE significantly improves synthesis quality and training efficiency. When integrated into F5-TTS, our method achieves 2.10% WER and 0.64 speaker similarity on LibriSpeech-PC, outperforming mel-based systems (2.23%, 0.60) and vanilla acoustic VAE baselines (2.65%, 0.59). We also release the code and models to facilitate further research.
Accelerating Diffusion-based Text-to-Speech Model Training with Dual Modality Alignment
May 26, 2025The goal of this paper is to optimize the training process of diffusion-based text-to-speech models. While recent studies have achieved remarkable advancements, their training demands substantial time and computational costs, largely due to the implicit guidance of diffusion models in learning complex intermediate representations. To address this, we propose A-DMA, an effective strategy for Accelerating training with Dual Modality Alignment. Our method introduces a novel alignment pipeline leveraging both text and speech modalities: text-guided alignment, which incorporates contextual representations, and speech-guided alignment, which refines semantic representations. By aligning hidden states with discriminative features, our training scheme reduces the reliance on diffusion models for learning complex representations. Extensive experiments demonstrate that A-DMA doubles the convergence speed while achieving superior performance over baselines. Code and demo samples are available at: https://github.com/ZhikangNiu/A-DMA
YuE: Scaling Open Foundation Models for Long-Form Music Generation
Mar 11, 2025We tackle the task of long-form music generation--particularly the challenging \textbf{lyrics-to-song} problem--by introducing YuE, a family of open foundation models based on the LLaMA2 architecture. Specifically, YuE scales to trillions of tokens and generates up to five minutes of music while maintaining lyrical alignment, coherent musical structure, and engaging vocal melodies with appropriate accompaniment. It achieves this through (1) track-decoupled next-token prediction to overcome dense mixture signals, (2) structural progressive conditioning for long-context lyrical alignment, and (3) a multitask, multiphase pre-training recipe to converge and generalize. In addition, we redesign the in-context learning technique for music generation, enabling versatile style transfer (e.g., converting Japanese city pop into an English rap while preserving the original accompaniment) and bidirectional generation. Through extensive evaluation, we demonstrate that YuE matches or even surpasses some of the proprietary systems in musicality and vocal agility. In addition, fine-tuning YuE enables additional controls and enhanced support for tail languages. Furthermore, beyond generation, we show that YuE's learned representations can perform well on music understanding tasks, where the results of YuE match or exceed state-of-the-art methods on the MARBLE benchmark. Keywords: lyrics2song, song generation, long-form, foundation model, music generation
F5-TTS: A Fairytaler that Fakes Fluent and Faithful Speech with Flow Matching
Oct 09, 2024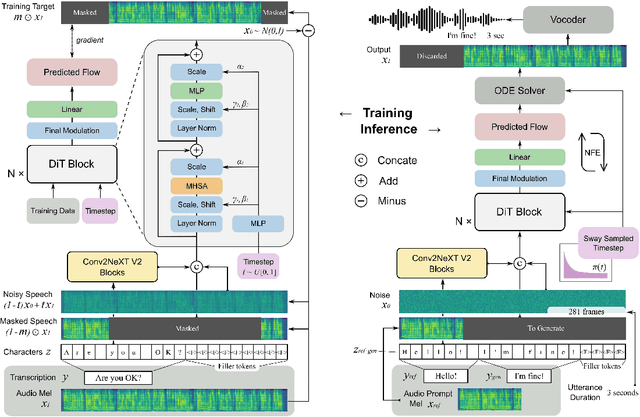
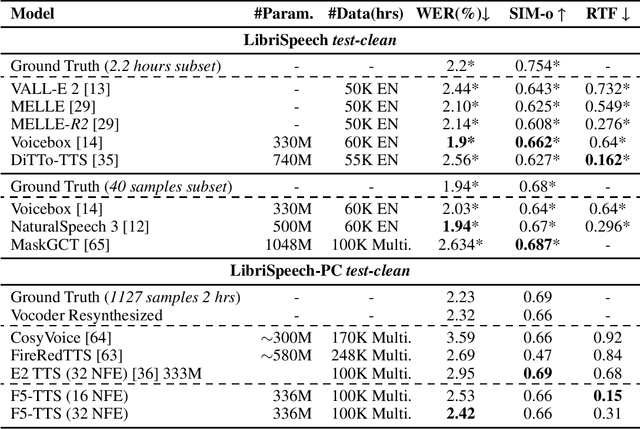
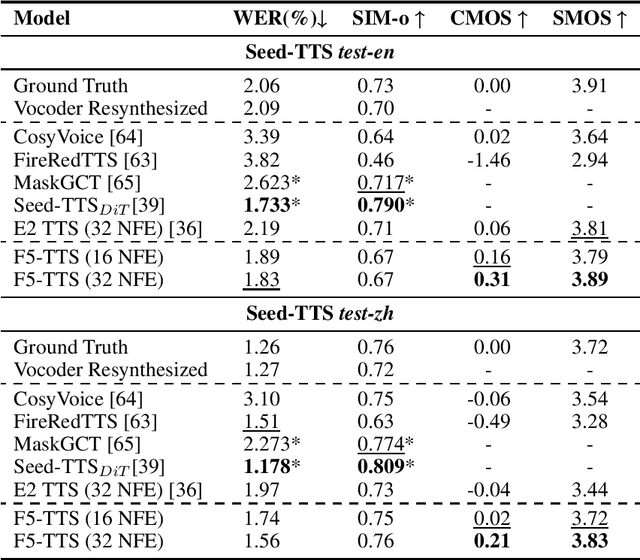
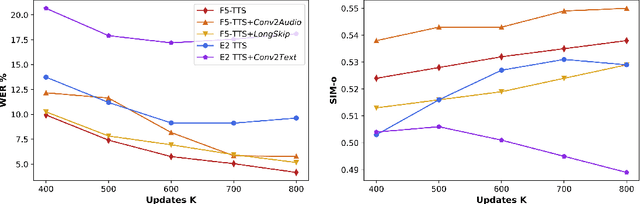
This paper introduces F5-TTS, a fully non-autoregressive text-to-speech system based on flow matching with Diffusion Transformer (DiT). Without requiring complex designs such as duration model, text encoder, and phoneme alignment, the text input is simply padded with filler tokens to the same length as input speech, and then the denoising is performed for speech generation, which was originally proved feasible by E2 TTS. However, the original design of E2 TTS makes it hard to follow due to its slow convergence and low robustness. To address these issues, we first model the input with ConvNeXt to refine the text representation, making it easy to align with the speech. We further propose an inference-time Sway Sampling strategy, which significantly improves our model's performance and efficiency. This sampling strategy for flow step can be easily applied to existing flow matching based models without retraining. Our design allows faster training and achieves an inference RTF of 0.15, which is greatly improved compared to state-of-the-art diffusion-based TTS models. Trained on a public 100K hours multilingual dataset, our Fairytaler Fakes Fluent and Faithful speech with Flow matching (F5-TTS) exhibits highly natural and expressive zero-shot ability, seamless code-switching capability, and speed control efficiency. Demo samples can be found at https://SWivid.github.io/F5-TTS. We release all code and checkpoints to promote community development.
InstructSing: High-Fidelity Singing Voice Generation via Instructing Yourself
Sep 10, 2024



It is challenging to accelerate the training process while ensuring both high-quality generated voices and acceptable inference speed. In this paper, we propose a novel neural vocoder called InstructSing, which can converge much faster compared with other neural vocoders while maintaining good performance by integrating differentiable digital signal processing and adversarial training. It includes one generator and two discriminators. Specifically, the generator incorporates a harmonic-plus-noise (HN) module to produce 8kHz audio as an instructive signal. Subsequently, the HN module is connected with an extended WaveNet by an UNet-based module, which transforms the output of the HN module to a latent variable sequence containing essential periodic and aperiodic information. In addition to the latent sequence, the extended WaveNet also takes the mel-spectrogram as input to generate 48kHz high-fidelity singing voices. In terms of discriminators, we combine a multi-period discriminator, as originally proposed in HiFiGAN, with a multi-resolution multi-band STFT discriminator. Notably, InstructSing achieves comparable voice quality to other neural vocoders but with only one-tenth of the training steps on a 4 NVIDIA V100 GPU machine\footnote{{Demo page: \href{https://wavelandspeech.github.io/instructsing/}{\texttt{https://wavelandspeech.github.io/inst\\ructsing/}}}}. We plan to open-source our code and pretrained model once the paper get accepted.
HAM-TTS: Hierarchical Acoustic Modeling for Token-Based Zero-Shot Text-to-Speech with Model and Data Scaling
Mar 09, 2024



Token-based text-to-speech (TTS) models have emerged as a promising avenue for generating natural and realistic speech, yet they grapple with low pronunciation accuracy, speaking style and timbre inconsistency, and a substantial need for diverse training data. In response, we introduce a novel hierarchical acoustic modeling approach complemented by a tailored data augmentation strategy and train it on the combination of real and synthetic data, scaling the data size up to 650k hours, leading to the zero-shot TTS model with 0.8B parameters. Specifically, our method incorporates a latent variable sequence containing supplementary acoustic information based on refined self-supervised learning (SSL) discrete units into the TTS model by a predictor. This significantly mitigates pronunciation errors and style mutations in synthesized speech. During training, we strategically replace and duplicate segments of the data to enhance timbre uniformity. Moreover, a pretrained few-shot voice conversion model is utilized to generate a plethora of voices with identical content yet varied timbres. This facilitates the explicit learning of utterance-level one-to-many mappings, enriching speech diversity and also ensuring consistency in timbre. Comparative experiments (Demo page: https://anonymous.4open.science/w/ham-tts/)demonstrate our model's superiority over VALL-E in pronunciation precision and maintaining speaking style, as well as timbre continuity.
CrossSinger: A Cross-Lingual Multi-Singer High-Fidelity Singing Voice Synthesizer Trained on Monolingual Singers
Sep 22, 2023It is challenging to build a multi-singer high-fidelity singing voice synthesis system with cross-lingual ability by only using monolingual singers in the training stage. In this paper, we propose CrossSinger, which is a cross-lingual singing voice synthesizer based on Xiaoicesing2. Specifically, we utilize International Phonetic Alphabet to unify the representation for all languages of the training data. Moreover, we leverage conditional layer normalization to incorporate the language information into the model for better pronunciation when singers meet unseen languages. Additionally, gradient reversal layer (GRL) is utilized to remove singer biases included in lyrics since all singers are monolingual, which indicates singer's identity is implicitly associated with the text. The experiment is conducted on a combination of three singing voice datasets containing Japanese Kiritan dataset, English NUS-48E dataset, and one internal Chinese dataset. The result shows CrossSinger can synthesize high-fidelity songs for various singers with cross-lingual ability, including code-switch cases.
A Fast and Lightweight Network for Low-Light Image Enhancement
Apr 06, 2023
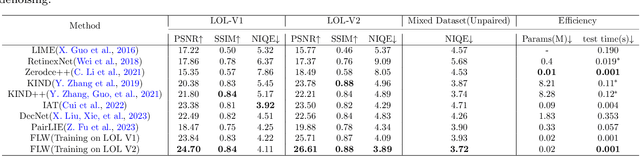
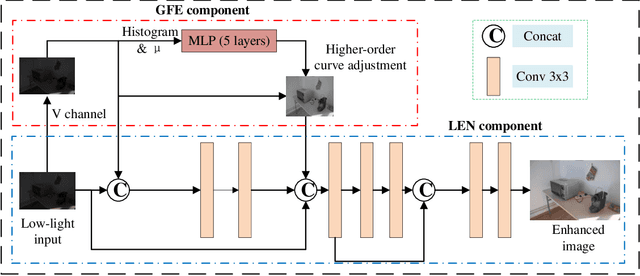
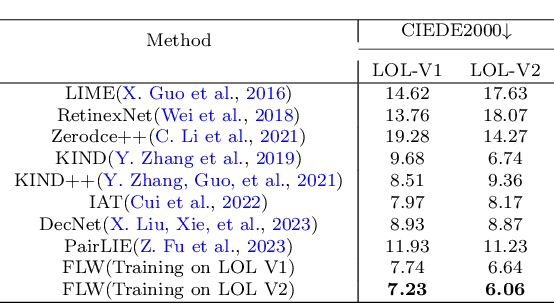
Low-light images often suffer from severe noise, low brightness, low contrast, and color deviation. While several low-light image enhancement methods have been proposed, there remains a lack of efficient methods that can simultaneously solve all of these problems. In this paper, we introduce FLW-Net, a Fast and LightWeight Network for low-light image enhancement that significantly improves processing speed and overall effect. To achieve efficient low-light image enhancement, we recognize the challenges of the lack of an absolute reference and the need for a large receptive field to obtain global contrast. Therefore, we propose an efficient global feature information extraction component and design loss functions based on relative information to overcome these challenges. Finally, we conduct comparative experiments to demonstrate the effectiveness of the proposed method, and the results confirm that FLW-Net can significantly reduce the complexity of supervised low-light image enhancement networks while improving processing effect. Code is available at https://github.com/hitzhangyu/FLW-Net
Xiaoicesing 2: A High-Fidelity Singing Voice Synthesizer Based on Generative Adversarial Network
Oct 28, 2022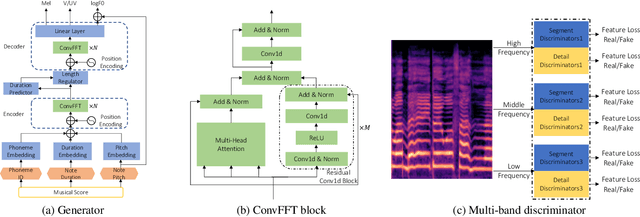


XiaoiceSing is a singing voice synthesis (SVS) system that aims at generating 48kHz singing voices. However, the mel-spectrogram generated by it is over-smoothing in middle- and high-frequency areas due to no special design for modeling the details of these parts. In this paper, we propose XiaoiceSing2, which can generate the details of middle- and high-frequency parts to better construct the full-band mel-spectrogram. Specifically, in order to alleviate this problem, XiaoiceSing2 adopts a generative adversarial network (GAN), which consists of a FastSpeech-based generator and a multi-band discriminator. We improve the feed-forward Transformer (FFT) block by adding multiple residual convolutional blocks in parallel with the self-attention block to balance the local and global features. The multi-band discriminator contains three sub-discriminators responsible for low-, middle-, and high-frequency parts of the mel-spectrogram, respectively. Each sub-discriminator is composed of several segment discriminators (SD) and detail discriminators (DD) to distinguish the audio from different aspects. The experiment on our internal 48kHz singing voice dataset shows XiaoiceSing2 significantly improves the quality of the singing voice over XiaoiceSing.
HiFi-WaveGAN: Generative Adversarial Network with Auxiliary Spectrogram-Phase Loss for High-Fidelity Singing Voice Generation
Oct 26, 2022Entertainment-oriented singing voice synthesis (SVS) requires a vocoder to generate high-fidelity (e.g. 48kHz) audio. However, most text-to-speech (TTS) vocoders cannot work well in this scenario even if the neural vocoder for TTS has achieved significant progress. In this paper, we propose HiFi-WaveGAN which is designed for synthesizing the 48kHz high-quality singing voices from the full-band mel-spectrogram in real-time. Specifically, it consists of a generator improved from WaveNet, a multi-period discriminator same to HiFiGAN, and a multi-resolution spectrogram discriminator borrowed from UnivNet. To better reconstruct the high-frequency part from the full-band mel-spectrogram, we design a novel auxiliary spectrogram-phase loss to train the neural network, which can also accelerate the training process. The experimental result shows that our proposed HiFi-WaveGAN significantly outperforms other neural vocoders such as Parallel WaveGAN (PWG) and HiFiGAN in the mean opinion score (MOS) metric for the 48kHz SVS task. And a comparative study of HiFi-WaveGAN with/without phase loss term proves that phase loss indeed improves the training speed. Besides, we also compare the spectrogram generated by our HiFi-WaveGAN and PWG, which shows our HiFi-WaveGAN has a more powerful ability to model the high-frequency parts.