 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe ICASSP 2026 Automatic Song Aesthetics Evaluation Challenge
Jan 12, 2026This paper summarizes the ICASSP 2026 Automatic Song Aesthetics Evaluation (ASAE) Challenge, which focuses on predicting the subjective aesthetic scores of AI-generated songs. The challenge consists of two tracks: Track 1 targets the prediction of the overall musicality score, while Track 2 focuses on predicting five fine-grained aesthetic scores. The challenge attracted strong interest from the research community and received numerous submissions from both academia and industry. Top-performing systems significantly surpassed the official baseline, demonstrating substantial progress in aligning objective metrics with human aesthetic preferences. The outcomes establish a standardized benchmark and advance human-aligned evaluation methodologies for modern music generation systems.
DiffRhythm 2: Efficient and High Fidelity Song Generation via Block Flow Matching
Oct 27, 2025Generating full-length, high-quality songs is challenging, as it requires maintaining long-term coherence both across text and music modalities and within the music modality itself. Existing non-autoregressive (NAR) frameworks, while capable of producing high-quality songs, often struggle with the alignment between lyrics and vocal. Concurrently, catering to diverse musical preferences necessitates reinforcement learning from human feedback (RLHF). However, existing methods often rely on merging multiple models during multi-preference optimization, which results in significant performance degradation. To address these challenges, we introduce DiffRhythm 2, an end-to-end framework designed for high-fidelity, controllable song generation. To tackle the lyric alignment problem, DiffRhythm 2 employs a semi-autoregressive architecture based on block flow matching. This design enables faithful alignment of lyrics to singing vocals without relying on external labels and constraints, all while preserving the high generation quality and efficiency of NAR models. To make this framework computationally tractable for long sequences, we implement a music variational autoencoder (VAE) that achieves a low frame rate of 5 Hz while still enabling high-fidelity audio reconstruction. In addition, to overcome the limitations of multi-preference optimization in RLHF, we propose cross-pair preference optimization. This method effectively mitigates the performance drop typically associated with model merging, allowing for more robust optimization across diverse human preferences. We further enhance musicality and structural coherence by introducing stochastic block representation alignment loss.
UniFlow: Unifying Speech Front-End Tasks via Continuous Generative Modeling
Aug 11, 2025Generative modeling has recently achieved remarkable success across image, video, and audio domains, demonstrating powerful capabilities for unified representation learning. Yet speech front-end tasks such as speech enhancement (SE), target speaker extraction (TSE), acoustic echo cancellation (AEC), and language-queried source separation (LASS) remain largely tackled by disparate, task-specific solutions. This fragmentation leads to redundant engineering effort, inconsistent performance, and limited extensibility. To address this gap, we introduce UniFlow, a unified framework that employs continuous generative modeling to tackle diverse speech front-end tasks in a shared latent space. Specifically, UniFlow utilizes a waveform variational autoencoder (VAE) to learn a compact latent representation of raw audio, coupled with a Diffusion Transformer (DiT) that predicts latent updates. To differentiate the speech processing task during the training, learnable condition embeddings indexed by a task ID are employed to enable maximal parameter sharing while preserving task-specific adaptability. To balance model performance and computational efficiency, we investigate and compare three generative objectives: denoising diffusion, flow matching, and mean flow within the latent domain. We validate UniFlow on multiple public benchmarks, demonstrating consistent gains over state-of-the-art baselines. UniFlow's unified latent formulation and conditional design make it readily extensible to new tasks, providing an integrated foundation for building and scaling generative speech processing pipelines. To foster future research, we will open-source our codebase.
EASY: Emotion-aware Speaker Anonymization via Factorized Distillation
May 21, 2025Emotion plays a significant role in speech interaction, conveyed through tone, pitch, and rhythm, enabling the expression of feelings and intentions beyond words to create a more personalized experience. However, most existing speaker anonymization systems employ parallel disentanglement methods, which only separate speech into linguistic content and speaker identity, often neglecting the preservation of the original emotional state. In this study, we introduce EASY, an emotion-aware speaker anonymization framework. EASY employs a novel sequential disentanglement process to disentangle speaker identity, linguistic content, and emotional representation, modeling each speech attribute in distinct subspaces through a factorized distillation approach. By independently constraining speaker identity and emotional representation, EASY minimizes information leakage, enhancing privacy protection while preserving original linguistic content and emotional state. Experimental results on the VoicePrivacy Challenge official datasets demonstrate that our proposed approach outperforms all baseline systems, effectively protecting speaker privacy while maintaining linguistic content and emotional state.
ClapFM-EVC: High-Fidelity and Flexible Emotional Voice Conversion with Dual Control from Natural Language and Speech
May 20, 2025



Despite great advances, achieving high-fidelity emotional voice conversion (EVC) with flexible and interpretable control remains challenging. This paper introduces ClapFM-EVC, a novel EVC framework capable of generating high-quality converted speech driven by natural language prompts or reference speech with adjustable emotion intensity. We first propose EVC-CLAP, an emotional contrastive language-audio pre-training model, guided by natural language prompts and categorical labels, to extract and align fine-grained emotional elements across speech and text modalities. Then, a FuEncoder with an adaptive intensity gate is presented to seamless fuse emotional features with Phonetic PosteriorGrams from a pre-trained ASR model. To further improve emotion expressiveness and speech naturalness, we propose a flow matching model conditioned on these captured features to reconstruct Mel-spectrogram of source speech. Subjective and objective evaluations validate the effectiveness of ClapFM-EVC.
SongEval: A Benchmark Dataset for Song Aesthetics Evaluation
May 16, 2025Aesthetics serve as an implicit and important criterion in song generation tasks that reflect human perception beyond objective metrics. However, evaluating the aesthetics of generated songs remains a fundamental challenge, as the appreciation of music is highly subjective. Existing evaluation metrics, such as embedding-based distances, are limited in reflecting the subjective and perceptual aspects that define musical appeal. To address this issue, we introduce SongEval, the first open-source, large-scale benchmark dataset for evaluating the aesthetics of full-length songs. SongEval includes over 2,399 songs in full length, summing up to more than 140 hours, with aesthetic ratings from 16 professional annotators with musical backgrounds. Each song is evaluated across five key dimensions: overall coherence, memorability, naturalness of vocal breathing and phrasing, clarity of song structure, and overall musicality. The dataset covers both English and Chinese songs, spanning nine mainstream genres. Moreover, to assess the effectiveness of song aesthetic evaluation, we conduct experiments using SongEval to predict aesthetic scores and demonstrate better performance than existing objective evaluation metrics in predicting human-perceived musical quality.
DiffRhythm: Blazingly Fast and Embarrassingly Simple End-to-End Full-Length Song Generation with Latent Diffusion
Mar 03, 2025Recent advancements in music generation have garnered significant attention, yet existing approaches face critical limitations. Some current generative models can only synthesize either the vocal track or the accompaniment track. While some models can generate combined vocal and accompaniment, they typically rely on meticulously designed multi-stage cascading architectures and intricate data pipelines, hindering scalability. Additionally, most systems are restricted to generating short musical segments rather than full-length songs. Furthermore, widely used language model-based methods suffer from slow inference speeds. To address these challenges, we propose DiffRhythm, the first latent diffusion-based song generation model capable of synthesizing complete songs with both vocal and accompaniment for durations of up to 4m45s in only ten seconds, maintaining high musicality and intelligibility. Despite its remarkable capabilities, DiffRhythm is designed to be simple and elegant: it eliminates the need for complex data preparation, employs a straightforward model structure, and requires only lyrics and a style prompt during inference. Additionally, its non-autoregressive structure ensures fast inference speeds. This simplicity guarantees the scalability of DiffRhythm. Moreover, we release the complete training code along with the pre-trained model on large-scale data to promote reproducibility and further research.
GenSE: Generative Speech Enhancement via Language Models using Hierarchical Modeling
Feb 05, 2025Semantic information refers to the meaning conveyed through words, phrases, and contextual relationships within a given linguistic structure. Humans can leverage semantic information, such as familiar linguistic patterns and contextual cues, to reconstruct incomplete or masked speech signals in noisy environments. However, existing speech enhancement (SE) approaches often overlook the rich semantic information embedded in speech, which is crucial for improving intelligibility, speaker consistency, and overall quality of enhanced speech signals. To enrich the SE model with semantic information, we employ language models as an efficient semantic learner and propose a comprehensive framework tailored for language model-based speech enhancement, called \textit{GenSE}. Specifically, we approach SE as a conditional language modeling task rather than a continuous signal regression problem defined in existing works. This is achieved by tokenizing speech signals into semantic tokens using a pre-trained self-supervised model and into acoustic tokens using a custom-designed single-quantizer neural codec model. To improve the stability of language model predictions, we propose a hierarchical modeling method that decouples the generation of clean semantic tokens and clean acoustic tokens into two distinct stages. Moreover, we introduce a token chain prompting mechanism during the acoustic token generation stage to ensure timbre consistency throughout the speech enhancement process. Experimental results on benchmark datasets demonstrate that our proposed approach outperforms state-of-the-art SE systems in terms of speech quality and generalization capability.
Fine-grained Preference Optimization Improves Zero-shot Text-to-Speech
Feb 05, 2025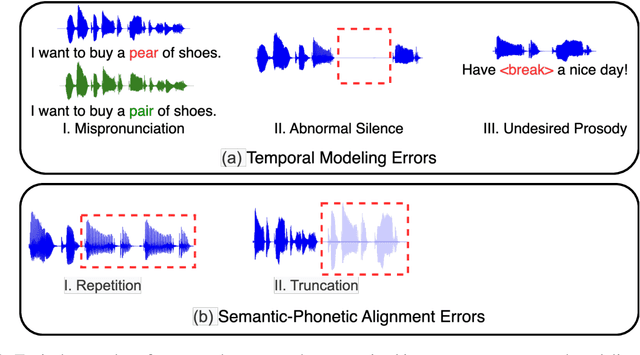
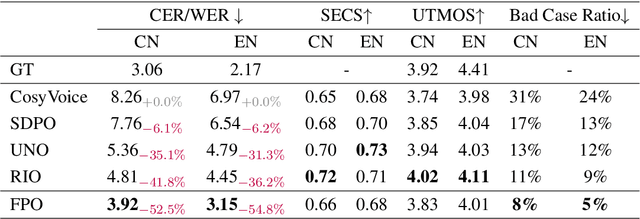
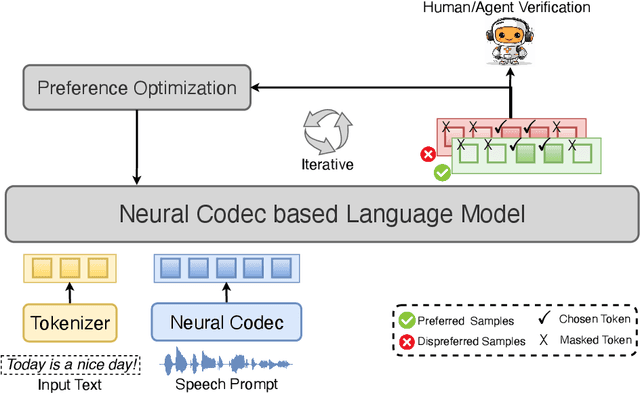
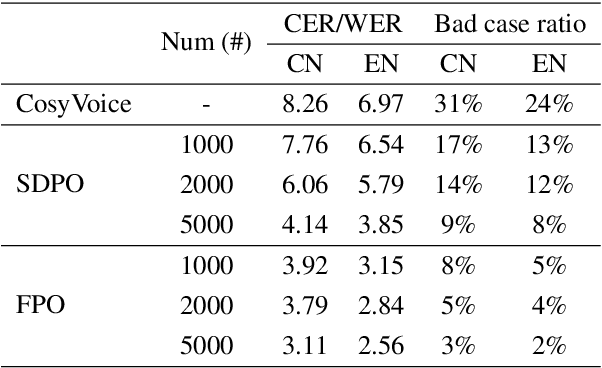
Integrating human feedback to align text-to-speech (TTS) system outputs with human preferences has proven to be an effective approach for enhancing the robustness of language model-based TTS systems. Current approaches primarily focus on using preference data annotated at the utterance level. However, frequent issues that affect the listening experience often only arise in specific segments of audio samples, while other segments are well-generated. In this study, we propose a fine-grained preference optimization approach (FPO) to enhance the robustness of TTS systems. FPO focuses on addressing localized issues in generated samples rather than uniformly optimizing the entire utterance. Specifically, we first analyze the types of issues in generated samples, categorize them into two groups, and propose a selective training loss strategy to optimize preferences based on fine-grained labels for each issue type. Experimental results show that FPO enhances the robustness of zero-shot TTS systems by effectively addressing local issues, significantly reducing the bad case ratio, and improving intelligibility. Furthermore, FPO exhibits superior data efficiency compared with baseline systems, achieving similar performance with fewer training samples.
DiffAttack: Diffusion-based Timbre-reserved Adversarial Attack in Speaker Identification
Jan 09, 2025



Being a form of biometric identification, the security of the speaker identification (SID) system is of utmost importance. To better understand the robustness of SID systems, we aim to perform more realistic attacks in SID, which are challenging for both humans and machines to detect. In this study, we propose DiffAttack, a novel timbre-reserved adversarial attack approach that exploits the capability of a diffusion-based voice conversion (DiffVC) model to generate adversarial fake audio with distinct target speaker attribution. By introducing adversarial constraints into the generative process of the diffusion-based voice conversion model, we craft fake samples that effectively mislead target models while preserving speaker-wise characteristics. Specifically, inspired by the use of randomly sampled Gaussian noise in conventional adversarial attacks and diffusion processes, we incorporate adversarial constraints into the reverse diffusion process. These constraints subtly guide the reverse diffusion process toward aligning with the target speaker distribution. Our experiments on the LibriTTS dataset indicate that DiffAttack significantly improves the attack success rate compared to vanilla DiffVC and other methods. Moreover, objective and subjective evaluations demonstrate that introducing adversarial constraints does not compromise the speech quality generated by the DiffVC model.