 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVITS-Based Singing Voice Conversion Leveraging Whisper and multi-scale F0 Modeling
Paper and Code
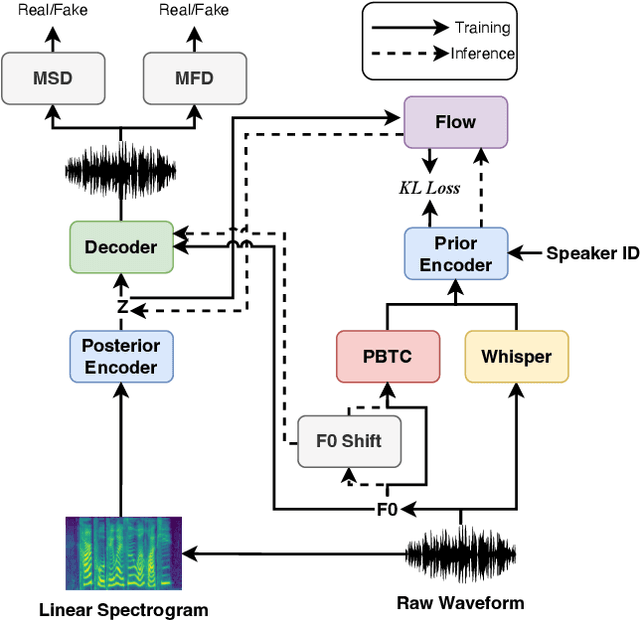
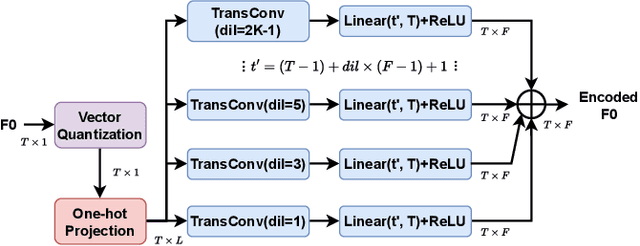
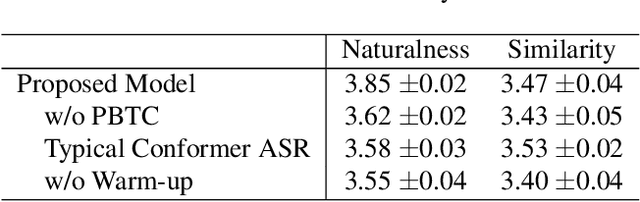
This paper introduces the T23 team's system submitted to the Singing Voice Conversion Challenge 2023. Following the recognition-synthesis framework, our singing conversion model is based on VITS, incorporating four key modules: a prior encoder, a posterior encoder, a decoder, and a parallel bank of transposed convolutions (PBTC) module. We particularly leverage Whisper, a powerful pre-trained ASR model, to extract bottleneck features (BNF) as the input of the prior encoder. Before BNF extraction, we perform pitch perturbation to the source signal to remove speaker timbre, which effectively avoids the leakage of the source speaker timbre to the target. Moreover, the PBTC module extracts multi-scale F0 as the auxiliary input to the prior encoder, thereby capturing better pitch variations of singing. We design a three-stage training strategy to better adapt the base model to the target speaker with limited target speaker data. Official challenge results show that our system has superior performance in naturalness, ranking 1st and 2nd respectively in Task 1 and 2. Further ablation justifies the effectiveness of our system design.