 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReViSE: Towards Reason-Informed Video Editing in Unified Models with Self-Reflective Learning
Dec 11, 2025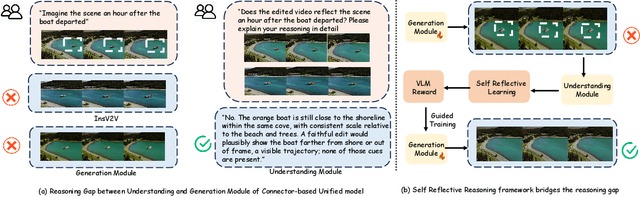
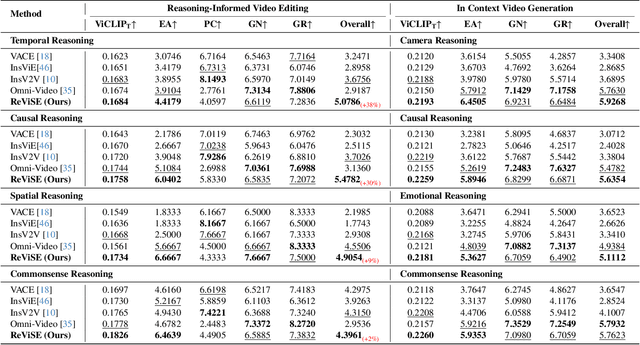

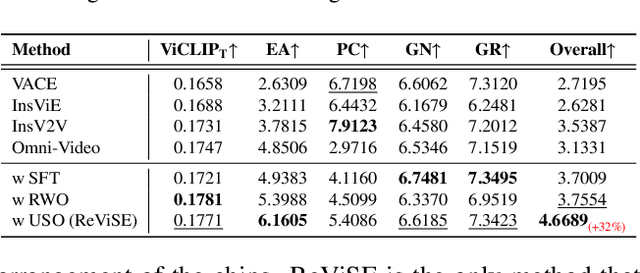
Video unified models exhibit strong capabilities in understanding and generation, yet they struggle with reason-informed visual editing even when equipped with powerful internal vision-language models (VLMs). We attribute this gap to two factors: 1) existing datasets are inadequate for training and evaluating reasoning-aware video editing, and 2) an inherent disconnect between the models' reasoning and editing capabilities, which prevents the rich understanding from effectively instructing the editing process. Bridging this gap requires an integrated framework that connects reasoning with visual transformation. To address this gap, we introduce the Reason-Informed Video Editing (RVE) task, which requires reasoning about physical plausibility and causal dynamics during editing. To support systematic evaluation, we construct RVE-Bench, a comprehensive benchmark with two complementary subsets: Reasoning-Informed Video Editing and In-Context Video Generation. These subsets cover diverse reasoning dimensions and real-world editing scenarios. Building upon this foundation, we propose the ReViSE, a Self-Reflective Reasoning (SRF) framework that unifies generation and evaluation within a single architecture. The model's internal VLM provides intrinsic feedback by assessing whether the edited video logically satisfies the given instruction. The differential feedback that refines the generator's reasoning behavior during training. Extensive experiments on RVE-Bench demonstrate that ReViSE significantly enhances editing accuracy and visual fidelity, achieving a 32% improvement of the Overall score in the reasoning-informed video editing subset over state-of-the-art methods.
Co$^{3}$Gesture: Towards Coherent Concurrent Co-speech 3D Gesture Generation with Interactive Diffusion
May 03, 2025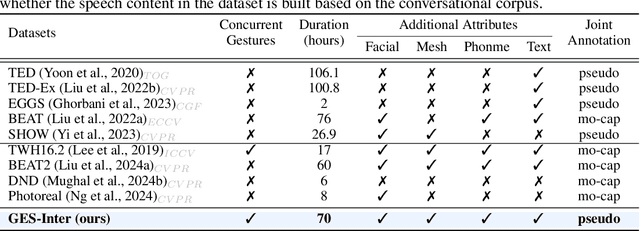

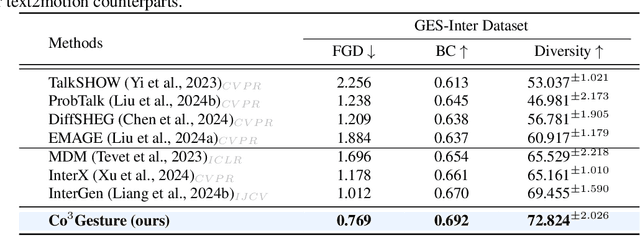
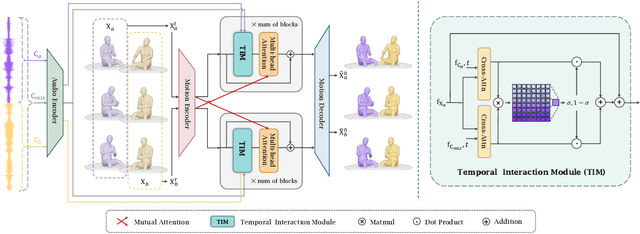
Generating gestures from human speech has gained tremendous progress in animating virtual avatars. While the existing methods enable synthesizing gestures cooperated by individual self-talking, they overlook the practicality of concurrent gesture modeling with two-person interactive conversations. Moreover, the lack of high-quality datasets with concurrent co-speech gestures also limits handling this issue. To fulfill this goal, we first construct a large-scale concurrent co-speech gesture dataset that contains more than 7M frames for diverse two-person interactive posture sequences, dubbed GES-Inter. Additionally, we propose Co$^3$Gesture, a novel framework that enables coherent concurrent co-speech gesture synthesis including two-person interactive movements. Considering the asymmetric body dynamics of two speakers, our framework is built upon two cooperative generation branches conditioned on separated speaker audio. Specifically, to enhance the coordination of human postures with respect to corresponding speaker audios while interacting with the conversational partner, we present a Temporal Interaction Module (TIM). TIM can effectively model the temporal association representation between two speakers' gesture sequences as interaction guidance and fuse it into the concurrent gesture generation. Then, we devise a mutual attention mechanism to further holistically boost learning dependencies of interacted concurrent motions, thereby enabling us to generate vivid and coherent gestures. Extensive experiments demonstrate that our method outperforms the state-of-the-art models on our newly collected GES-Inter dataset. The dataset and source code are publicly available at \href{https://mattie-e.github.io/Co3/}{\textit{https://mattie-e.github.io/Co3/}}.
YuE: Scaling Open Foundation Models for Long-Form Music Generation
Mar 11, 2025We tackle the task of long-form music generation--particularly the challenging \textbf{lyrics-to-song} problem--by introducing YuE, a family of open foundation models based on the LLaMA2 architecture. Specifically, YuE scales to trillions of tokens and generates up to five minutes of music while maintaining lyrical alignment, coherent musical structure, and engaging vocal melodies with appropriate accompaniment. It achieves this through (1) track-decoupled next-token prediction to overcome dense mixture signals, (2) structural progressive conditioning for long-context lyrical alignment, and (3) a multitask, multiphase pre-training recipe to converge and generalize. In addition, we redesign the in-context learning technique for music generation, enabling versatile style transfer (e.g., converting Japanese city pop into an English rap while preserving the original accompaniment) and bidirectional generation. Through extensive evaluation, we demonstrate that YuE matches or even surpasses some of the proprietary systems in musicality and vocal agility. In addition, fine-tuning YuE enables additional controls and enhanced support for tail languages. Furthermore, beyond generation, we show that YuE's learned representations can perform well on music understanding tasks, where the results of YuE match or exceed state-of-the-art methods on the MARBLE benchmark. Keywords: lyrics2song, song generation, long-form, foundation model, music generation
Spark-TTS: An Efficient LLM-Based Text-to-Speech Model with Single-Stream Decoupled Speech Tokens
Mar 03, 2025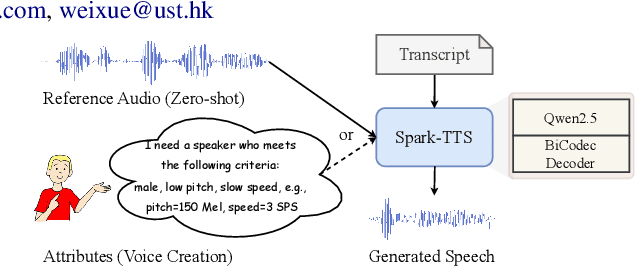
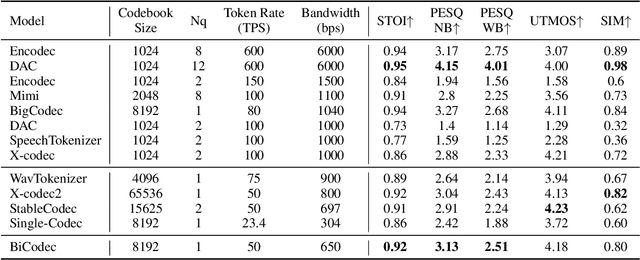
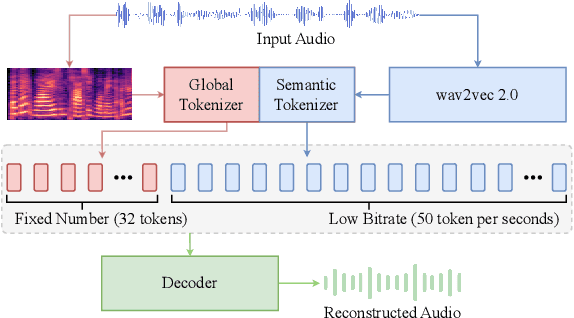
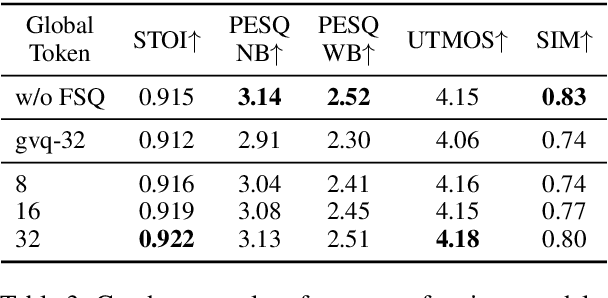
Recent advancements in large language models (LLMs) have driven significant progress in zero-shot text-to-speech (TTS) synthesis. However, existing foundation models rely on multi-stage processing or complex architectures for predicting multiple codebooks, limiting efficiency and integration flexibility. To overcome these challenges, we introduce Spark-TTS, a novel system powered by BiCodec, a single-stream speech codec that decomposes speech into two complementary token types: low-bitrate semantic tokens for linguistic content and fixed-length global tokens for speaker attributes. This disentangled representation, combined with the Qwen2.5 LLM and a chain-of-thought (CoT) generation approach, enables both coarse-grained control (e.g., gender, speaking style) and fine-grained adjustments (e.g., precise pitch values, speaking rate). To facilitate research in controllable TTS, we introduce VoxBox, a meticulously curated 100,000-hour dataset with comprehensive attribute annotations. Extensive experiments demonstrate that Spark-TTS not only achieves state-of-the-art zero-shot voice cloning but also generates highly customizable voices that surpass the limitations of reference-based synthesis. Source code, pre-trained models, and audio samples are available at https://github.com/SparkAudio/Spark-TTS.
Audio-FLAN: A Preliminary Release
Feb 23, 2025



Recent advancements in audio tokenization have significantly enhanced the integration of audio capabilities into large language models (LLMs). However, audio understanding and generation are often treated as distinct tasks, hindering the development of truly unified audio-language models. While instruction tuning has demonstrated remarkable success in improving generalization and zero-shot learning across text and vision, its application to audio remains largely unexplored. A major obstacle is the lack of comprehensive datasets that unify audio understanding and generation. To address this, we introduce Audio-FLAN, a large-scale instruction-tuning dataset covering 80 diverse tasks across speech, music, and sound domains, with over 100 million instances. Audio-FLAN lays the foundation for unified audio-language models that can seamlessly handle both understanding (e.g., transcription, comprehension) and generation (e.g., speech, music, sound) tasks across a wide range of audio domains in a zero-shot manner. The Audio-FLAN dataset is available on HuggingFace and GitHub and will be continuously updated.
Codec Does Matter: Exploring the Semantic Shortcoming of Codec for Audio Language Model
Aug 30, 2024



Recent advancements in audio generation have been significantly propelled by the capabilities of Large Language Models (LLMs). The existing research on audio LLM has primarily focused on enhancing the architecture and scale of audio language models, as well as leveraging larger datasets, and generally, acoustic codecs, such as EnCodec, are used for audio tokenization. However, these codecs were originally designed for audio compression, which may lead to suboptimal performance in the context of audio LLM. Our research aims to address the shortcomings of current audio LLM codecs, particularly their challenges in maintaining semantic integrity in generated audio. For instance, existing methods like VALL-E, which condition acoustic token generation on text transcriptions, often suffer from content inaccuracies and elevated word error rates (WER) due to semantic misinterpretations of acoustic tokens, resulting in word skipping and errors. To overcome these issues, we propose a straightforward yet effective approach called X-Codec. X-Codec incorporates semantic features from a pre-trained semantic encoder before the Residual Vector Quantization (RVQ) stage and introduces a semantic reconstruction loss after RVQ. By enhancing the semantic ability of the codec, X-Codec significantly reduces WER in speech synthesis tasks and extends these benefits to non-speech applications, including music and sound generation. Our experiments in text-to-speech, music continuation, and text-to-sound tasks demonstrate that integrating semantic information substantially improves the overall performance of language models in audio generation. Our code and demo are available (Demo: https://x-codec-audio.github.io Code: https://github.com/zhenye234/xcodec)
MMTrail: A Multimodal Trailer Video Dataset with Language and Music Descriptions
Jul 30, 2024



Massive multi-modality datasets play a significant role in facilitating the success of large video-language models. However, current video-language datasets primarily provide text descriptions for visual frames, considering audio to be weakly related information. They usually overlook exploring the potential of inherent audio-visual correlation, leading to monotonous annotation within each modality instead of comprehensive and precise descriptions. Such ignorance results in the difficulty of multiple cross-modality studies. To fulfill this gap, we present MMTrail, a large-scale multi-modality video-language dataset incorporating more than 20M trailer clips with visual captions, and 2M high-quality clips with multimodal captions. Trailers preview full-length video works and integrate context, visual frames, and background music. In particular, the trailer has two main advantages: (1) the topics are diverse, and the content characters are of various types, e.g., film, news, and gaming. (2) the corresponding background music is custom-designed, making it more coherent with the visual context. Upon these insights, we propose a systemic captioning framework, achieving various modality annotations with more than 27.1k hours of trailer videos. Here, to ensure the caption retains music perspective while preserving the authority of visual context, we leverage the advanced LLM to merge all annotations adaptively. In this fashion, our MMtrail dataset potentially paves the path for fine-grained large multimodal-language model training. In experiments, we provide evaluation metrics and benchmark results on our dataset, demonstrating the high quality of our annotation and its effectiveness for model training.
VidMuse: A Simple Video-to-Music Generation Framework with Long-Short-Term Modeling
Jun 06, 2024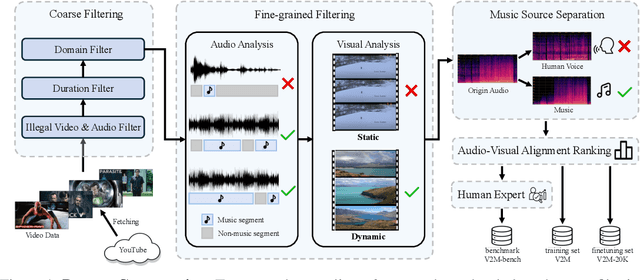
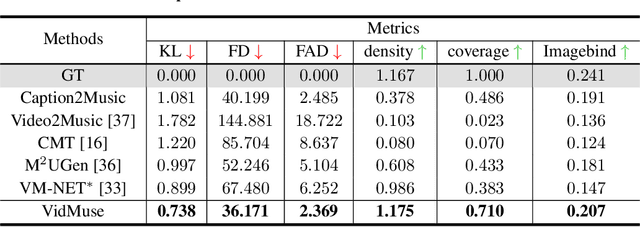
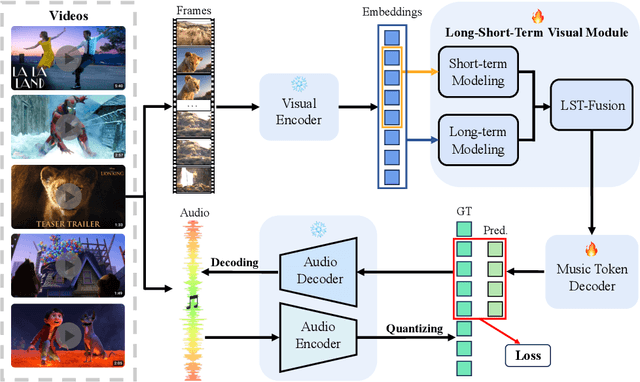
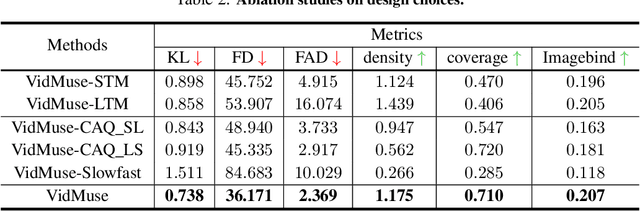
In this work, we systematically study music generation conditioned solely on the video. First, we present a large-scale dataset comprising 190K video-music pairs, including various genres such as movie trailers, advertisements, and documentaries. Furthermore, we propose VidMuse, a simple framework for generating music aligned with video inputs. VidMuse stands out by producing high-fidelity music that is both acoustically and semantically aligned with the video. By incorporating local and global visual cues, VidMuse enables the creation of musically coherent audio tracks that consistently match the video content through Long-Short-Term modeling. Through extensive experiments, VidMuse outperforms existing models in terms of audio quality, diversity, and audio-visual alignment. The code and datasets will be available at https://github.com/ZeyueT/VidMuse/.
CoCoGesture: Toward Coherent Co-speech 3D Gesture Generation in the Wild
May 27, 2024



Deriving co-speech 3D gestures has seen tremendous progress in virtual avatar animation. Yet, the existing methods often produce stiff and unreasonable gestures with unseen human speech inputs due to the limited 3D speech-gesture data. In this paper, we propose CoCoGesture, a novel framework enabling vivid and diverse gesture synthesis from unseen human speech prompts. Our key insight is built upon the custom-designed pretrain-fintune training paradigm. At the pretraining stage, we aim to formulate a large generalizable gesture diffusion model by learning the abundant postures manifold. Therefore, to alleviate the scarcity of 3D data, we first construct a large-scale co-speech 3D gesture dataset containing more than 40M meshed posture instances across 4.3K speakers, dubbed GES-X. Then, we scale up the large unconditional diffusion model to 1B parameters and pre-train it to be our gesture experts. At the finetune stage, we present the audio ControlNet that incorporates the human voice as condition prompts to guide the gesture generation. Here, we construct the audio ControlNet through a trainable copy of our pre-trained diffusion model. Moreover, we design a novel Mixture-of-Gesture-Experts (MoGE) block to adaptively fuse the audio embedding from the human speech and the gesture features from the pre-trained gesture experts with a routing mechanism. Such an effective manner ensures audio embedding is temporal coordinated with motion features while preserving the vivid and diverse gesture generation. Extensive experiments demonstrate that our proposed CoCoGesture outperforms the state-of-the-art methods on the zero-shot speech-to-gesture generation. The dataset will be publicly available at: https://mattie-e.github.io/GES-X/
ComposerX: Multi-Agent Symbolic Music Composition with LLMs
Apr 30, 2024

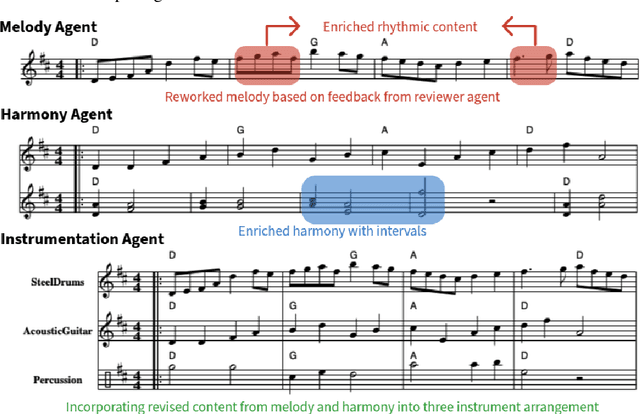
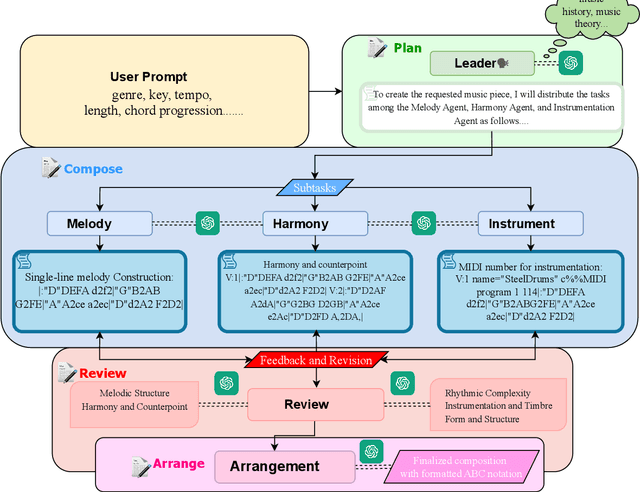
Music composition represents the creative side of humanity, and itself is a complex task that requires abilities to understand and generate information with long dependency and harmony constraints. While demonstrating impressive capabilities in STEM subjects, current LLMs easily fail in this task, generating ill-written music even when equipped with modern techniques like In-Context-Learning and Chain-of-Thoughts. To further explore and enhance LLMs' potential in music composition by leveraging their reasoning ability and the large knowledge base in music history and theory, we propose ComposerX, an agent-based symbolic music generation framework. We find that applying a multi-agent approach significantly improves the music composition quality of GPT-4. The results demonstrate that ComposerX is capable of producing coherent polyphonic music compositions with captivating melodies, while adhering to user instructions.