 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQwen3-TTS Technical Report
Jan 22, 2026In this report, we present the Qwen3-TTS series, a family of advanced multilingual, controllable, robust, and streaming text-to-speech models. Qwen3-TTS supports state-of-the-art 3-second voice cloning and description-based control, allowing both the creation of entirely novel voices and fine-grained manipulation over the output speech. Trained on over 5 million hours of speech data spanning 10 languages, Qwen3-TTS adopts a dual-track LM architecture for real-time synthesis, coupled with two speech tokenizers: 1) Qwen-TTS-Tokenizer-25Hz is a single-codebook codec emphasizing semantic content, which offers seamlessly integration with Qwen-Audio and enables streaming waveform reconstruction via a block-wise DiT. 2) Qwen-TTS-Tokenizer-12Hz achieves extreme bitrate reduction and ultra-low-latency streaming, enabling immediate first-packet emission ($97\,\mathrm{ms}$) through its 12.5 Hz, 16-layer multi-codebook design and a lightweight causal ConvNet. Extensive experiments indicate state-of-the-art performance across diverse objective and subjective benchmark (e.g., TTS multilingual test set, InstructTTSEval, and our long speech test set). To facilitate community research and development, we release both tokenizers and models under the Apache 2.0 license.
VoiceSculptor: Your Voice, Designed By You
Jan 15, 2026Despite rapid progress in text-to-speech (TTS), open-source systems still lack truly instruction-following, fine-grained control over core speech attributes (e.g., pitch, speaking rate, age, emotion, and style). We present VoiceSculptor, an open-source unified system that bridges this gap by integrating instruction-based voice design and high-fidelity voice cloning in a single framework. It generates controllable speaker timbre directly from natural-language descriptions, supports iterative refinement via Retrieval-Augmented Generation (RAG), and provides attribute-level edits across multiple dimensions. The designed voice is then rendered into a prompt waveform and fed into a cloning model to enable high-fidelity timbre transfer for downstream speech synthesis. VoiceSculptor achieves open-source state-of-the-art (SOTA) on InstructTTSEval-Zh, and is fully open-sourced, including code and pretrained models, to advance reproducible instruction-controlled TTS research.
FlexSpeech: Towards Stable, Controllable and Expressive Text-to-Speech
May 08, 2025Current speech generation research can be categorized into two primary classes: non-autoregressive and autoregressive. The fundamental distinction between these approaches lies in the duration prediction strategy employed for predictable-length sequences. The NAR methods ensure stability in speech generation by explicitly and independently modeling the duration of each phonetic unit. Conversely, AR methods employ an autoregressive paradigm to predict the compressed speech token by implicitly modeling duration with Markov properties. Although this approach improves prosody, it does not provide the structural guarantees necessary for stability. To simultaneously address the issues of stability and naturalness in speech generation, we propose FlexSpeech, a stable, controllable, and expressive TTS model. The motivation behind FlexSpeech is to incorporate Markov dependencies and preference optimization directly on the duration predictor to boost its naturalness while maintaining explicit modeling of the phonetic units to ensure stability. Specifically, we decompose the speech generation task into two components: an AR duration predictor and a NAR acoustic model. The acoustic model is trained on a substantial amount of data to learn to render audio more stably, given reference audio prosody and phone durations. The duration predictor is optimized in a lightweight manner for different stylistic variations, thereby enabling rapid style transfer while maintaining a decoupled relationship with the specified speaker timbre. Experimental results demonstrate that our approach achieves SOTA stability and naturalness in zero-shot TTS. More importantly, when transferring to a specific stylistic domain, we can accomplish lightweight optimization of the duration module solely with about 100 data samples, without the need to adjust the acoustic model, thereby enabling rapid and stable style transfer.
The NPU-HWC System for the ISCSLP 2024 Inspirational and Convincing Audio Generation Challenge
Oct 31, 2024This paper presents the NPU-HWC system submitted to the ISCSLP 2024 Inspirational and Convincing Audio Generation Challenge 2024 (ICAGC). Our system consists of two modules: a speech generator for Track 1 and a background audio generator for Track 2. In Track 1, we employ Single-Codec to tokenize the speech into discrete tokens and use a language-model-based approach to achieve zero-shot speaking style cloning. The Single-Codec effectively decouples timbre and speaking style at the token level, reducing the acoustic modeling burden on the autoregressive language model. Additionally, we use DSPGAN to upsample 16 kHz mel-spectrograms to high-fidelity 48 kHz waveforms. In Track 2, we propose a background audio generator based on large language models (LLMs). This system produces scene-appropriate accompaniment descriptions, synthesizes background audio with Tango 2, and integrates it with the speech generated by our Track 1 system. Our submission achieves the second place and the first place in Track 1 and Track 2 respectively.
The ISCSLP 2024 Conversational Voice Clone (CoVoC) Challenge: Tasks, Results and Findings
Oct 31, 2024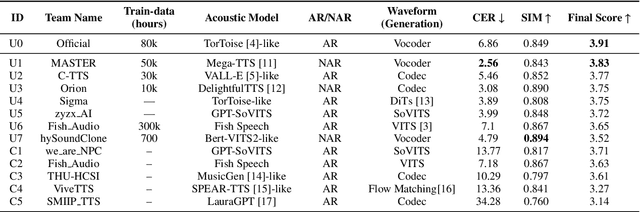
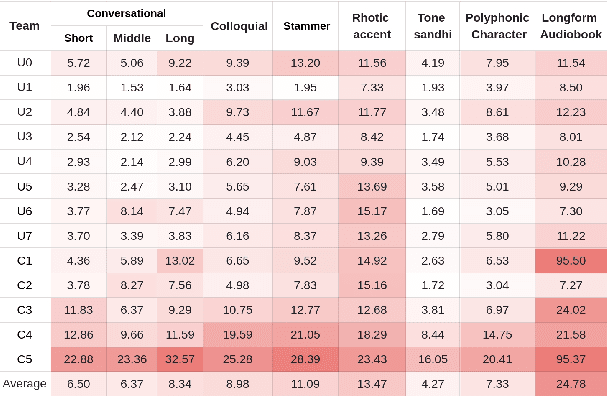
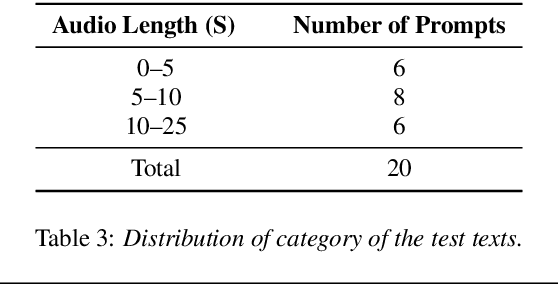
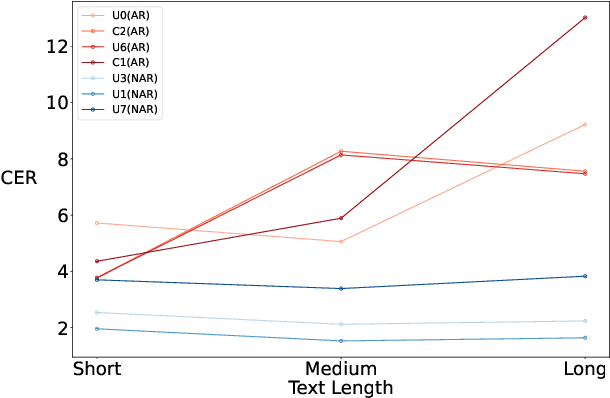
The ISCSLP 2024 Conversational Voice Clone (CoVoC) Challenge aims to benchmark and advance zero-shot spontaneous style voice cloning, particularly focusing on generating spontaneous behaviors in conversational speech. The challenge comprises two tracks: an unconstrained track without limitation on data and model usage, and a constrained track only allowing the use of constrained open-source datasets. A 100-hour high-quality conversational speech dataset is also made available with the challenge. This paper details the data, tracks, submitted systems, evaluation results, and findings.
NPU-NTU System for Voice Privacy 2024 Challenge
Sep 06, 2024

Speaker anonymization is an effective privacy protection solution that conceals the speaker's identity while preserving the linguistic content and paralinguistic information of the original speech. To establish a fair benchmark and facilitate comparison of speaker anonymization systems, the VoicePrivacy Challenge (VPC) was held in 2020 and 2022, with a new edition planned for 2024. In this paper, we describe our proposed speaker anonymization system for VPC 2024. Our system employs a disentangled neural codec architecture and a serial disentanglement strategy to gradually disentangle the global speaker identity and time-variant linguistic content and paralinguistic information. We introduce multiple distillation methods to disentangle linguistic content, speaker identity, and emotion. These methods include semantic distillation, supervised speaker distillation, and frame-level emotion distillation. Based on these distillations, we anonymize the original speaker identity using a weighted sum of a set of candidate speaker identities and a randomly generated speaker identity. Our system achieves the best trade-off of privacy protection and emotion preservation in VPC 2024.
SoCodec: A Semantic-Ordered Multi-Stream Speech Codec for Efficient Language Model Based Text-to-Speech Synthesis
Sep 02, 2024

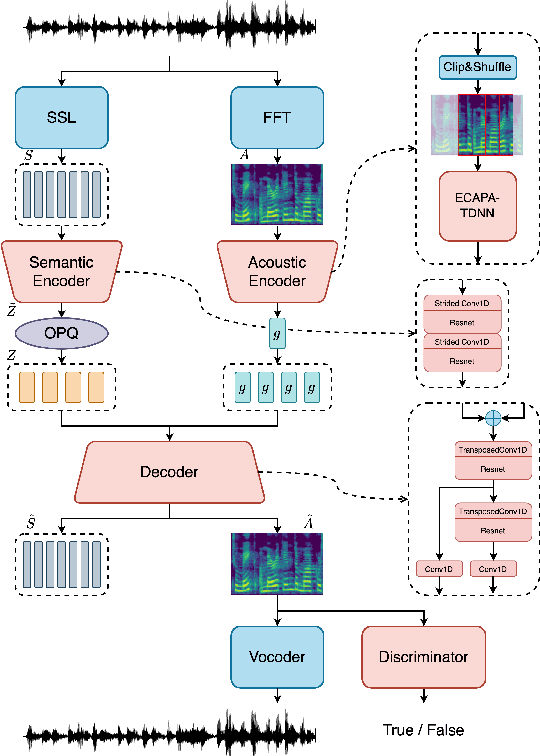

The long speech sequence has been troubling language models (LM) based TTS approaches in terms of modeling complexity and efficiency. This work proposes SoCodec, a semantic-ordered multi-stream speech codec, to address this issue. It compresses speech into a shorter, multi-stream discrete semantic sequence with multiple tokens at each frame. Meanwhile, the ordered product quantization is proposed to constrain this sequence into an ordered representation. It can be applied with a multi-stream delayed LM to achieve better autoregressive generation along both time and stream axes in TTS. The experimental result strongly demonstrates the effectiveness of the proposed approach, achieving superior performance over baseline systems even if compressing the frameshift of speech from 20ms to 240ms (12x). The ablation studies further validate the importance of learning the proposed ordered multi-stream semantic representation in pursuing shorter speech sequences for efficient LM-based TTS.
Text-aware and Context-aware Expressive Audiobook Speech Synthesis
Jun 12, 2024Recent advances in text-to-speech have significantly improved the expressiveness of synthetic speech. However, a major challenge remains in generating speech that captures the diverse styles exhibited by professional narrators in audiobooks without relying on manually labeled data or reference speech. To address this problem, we propose a text-aware and context-aware(TACA) style modeling approach for expressive audiobook speech synthesis. We first establish a text-aware style space to cover diverse styles via contrastive learning with the supervision of the speech style. Meanwhile, we adopt a context encoder to incorporate cross-sentence information and the style embedding obtained from text. Finally, we introduce the context encoder to two typical TTS models, VITS-based TTS and language model-based TTS. Experimental results demonstrate that our proposed approach can effectively capture diverse styles and coherent prosody, and consequently improves naturalness and expressiveness in audiobook speech synthesis.
WenetSpeech4TTS: A 12,800-hour Mandarin TTS Corpus for Large Speech Generation Model Benchmark
Jun 11, 2024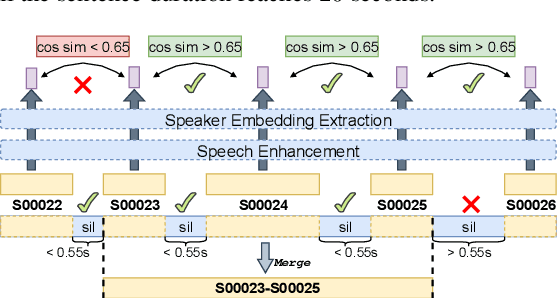
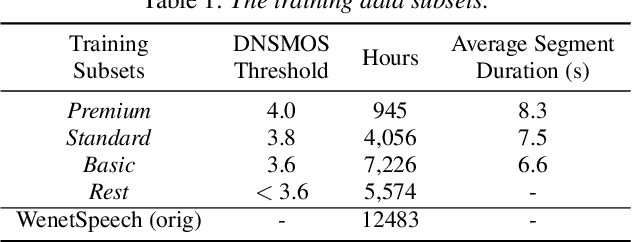
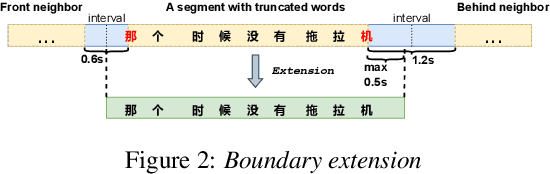
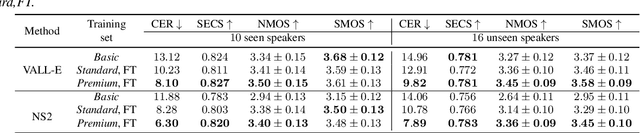
With the development of large text-to-speech (TTS) models and scale-up of the training data, state-of-the-art TTS systems have achieved impressive performance. In this paper, we present WenetSpeech4TTS, a multi-domain Mandarin corpus derived from the open-sourced WenetSpeech dataset. Tailored for the text-to-speech tasks, we refined WenetSpeech by adjusting segment boundaries, enhancing the audio quality, and eliminating speaker mixing within each segment. Following a more accurate transcription process and quality-based data filtering process, the obtained WenetSpeech4TTS corpus contains $12,800$ hours of paired audio-text data. Furthermore, we have created subsets of varying sizes, categorized by segment quality scores to allow for TTS model training and fine-tuning. VALL-E and NaturalSpeech 2 systems are trained and fine-tuned on these subsets to validate the usability of WenetSpeech4TTS, establishing baselines on benchmark for fair comparison of TTS systems. The corpus and corresponding benchmarks are publicly available on huggingface.
Automatic channel selection and spatial feature integration for multi-channel speech recognition across various array topologies
Dec 15, 2023Automatic Speech Recognition (ASR) has shown remarkable progress, yet it still faces challenges in real-world distant scenarios across various array topologies each with multiple recording devices. The focal point of the CHiME-7 Distant ASR task is to devise a unified system capable of generalizing various array topologies that have multiple recording devices and offering reliable recognition performance in real-world environments. Addressing this task, we introduce an ASR system that demonstrates exceptional performance across various array topologies. First of all, we propose two attention-based automatic channel selection modules to select the most advantageous subset of multi-channel signals from multiple recording devices for each utterance. Furthermore, we introduce inter-channel spatial features to augment the effectiveness of multi-frame cross-channel attention, aiding it in improving the capability of spatial information awareness. Finally, we propose a multi-layer convolution fusion module drawing inspiration from the U-Net architecture to integrate the multi-channel output into a single-channel output. Experimental results on the CHiME-7 corpus with oracle segmentation demonstrate that the improvements introduced in our proposed ASR system lead to a relative reduction of 40.1% in the Macro Diarization Attributed Word Error Rates (DA-WER) when compared to the baseline ASR system on the Eval sets.