 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech Discrete Tokens or Continuous Features? A Comparative Analysis for Spoken Language Understanding in SpeechLLMs
Aug 25, 2025With the rise of Speech Large Language Models (SpeechLLMs), two dominant approaches have emerged for speech processing: discrete tokens and continuous features. Each approach has demonstrated strong capabilities in audio-related processing tasks. However, the performance gap between these two paradigms has not been thoroughly explored. To address this gap, we present a fair comparison of self-supervised learning (SSL)-based discrete and continuous features under the same experimental settings. We evaluate their performance across six spoken language understanding-related tasks using both small and large-scale LLMs (Qwen1.5-0.5B and Llama3.1-8B). We further conduct in-depth analyses, including efficient comparison, SSL layer analysis, LLM layer analysis, and robustness comparison. Our findings reveal that continuous features generally outperform discrete tokens in various tasks. Each speech processing method exhibits distinct characteristics and patterns in how it learns and processes speech information. We hope our results will provide valuable insights to advance spoken language understanding in SpeechLLMs.
DualSpeechLM: Towards Unified Speech Understanding and Generation via Dual Speech Token Modeling with Large Language Models
Aug 12, 2025Extending pre-trained Large Language Models (LLMs)'s speech understanding or generation abilities by introducing various effective speech tokens has attracted great attention in the speech community. However, building a unified speech understanding and generation model still faces the following challenges: (1) Due to the huge modality gap between speech tokens and text tokens, extending text LLMs to unified speech LLMs relies on large-scale paired data for fine-tuning, and (2) Generation and understanding tasks prefer information at different levels, e.g., generation benefits from detailed acoustic features, while understanding favors high-level semantics. This divergence leads to difficult performance optimization in one unified model. To solve these challenges, in this paper, we present two key insights in speech tokenization and speech language modeling. Specifically, we first propose an Understanding-driven Speech Tokenizer (USTokenizer), which extracts high-level semantic information essential for accomplishing understanding tasks using text LLMs. In this way, USToken enjoys better modality commonality with text, which reduces the difficulty of modality alignment in adapting text LLMs to speech LLMs. Secondly, we present DualSpeechLM, a dual-token modeling framework that concurrently models USToken as input and acoustic token as output within a unified, end-to-end framework, seamlessly integrating speech understanding and generation capabilities. Furthermore, we propose a novel semantic supervision loss and a Chain-of-Condition (CoC) strategy to stabilize model training and enhance speech generation performance. Experimental results demonstrate that our proposed approach effectively fosters a complementary relationship between understanding and generation tasks, highlighting the promising strategy of mutually enhancing both tasks in one unified model.
MMSU: A Massive Multi-task Spoken Language Understanding and Reasoning Benchmark
Jun 05, 2025Speech inherently contains rich acoustic information that extends far beyond the textual language. In real-world spoken language understanding, effective interpretation often requires integrating semantic meaning (e.g., content), paralinguistic features (e.g., emotions, speed, pitch) and phonological characteristics (e.g., prosody, intonation, rhythm), which are embedded in speech. While recent multimodal Speech Large Language Models (SpeechLLMs) have demonstrated remarkable capabilities in processing audio information, their ability to perform fine-grained perception and complex reasoning in natural speech remains largely unexplored. To address this gap, we introduce MMSU, a comprehensive benchmark designed specifically for understanding and reasoning in spoken language. MMSU comprises 5,000 meticulously curated audio-question-answer triplets across 47 distinct tasks. To ground our benchmark in linguistic theory, we systematically incorporate a wide range of linguistic phenomena, including phonetics, prosody, rhetoric, syntactics, semantics, and paralinguistics. Through a rigorous evaluation of 14 advanced SpeechLLMs, we identify substantial room for improvement in existing models, highlighting meaningful directions for future optimization. MMSU establishes a new standard for comprehensive assessment of spoken language understanding, providing valuable insights for developing more sophisticated human-AI speech interaction systems. MMSU benchmark is available at https://huggingface.co/datasets/ddwang2000/MMSU. Evaluation Code is available at https://github.com/dingdongwang/MMSU_Bench.
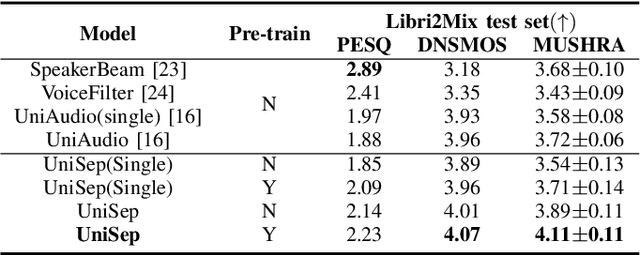
SoloSpeech: Enhancing Intelligibility and Quality in Target Speech Extraction through a Cascaded Generative Pipeline
May 25, 2025Target Speech Extraction (TSE) aims to isolate a target speaker's voice from a mixture of multiple speakers by leveraging speaker-specific cues, typically provided as auxiliary audio (a.k.a. cue audio). Although recent advancements in TSE have primarily employed discriminative models that offer high perceptual quality, these models often introduce unwanted artifacts, reduce naturalness, and are sensitive to discrepancies between training and testing environments. On the other hand, generative models for TSE lag in perceptual quality and intelligibility. To address these challenges, we present SoloSpeech, a novel cascaded generative pipeline that integrates compression, extraction, reconstruction, and correction processes. SoloSpeech features a speaker-embedding-free target extractor that utilizes conditional information from the cue audio's latent space, aligning it with the mixture audio's latent space to prevent mismatches. Evaluated on the widely-used Libri2Mix dataset, SoloSpeech achieves the new state-of-the-art intelligibility and quality in target speech extraction and speech separation tasks while demonstrating exceptional generalization on out-of-domain data and real-world scenarios.
Kimi-Audio Technical Report
Apr 25, 2025



We present Kimi-Audio, an open-source audio foundation model that excels in audio understanding, generation, and conversation. We detail the practices in building Kimi-Audio, including model architecture, data curation, training recipe, inference deployment, and evaluation. Specifically, we leverage a 12.5Hz audio tokenizer, design a novel LLM-based architecture with continuous features as input and discrete tokens as output, and develop a chunk-wise streaming detokenizer based on flow matching. We curate a pre-training dataset that consists of more than 13 million hours of audio data covering a wide range of modalities including speech, sound, and music, and build a pipeline to construct high-quality and diverse post-training data. Initialized from a pre-trained LLM, Kimi-Audio is continual pre-trained on both audio and text data with several carefully designed tasks, and then fine-tuned to support a diverse of audio-related tasks. Extensive evaluation shows that Kimi-Audio achieves state-of-the-art performance on a range of audio benchmarks including speech recognition, audio understanding, audio question answering, and speech conversation. We release the codes, model checkpoints, as well as the evaluation toolkits in https://github.com/MoonshotAI/Kimi-Audio.
UniSep: Universal Target Audio Separation with Language Models at Scale
Mar 31, 2025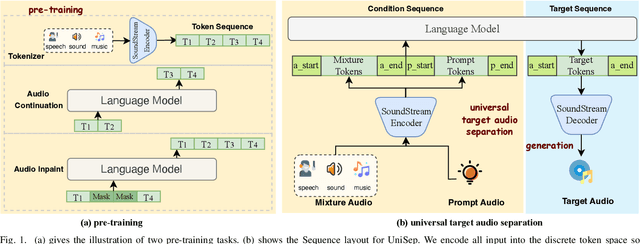
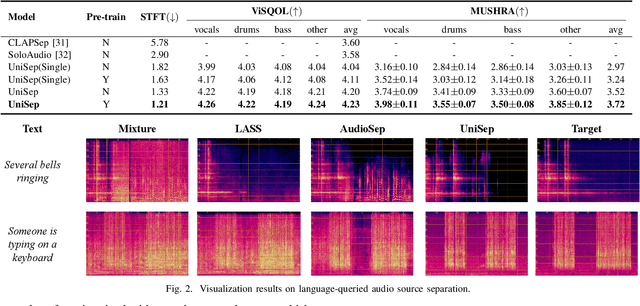

We propose Universal target audio Separation (UniSep), addressing the separation task on arbitrary mixtures of different types of audio. Distinguished from previous studies, UniSep is performed on unlimited source domains and unlimited source numbers. We formulate the separation task as a sequence-to-sequence problem, and a large language model (LLM) is used to model the audio sequence in the discrete latent space, leveraging the power of LLM in handling complex mixture audios with large-scale data. Moreover, a novel pre-training strategy is proposed to utilize audio-only data, which reduces the efforts of large-scale data simulation and enhances the ability of LLMs to understand the consistency and correlation of information within audio sequences. We also demonstrate the effectiveness of scaling datasets in an audio separation task: we use large-scale data (36.5k hours), including speech, music, and sound, to train a universal target audio separation model that is not limited to a specific domain. Experiments show that UniSep achieves competitive subjective and objective evaluation results compared with single-task models.
MoonCast: High-Quality Zero-Shot Podcast Generation
Mar 19, 2025


Recent advances in text-to-speech synthesis have achieved notable success in generating high-quality short utterances for individual speakers. However, these systems still face challenges when extending their capabilities to long, multi-speaker, and spontaneous dialogues, typical of real-world scenarios such as podcasts. These limitations arise from two primary challenges: 1) long speech: podcasts typically span several minutes, exceeding the upper limit of most existing work; 2) spontaneity: podcasts are marked by their spontaneous, oral nature, which sharply contrasts with formal, written contexts; existing works often fall short in capturing this spontaneity. In this paper, we propose MoonCast, a solution for high-quality zero-shot podcast generation, aiming to synthesize natural podcast-style speech from text-only sources (e.g., stories, technical reports, news in TXT, PDF, or Web URL formats) using the voices of unseen speakers. To generate long audio, we adopt a long-context language model-based audio modeling approach utilizing large-scale long-context speech data. To enhance spontaneity, we utilize a podcast generation module to generate scripts with spontaneous details, which have been empirically shown to be as crucial as the text-to-speech modeling itself. Experiments demonstrate that MoonCast outperforms baselines, with particularly notable improvements in spontaneity and coherence.
InSerter: Speech Instruction Following with Unsupervised Interleaved Pre-training
Mar 04, 2025



Recent advancements in speech large language models (SpeechLLMs) have attracted considerable attention. Nonetheless, current methods exhibit suboptimal performance in adhering to speech instructions. Notably, the intelligence of models significantly diminishes when processing speech-form input as compared to direct text-form input. Prior work has attempted to mitigate this semantic inconsistency between speech and text representations through techniques such as representation and behavior alignment, which involve the meticulous design of data pairs during the post-training phase. In this paper, we introduce a simple and scalable training method called InSerter, which stands for Interleaved Speech-Text Representation Pre-training. InSerter is designed to pre-train large-scale unsupervised speech-text sequences, where the speech is synthesized from randomly selected segments of an extensive text corpus using text-to-speech conversion. Consequently, the model acquires the ability to generate textual continuations corresponding to the provided speech segments, obviating the need for intensive data design endeavors. To systematically evaluate speech instruction-following capabilities, we introduce SpeechInstructBench, the first comprehensive benchmark specifically designed for speech-oriented instruction-following tasks. Our proposed InSerter achieves SOTA performance in SpeechInstructBench and demonstrates superior or competitive results across diverse speech processing tasks.
Audio-FLAN: A Preliminary Release
Feb 23, 2025



Recent advancements in audio tokenization have significantly enhanced the integration of audio capabilities into large language models (LLMs). However, audio understanding and generation are often treated as distinct tasks, hindering the development of truly unified audio-language models. While instruction tuning has demonstrated remarkable success in improving generalization and zero-shot learning across text and vision, its application to audio remains largely unexplored. A major obstacle is the lack of comprehensive datasets that unify audio understanding and generation. To address this, we introduce Audio-FLAN, a large-scale instruction-tuning dataset covering 80 diverse tasks across speech, music, and sound domains, with over 100 million instances. Audio-FLAN lays the foundation for unified audio-language models that can seamlessly handle both understanding (e.g., transcription, comprehension) and generation (e.g., speech, music, sound) tasks across a wide range of audio domains in a zero-shot manner. The Audio-FLAN dataset is available on HuggingFace and GitHub and will be continuously updated.
ATRI: Mitigating Multilingual Audio Text Retrieval Inconsistencies by Reducing Data Distribution Errors
Feb 22, 2025
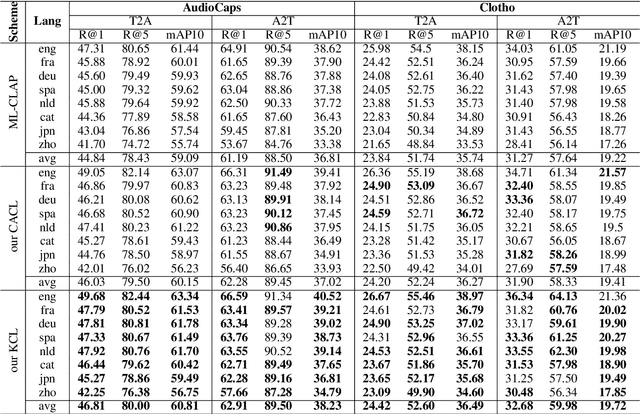
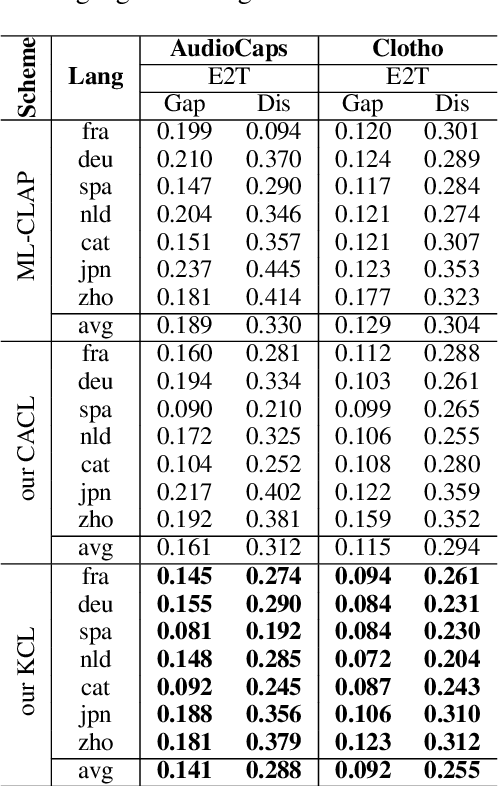
Multilingual audio-text retrieval (ML-ATR) is a challenging task that aims to retrieve audio clips or multilingual texts from databases. However, existing ML-ATR schemes suffer from inconsistencies for instance similarity matching across languages. We theoretically analyze the inconsistency in terms of both multilingual modal alignment direction error and weight error, and propose the theoretical weight error upper bound for quantifying the inconsistency. Based on the analysis of the weight error upper bound, we find that the inconsistency problem stems from the data distribution error caused by random sampling of languages. We propose a consistent ML-ATR scheme using 1-to-k contrastive learning and audio-English co-anchor contrastive learning, aiming to mitigate the negative impact of data distribution error on recall and consistency in ML-ATR. Experimental results on the translated AudioCaps and Clotho datasets show that our scheme achieves state-of-the-art performance on recall and consistency metrics for eight mainstream languages, including English. Our code will be available at https://github.com/ATRI-ACL/ATRI-ACL.