 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffRhythm 2: Efficient and High Fidelity Song Generation via Block Flow Matching
Oct 27, 2025Generating full-length, high-quality songs is challenging, as it requires maintaining long-term coherence both across text and music modalities and within the music modality itself. Existing non-autoregressive (NAR) frameworks, while capable of producing high-quality songs, often struggle with the alignment between lyrics and vocal. Concurrently, catering to diverse musical preferences necessitates reinforcement learning from human feedback (RLHF). However, existing methods often rely on merging multiple models during multi-preference optimization, which results in significant performance degradation. To address these challenges, we introduce DiffRhythm 2, an end-to-end framework designed for high-fidelity, controllable song generation. To tackle the lyric alignment problem, DiffRhythm 2 employs a semi-autoregressive architecture based on block flow matching. This design enables faithful alignment of lyrics to singing vocals without relying on external labels and constraints, all while preserving the high generation quality and efficiency of NAR models. To make this framework computationally tractable for long sequences, we implement a music variational autoencoder (VAE) that achieves a low frame rate of 5 Hz while still enabling high-fidelity audio reconstruction. In addition, to overcome the limitations of multi-preference optimization in RLHF, we propose cross-pair preference optimization. This method effectively mitigates the performance drop typically associated with model merging, allowing for more robust optimization across diverse human preferences. We further enhance musicality and structural coherence by introducing stochastic block representation alignment loss.
REF-VC: Robust, Expressive and Fast Zero-Shot Voice Conversion with Diffusion Transformers
Aug 07, 2025In real-world voice conversion applications, environmental noise in source speech and user demands for expressive output pose critical challenges. Traditional ASR-based methods ensure noise robustness but suppress prosody, while SSL-based models improve expressiveness but suffer from timbre leakage and noise sensitivity. This paper proposes REF-VC, a noise-robust expressive voice conversion system. Key innovations include: (1) A random erasing strategy to mitigate the information redundancy inherent in SSL feature, enhancing noise robustness and expressiveness; (2) Implicit alignment inspired by E2TTS to suppress non-essential feature reconstruction; (3) Integration of Shortcut Models to accelerate flow matching inference, significantly reducing to 4 steps. Experimental results demonstrate that our model outperforms baselines such as Seed-VC in zero-shot scenarios on the noisy set, while also performing comparably to Seed-VC on the clean set. In addition, REF-VC can be compatible with singing voice conversion within one model.
DiffRhythm: Blazingly Fast and Embarrassingly Simple End-to-End Full-Length Song Generation with Latent Diffusion
Mar 03, 2025Recent advancements in music generation have garnered significant attention, yet existing approaches face critical limitations. Some current generative models can only synthesize either the vocal track or the accompaniment track. While some models can generate combined vocal and accompaniment, they typically rely on meticulously designed multi-stage cascading architectures and intricate data pipelines, hindering scalability. Additionally, most systems are restricted to generating short musical segments rather than full-length songs. Furthermore, widely used language model-based methods suffer from slow inference speeds. To address these challenges, we propose DiffRhythm, the first latent diffusion-based song generation model capable of synthesizing complete songs with both vocal and accompaniment for durations of up to 4m45s in only ten seconds, maintaining high musicality and intelligibility. Despite its remarkable capabilities, DiffRhythm is designed to be simple and elegant: it eliminates the need for complex data preparation, employs a straightforward model structure, and requires only lyrics and a style prompt during inference. Additionally, its non-autoregressive structure ensures fast inference speeds. This simplicity guarantees the scalability of DiffRhythm. Moreover, we release the complete training code along with the pre-trained model on large-scale data to promote reproducibility and further research.
Fine-grained Preference Optimization Improves Zero-shot Text-to-Speech
Feb 05, 2025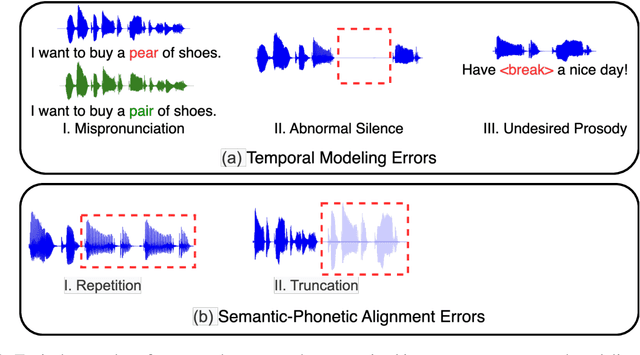
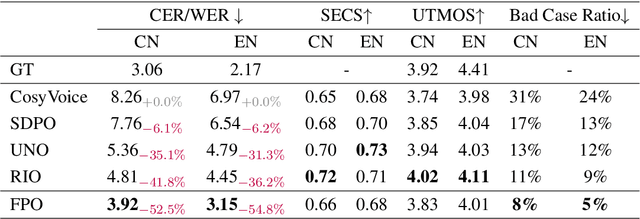
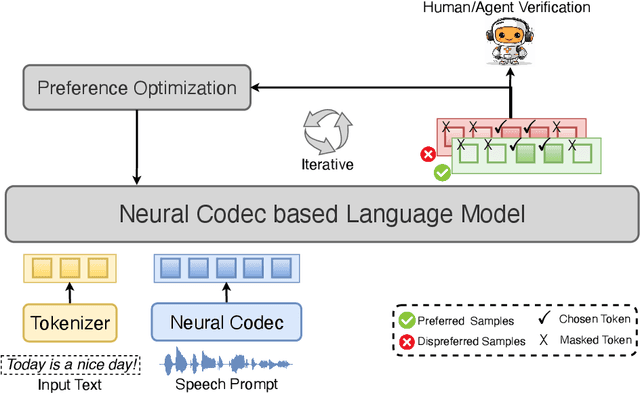
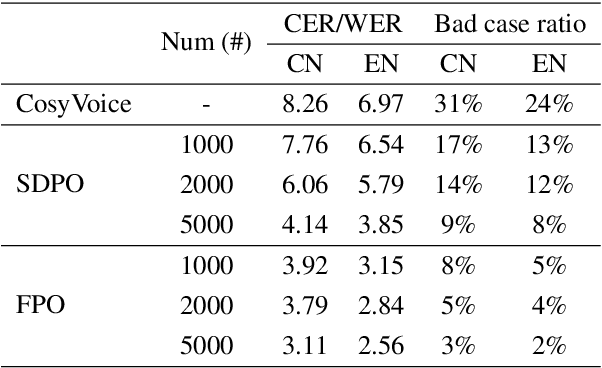
Integrating human feedback to align text-to-speech (TTS) system outputs with human preferences has proven to be an effective approach for enhancing the robustness of language model-based TTS systems. Current approaches primarily focus on using preference data annotated at the utterance level. However, frequent issues that affect the listening experience often only arise in specific segments of audio samples, while other segments are well-generated. In this study, we propose a fine-grained preference optimization approach (FPO) to enhance the robustness of TTS systems. FPO focuses on addressing localized issues in generated samples rather than uniformly optimizing the entire utterance. Specifically, we first analyze the types of issues in generated samples, categorize them into two groups, and propose a selective training loss strategy to optimize preferences based on fine-grained labels for each issue type. Experimental results show that FPO enhances the robustness of zero-shot TTS systems by effectively addressing local issues, significantly reducing the bad case ratio, and improving intelligibility. Furthermore, FPO exhibits superior data efficiency compared with baseline systems, achieving similar performance with fewer training samples.
StableVC: Style Controllable Zero-Shot Voice Conversion with Conditional Flow Matching
Dec 10, 2024



Zero-shot voice conversion (VC) aims to transfer the timbre from the source speaker to an arbitrary unseen speaker while preserving the original linguistic content. Despite recent advancements in zero-shot VC using language model-based or diffusion-based approaches, several challenges remain: 1) current approaches primarily focus on adapting timbre from unseen speakers and are unable to transfer style and timbre to different unseen speakers independently; 2) these approaches often suffer from slower inference speeds due to the autoregressive modeling methods or the need for numerous sampling steps; 3) the quality and similarity of the converted samples are still not fully satisfactory. To address these challenges, we propose a style controllable zero-shot VC approach named StableVC, which aims to transfer timbre and style from source speech to different unseen target speakers. Specifically, we decompose speech into linguistic content, timbre, and style, and then employ a conditional flow matching module to reconstruct the high-quality mel-spectrogram based on these decomposed features. To effectively capture timbre and style in a zero-shot manner, we introduce a novel dual attention mechanism with an adaptive gate, rather than using conventional feature concatenation. With this non-autoregressive design, StableVC can efficiently capture the intricate timbre and style from different unseen speakers and generate high-quality speech significantly faster than real-time. Experiments demonstrate that our proposed StableVC outperforms state-of-the-art baseline systems in zero-shot VC and achieves flexible control over timbre and style from different unseen speakers. Moreover, StableVC offers approximately 25x and 1.65x faster sampling compared to autoregressive and diffusion-based baselines.
NPU-NTU System for Voice Privacy 2024 Challenge
Sep 06, 2024

Speaker anonymization is an effective privacy protection solution that conceals the speaker's identity while preserving the linguistic content and paralinguistic information of the original speech. To establish a fair benchmark and facilitate comparison of speaker anonymization systems, the VoicePrivacy Challenge (VPC) was held in 2020 and 2022, with a new edition planned for 2024. In this paper, we describe our proposed speaker anonymization system for VPC 2024. Our system employs a disentangled neural codec architecture and a serial disentanglement strategy to gradually disentangle the global speaker identity and time-variant linguistic content and paralinguistic information. We introduce multiple distillation methods to disentangle linguistic content, speaker identity, and emotion. These methods include semantic distillation, supervised speaker distillation, and frame-level emotion distillation. Based on these distillations, we anonymize the original speaker identity using a weighted sum of a set of candidate speaker identities and a randomly generated speaker identity. Our system achieves the best trade-off of privacy protection and emotion preservation in VPC 2024.
Drop the beat! Freestyler for Accompaniment Conditioned Rapping Voice Generation
Aug 28, 2024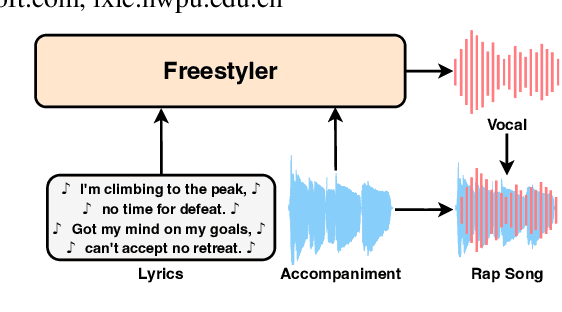

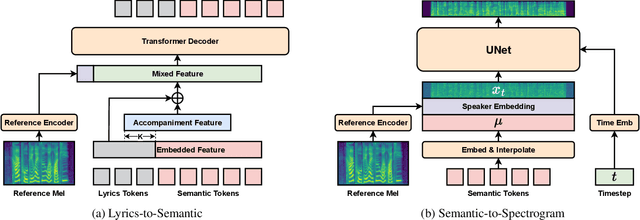
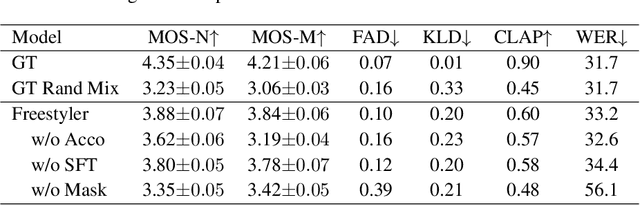
Rap, a prominent genre of vocal performance, remains underexplored in vocal generation. General vocal synthesis depends on precise note and duration inputs, requiring users to have related musical knowledge, which limits flexibility. In contrast, rap typically features simpler melodies, with a core focus on a strong rhythmic sense that harmonizes with accompanying beats. In this paper, we propose Freestyler, the first system that generates rapping vocals directly from lyrics and accompaniment inputs. Freestyler utilizes language model-based token generation, followed by a conditional flow matching model to produce spectrograms and a neural vocoder to restore audio. It allows a 3-second prompt to enable zero-shot timbre control. Due to the scarcity of publicly available rap datasets, we also present RapBank, a rap song dataset collected from the internet, alongside a meticulously designed processing pipeline. Experimental results show that Freestyler produces high-quality rapping voice generation with enhanced naturalness and strong alignment with accompanying beats, both stylistically and rhythmically.
MUSA: Multi-lingual Speaker Anonymization via Serial Disentanglement
Jul 16, 2024



Speaker anonymization is an effective privacy protection solution designed to conceal the speaker's identity while preserving the linguistic content and para-linguistic information of the original speech. While most prior studies focus solely on a single language, an ideal speaker anonymization system should be capable of handling multiple languages. This paper proposes MUSA, a Multi-lingual Speaker Anonymization approach that employs a serial disentanglement strategy to perform a step-by-step disentanglement from a global time-invariant representation to a temporal time-variant representation. By utilizing semantic distillation and self-supervised speaker distillation, the serial disentanglement strategy can avoid strong inductive biases and exhibit superior generalization performance across different languages. Meanwhile, we propose a straightforward anonymization strategy that employs empty embedding with zero values to simulate the speaker identity concealment process, eliminating the need for conversion to a pseudo-speaker identity and thereby reducing the complexity of speaker anonymization process. Experimental results on VoicePrivacy official datasets and multi-lingual datasets demonstrate that MUSA can effectively protect speaker privacy while preserving linguistic content and para-linguistic information.
DualVC 3: Leveraging Language Model Generated Pseudo Context for End-to-end Low Latency Streaming Voice Conversion
Jun 12, 2024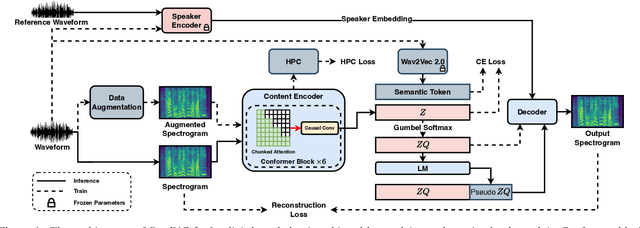
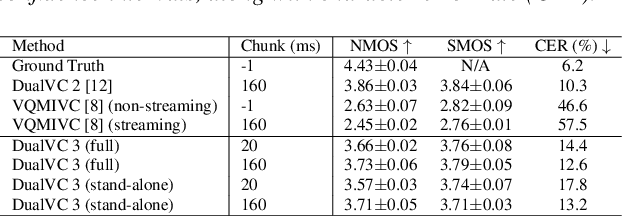
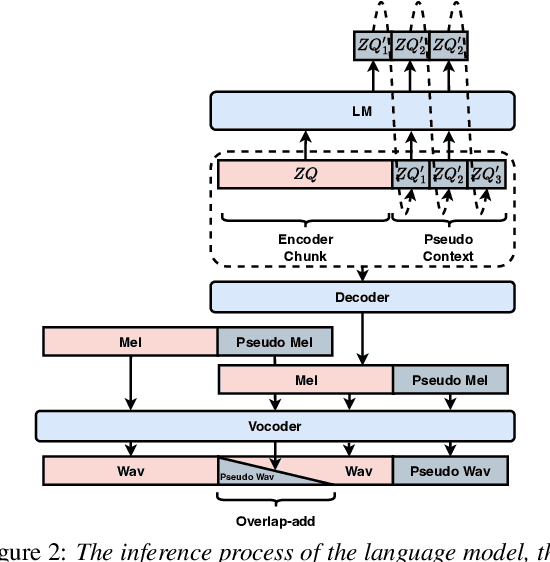
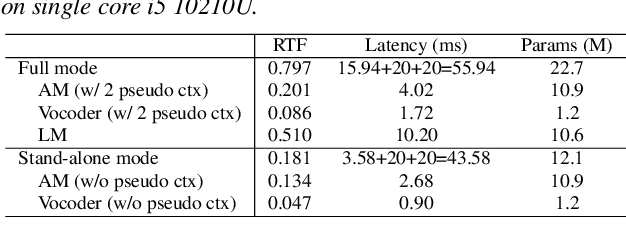
Streaming voice conversion has become increasingly popular for its potential in real-time applications. The recently proposed DualVC 2 has achieved robust and high-quality streaming voice conversion with a latency of about 180ms. Nonetheless, the recognition-synthesis framework hinders end-to-end optimization, and the instability of automatic speech recognition (ASR) model with short chunks makes it challenging to further reduce latency. To address these issues, we propose an end-to-end model, DualVC 3. With speaker-independent semantic tokens to guide the training of the content encoder, the dependency on ASR is removed and the model can operate under extremely small chunks, with cascading errors eliminated. A language model is trained on the content encoder output to produce pseudo context by iteratively predicting future frames, providing more contextual information for the decoder to improve conversion quality. Experimental results demonstrate that DualVC 3 achieves comparable performance to DualVC 2 in subjective and objective metrics, with a latency of only 50 ms.
Distinctive and Natural Speaker Anonymization via Singular Value Transformation-assisted Matrix
May 17, 2024



Speaker anonymization is an effective privacy protection solution that aims to conceal the speaker's identity while preserving the naturalness and distinctiveness of the original speech. Mainstream approaches use an utterance-level vector from a pre-trained automatic speaker verification (ASV) model to represent speaker identity, which is then averaged or modified for anonymization. However, these systems suffer from deterioration in the naturalness of anonymized speech, degradation in speaker distinctiveness, and severe privacy leakage against powerful attackers. To address these issues and especially generate more natural and distinctive anonymized speech, we propose a novel speaker anonymization approach that models a matrix related to speaker identity and transforms it into an anonymized singular value transformation-assisted matrix to conceal the original speaker identity. Our approach extracts frame-level speaker vectors from a pre-trained ASV model and employs an attention mechanism to create a speaker-score matrix and speaker-related tokens. Notably, the speaker-score matrix acts as the weight for the corresponding speaker-related token, representing the speaker's identity. The singular value transformation-assisted matrix is generated by recomposing the decomposed orthonormal eigenvectors matrix and non-linear transformed singular through Singular Value Decomposition (SVD). Experiments on VoicePrivacy Challenge datasets demonstrate the effectiveness of our approach in protecting speaker privacy under all attack scenarios while maintaining speech naturalness and distinctiveness.