 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffRhythm 2: Efficient and High Fidelity Song Generation via Block Flow Matching
Oct 27, 2025Generating full-length, high-quality songs is challenging, as it requires maintaining long-term coherence both across text and music modalities and within the music modality itself. Existing non-autoregressive (NAR) frameworks, while capable of producing high-quality songs, often struggle with the alignment between lyrics and vocal. Concurrently, catering to diverse musical preferences necessitates reinforcement learning from human feedback (RLHF). However, existing methods often rely on merging multiple models during multi-preference optimization, which results in significant performance degradation. To address these challenges, we introduce DiffRhythm 2, an end-to-end framework designed for high-fidelity, controllable song generation. To tackle the lyric alignment problem, DiffRhythm 2 employs a semi-autoregressive architecture based on block flow matching. This design enables faithful alignment of lyrics to singing vocals without relying on external labels and constraints, all while preserving the high generation quality and efficiency of NAR models. To make this framework computationally tractable for long sequences, we implement a music variational autoencoder (VAE) that achieves a low frame rate of 5 Hz while still enabling high-fidelity audio reconstruction. In addition, to overcome the limitations of multi-preference optimization in RLHF, we propose cross-pair preference optimization. This method effectively mitigates the performance drop typically associated with model merging, allowing for more robust optimization across diverse human preferences. We further enhance musicality and structural coherence by introducing stochastic block representation alignment loss.
REF-VC: Robust, Expressive and Fast Zero-Shot Voice Conversion with Diffusion Transformers
Aug 07, 2025In real-world voice conversion applications, environmental noise in source speech and user demands for expressive output pose critical challenges. Traditional ASR-based methods ensure noise robustness but suppress prosody, while SSL-based models improve expressiveness but suffer from timbre leakage and noise sensitivity. This paper proposes REF-VC, a noise-robust expressive voice conversion system. Key innovations include: (1) A random erasing strategy to mitigate the information redundancy inherent in SSL feature, enhancing noise robustness and expressiveness; (2) Implicit alignment inspired by E2TTS to suppress non-essential feature reconstruction; (3) Integration of Shortcut Models to accelerate flow matching inference, significantly reducing to 4 steps. Experimental results demonstrate that our model outperforms baselines such as Seed-VC in zero-shot scenarios on the noisy set, while also performing comparably to Seed-VC on the clean set. In addition, REF-VC can be compatible with singing voice conversion within one model.
SongEval: A Benchmark Dataset for Song Aesthetics Evaluation
May 16, 2025Aesthetics serve as an implicit and important criterion in song generation tasks that reflect human perception beyond objective metrics. However, evaluating the aesthetics of generated songs remains a fundamental challenge, as the appreciation of music is highly subjective. Existing evaluation metrics, such as embedding-based distances, are limited in reflecting the subjective and perceptual aspects that define musical appeal. To address this issue, we introduce SongEval, the first open-source, large-scale benchmark dataset for evaluating the aesthetics of full-length songs. SongEval includes over 2,399 songs in full length, summing up to more than 140 hours, with aesthetic ratings from 16 professional annotators with musical backgrounds. Each song is evaluated across five key dimensions: overall coherence, memorability, naturalness of vocal breathing and phrasing, clarity of song structure, and overall musicality. The dataset covers both English and Chinese songs, spanning nine mainstream genres. Moreover, to assess the effectiveness of song aesthetic evaluation, we conduct experiments using SongEval to predict aesthetic scores and demonstrate better performance than existing objective evaluation metrics in predicting human-perceived musical quality.
DiffRhythm: Blazingly Fast and Embarrassingly Simple End-to-End Full-Length Song Generation with Latent Diffusion
Mar 03, 2025Recent advancements in music generation have garnered significant attention, yet existing approaches face critical limitations. Some current generative models can only synthesize either the vocal track or the accompaniment track. While some models can generate combined vocal and accompaniment, they typically rely on meticulously designed multi-stage cascading architectures and intricate data pipelines, hindering scalability. Additionally, most systems are restricted to generating short musical segments rather than full-length songs. Furthermore, widely used language model-based methods suffer from slow inference speeds. To address these challenges, we propose DiffRhythm, the first latent diffusion-based song generation model capable of synthesizing complete songs with both vocal and accompaniment for durations of up to 4m45s in only ten seconds, maintaining high musicality and intelligibility. Despite its remarkable capabilities, DiffRhythm is designed to be simple and elegant: it eliminates the need for complex data preparation, employs a straightforward model structure, and requires only lyrics and a style prompt during inference. Additionally, its non-autoregressive structure ensures fast inference speeds. This simplicity guarantees the scalability of DiffRhythm. Moreover, we release the complete training code along with the pre-trained model on large-scale data to promote reproducibility and further research.
Drop the beat! Freestyler for Accompaniment Conditioned Rapping Voice Generation
Aug 28, 2024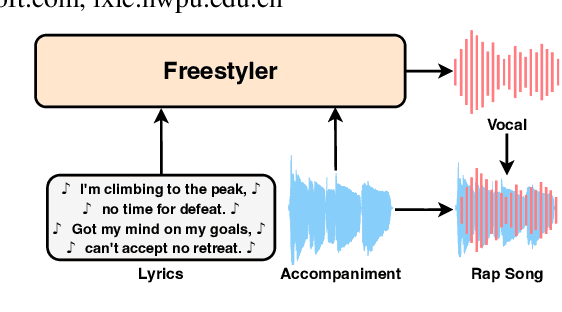

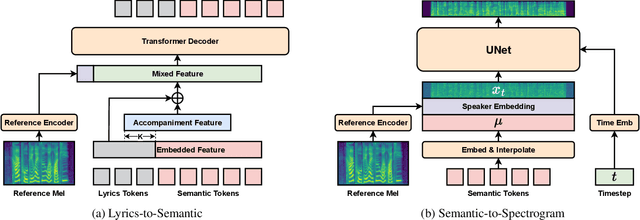
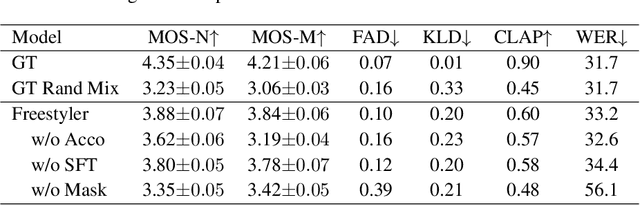
Rap, a prominent genre of vocal performance, remains underexplored in vocal generation. General vocal synthesis depends on precise note and duration inputs, requiring users to have related musical knowledge, which limits flexibility. In contrast, rap typically features simpler melodies, with a core focus on a strong rhythmic sense that harmonizes with accompanying beats. In this paper, we propose Freestyler, the first system that generates rapping vocals directly from lyrics and accompaniment inputs. Freestyler utilizes language model-based token generation, followed by a conditional flow matching model to produce spectrograms and a neural vocoder to restore audio. It allows a 3-second prompt to enable zero-shot timbre control. Due to the scarcity of publicly available rap datasets, we also present RapBank, a rap song dataset collected from the internet, alongside a meticulously designed processing pipeline. Experimental results show that Freestyler produces high-quality rapping voice generation with enhanced naturalness and strong alignment with accompanying beats, both stylistically and rhythmically.
WenetSpeech4TTS: A 12,800-hour Mandarin TTS Corpus for Large Speech Generation Model Benchmark
Jun 11, 2024
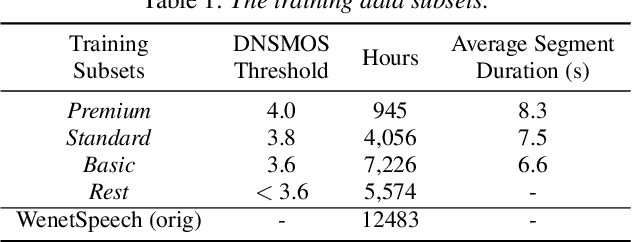
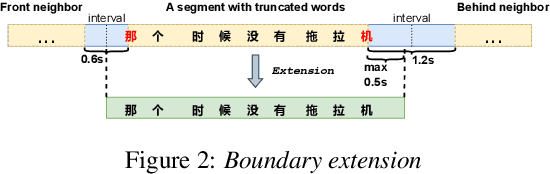
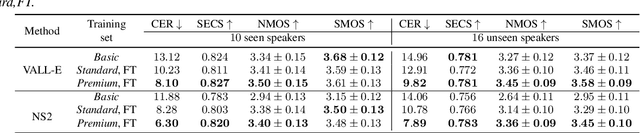
With the development of large text-to-speech (TTS) models and scale-up of the training data, state-of-the-art TTS systems have achieved impressive performance. In this paper, we present WenetSpeech4TTS, a multi-domain Mandarin corpus derived from the open-sourced WenetSpeech dataset. Tailored for the text-to-speech tasks, we refined WenetSpeech by adjusting segment boundaries, enhancing the audio quality, and eliminating speaker mixing within each segment. Following a more accurate transcription process and quality-based data filtering process, the obtained WenetSpeech4TTS corpus contains $12,800$ hours of paired audio-text data. Furthermore, we have created subsets of varying sizes, categorized by segment quality scores to allow for TTS model training and fine-tuning. VALL-E and NaturalSpeech 2 systems are trained and fine-tuned on these subsets to validate the usability of WenetSpeech4TTS, establishing baselines on benchmark for fair comparison of TTS systems. The corpus and corresponding benchmarks are publicly available on huggingface.
Towards Expressive Zero-Shot Speech Synthesis with Hierarchical Prosody Modeling
Jun 11, 2024



Recent research in zero-shot speech synthesis has made significant progress in speaker similarity. However, current efforts focus on timbre generalization rather than prosody modeling, which results in limited naturalness and expressiveness. To address this, we introduce a novel speech synthesis model trained on large-scale datasets, including both timbre and hierarchical prosody modeling. As timbre is a global attribute closely linked to expressiveness, we adopt a global vector to model speaker timbre while guiding prosody modeling. Besides, given that prosody contains both global consistency and local variations, we introduce a diffusion model as the pitch predictor and employ a prosody adaptor to model prosody hierarchically, further enhancing the prosody quality of the synthesized speech. Experimental results show that our model not only maintains comparable timbre quality to the baseline but also exhibits better naturalness and expressiveness.
VITS-Based Singing Voice Conversion Leveraging Whisper and multi-scale F0 Modeling
Oct 04, 2023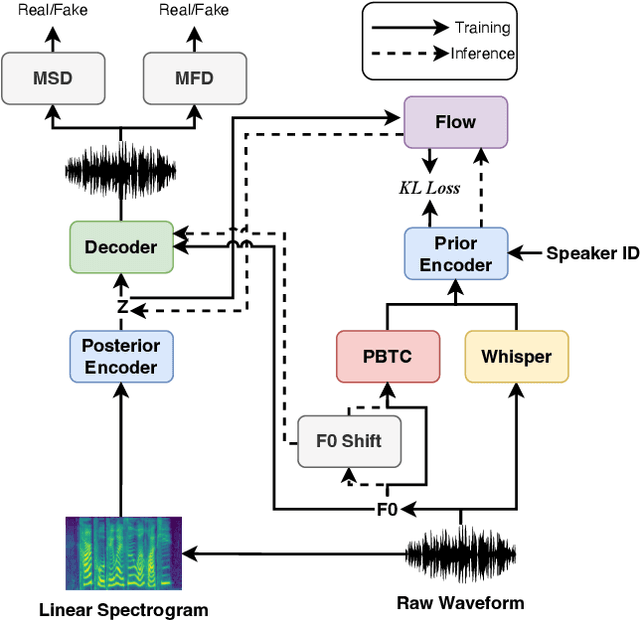
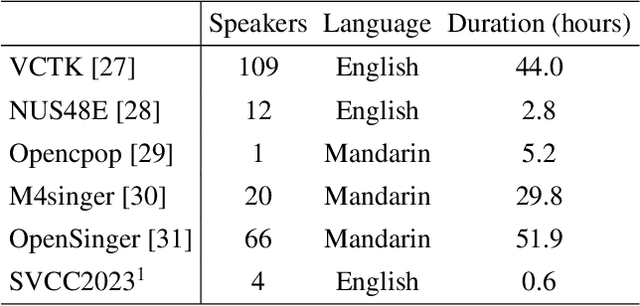
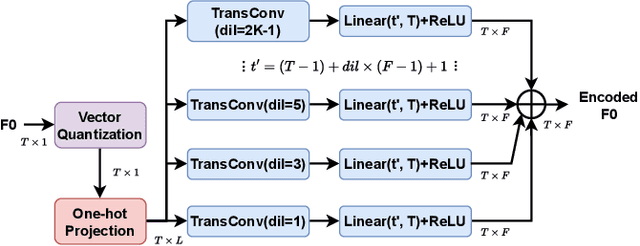
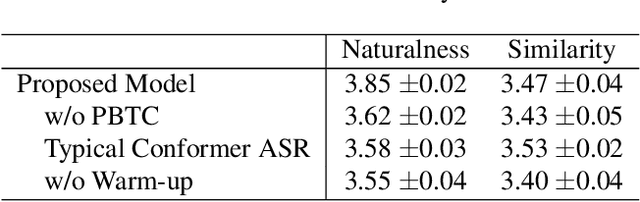
This paper introduces the T23 team's system submitted to the Singing Voice Conversion Challenge 2023. Following the recognition-synthesis framework, our singing conversion model is based on VITS, incorporating four key modules: a prior encoder, a posterior encoder, a decoder, and a parallel bank of transposed convolutions (PBTC) module. We particularly leverage Whisper, a powerful pre-trained ASR model, to extract bottleneck features (BNF) as the input of the prior encoder. Before BNF extraction, we perform pitch perturbation to the source signal to remove speaker timbre, which effectively avoids the leakage of the source speaker timbre to the target. Moreover, the PBTC module extracts multi-scale F0 as the auxiliary input to the prior encoder, thereby capturing better pitch variations of singing. We design a three-stage training strategy to better adapt the base model to the target speaker with limited target speaker data. Official challenge results show that our system has superior performance in naturalness, ranking 1st and 2nd respectively in Task 1 and 2. Further ablation justifies the effectiveness of our system design.
DualVC 2: Dynamic Masked Convolution for Unified Streaming and Non-Streaming Voice Conversion
Sep 27, 2023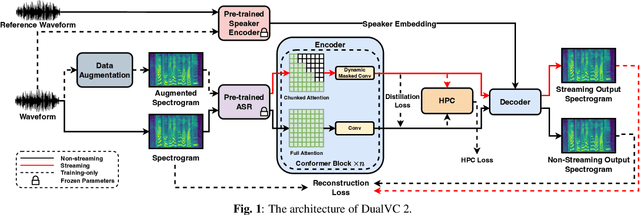
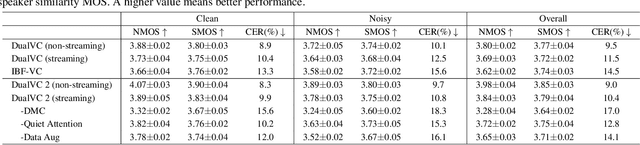
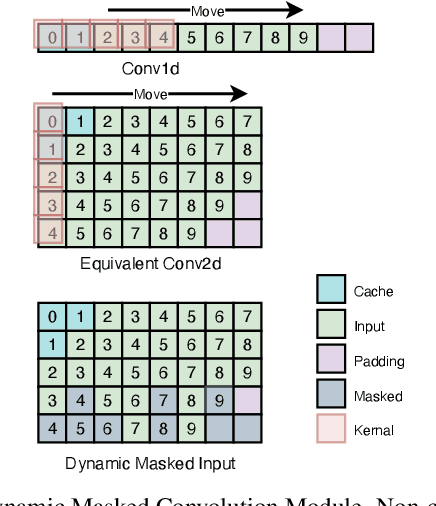
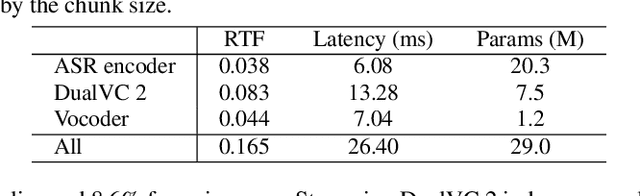
Voice conversion is becoming increasingly popular, and a growing number of application scenarios require models with streaming inference capabilities. The recently proposed DualVC attempts to achieve this objective through streaming model architecture design and intra-model knowledge distillation along with hybrid predictive coding to compensate for the lack of future information. However, DualVC encounters several problems that limit its performance. First, the autoregressive decoder has error accumulation in its nature and limits the inference speed as well. Second, the causal convolution enables streaming capability but cannot sufficiently use future information within chunks. Third, the model is unable to effectively address the noise in the unvoiced segments, lowering the sound quality. In this paper, we propose DualVC 2 to address these issues. Specifically, the model backbone is migrated to a Conformer-based architecture, empowering parallel inference. Causal convolution is replaced by non-causal convolution with dynamic chunk mask to make better use of within-chunk future information. Also, quiet attention is introduced to enhance the model's noise robustness. Experiments show that DualVC 2 outperforms DualVC and other baseline systems in both subjective and objective metrics, with only 186.4 ms latency. Our audio samples are made publicly available.
HiGNN-TTS: Hierarchical Prosody Modeling with Graph Neural Networks for Expressive Long-form TTS
Sep 25, 2023Recent advances in text-to-speech, particularly those based on Graph Neural Networks (GNNs), have significantly improved the expressiveness of short-form synthetic speech. However, generating human-parity long-form speech with high dynamic prosodic variations is still challenging. To address this problem, we expand the capabilities of GNNs with a hierarchical prosody modeling approach, named HiGNN-TTS. Specifically, we add a virtual global node in the graph to strengthen the interconnection of word nodes and introduce a contextual attention mechanism to broaden the prosody modeling scope of GNNs from intra-sentence to inter-sentence. Additionally, we perform hierarchical supervision from acoustic prosody on each node of the graph to capture the prosodic variations with a high dynamic range. Ablation studies show the effectiveness of HiGNN-TTS in learning hierarchical prosody. Both objective and subjective evaluations demonstrate that HiGNN-TTS significantly improves the naturalness and expressiveness of long-form synthetic speech