 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-view Crowd Tracking Transformer with View-Ground Interactions Under Large Real-World Scenes
Apr 21, 2026Multi-view crowd tracking estimates each person's tracking trajectories on the ground of the scene. Recent research works mainly rely on CNNs-based multi-view crowd tracking architectures, and most of them are evaluated and compared on relatively small datasets, such as Wildtrack and MultiviewX. Since these two datasets are collected in small scenes and only contain tens of frames in the evaluation stage, it is difficult for the current methods to be applied to real-world applications where scene size and occlusion are more complicated. In this paper, we propose a Transformer-based multi-view crowd tracking model, \textit{MVTrackTrans}, which adopts interactions between camera views and the ground plane for enhanced multi-view tracking performance. Besides, for better evaluation, we collect and label two large real-world multi-view tracking datasets, MVCrowdTrack and CityTrack, which contain a much larger scene size over a longer time period. Compared with existing methods on the two large and new datasets, the proposed MVTrackTrans model achieves better performance, demonstrating the advantages of the model design in dealing with large scenes. We believe the proposed datasets and model will push the frontiers of the task to more practical scenarios, and the datasets and code are available at: https://github.com/zqyq/MVTrackTrans.
Dense Point-to-Mask Optimization with Reinforced Point Selection for Crowd Instance Segmentation
Apr 02, 2026Crowd instance segmentation is a crucial task with a wide range of applications, including surveillance and transportation. Currently, point labels are common in crowd datasets, while region labels (e.g., boxes) are rare and inaccurate. The masks obtained through segmentation help to improve the accuracy of region labels and resolve the correspondence between individual location coordinates and crowd density maps. However, directly applying currently popular large foundation models such as SAM does not yield ideal results in dense crowds. To this end, we first propose Dense Point-to-Mask Optimization (DPMO), which integrates SAM with the Nearest Neighbor Exclusive Circle (NNEC) constraint to generate dense instance segmentation from point annotations. With DPMO and manual correction, we obtain mask annotations from the existing point annotations for traditional crowd datasets. Then, to predict instance segmentation in dense crowds, we propose a Reinforced Point Selection (RPS) framework trained with Group Relative Policy Optimization (GRPO), which selects the best predicted point from a sampling of the initial point prediction. Through extensive experiments, we achieve state-of-the-art crowd instance segmentation performance on ShanghaiTech, UCF-QNRF, JHU-CROWD++, and NWPU-Crowd datasets. Furthermore, we design new loss functions supervised by masks that boost counting performance across different models, demonstrating the significant role of mask annotations in enhancing counting accuracy.
M2P: Improving Visual Foundation Models with Mask-to-Point Weakly-Supervised Learning for Dense Point Tracking
Mar 18, 2026Tracking Any Point (TAP) has emerged as a fundamental tool for video understanding. Current approaches adapt Vision Foundation Models (VFMs) like DINOv2 via offline finetuning or test-time optimization. However, these VFMs rely on static image pre-training, which is inherently sub-optimal for capturing dense temporal correspondence in videos. To address this, we propose Mask-to-Point (M2P) learning, which leverages rich video object segmentation (VOS) mask annotations to improve VFMs for dense point tracking. Our M2P introduces three new mask-based constraints for weakly-supervised representation learning. First, we propose a local structure consistency loss, which leverages Procrustes analysis to model the cohesive motion of points lying within a local structure, achieving more reliable point-to-point matching learning. Second, we propose a mask label consistency (MLC) loss, which enforces that sampled foreground points strictly match foreground regions across frames. The proposed MLC loss can be regarded as a regularization, which stabilizes training and prevents convergence to trivial solutions. Finally, mask boundary constrain is applied to explicitly supervise boundary points. We show that our weaklysupervised M2P models significantly outperform baseline VFMs with efficient training by using only 3.6K VOS training videos. Notably, M2P achieves 12.8% and 14.6% performance gains over DINOv2-B/14 and DINOv3-B/16 on the TAP-Vid-DAVIS benchmark, respectively. Moreover, the proposed M2P models are used as pre-trained backbones for both test-time optimized and offline fine-tuned TAP tasks, demonstrating its potential to serve as general pre-trained models for point tracking. Code will be made publicly available upon acceptance.
Exclusivity-Guided Mask Learning for Semi-Supervised Crowd Instance Segmentation and Counting
Mar 17, 2026Semi-supervised crowd analysis is a prominent area of research, as unlabeled data are typically abundant and inexpensive to obtain. However, traditional point-based annotations constrain performance because individual regions are inherently ambiguous, and consequently, learning fine-grained structural semantics from sparse anno tations remains an unresolved challenge. In this paper, we first propose an Exclusion-Constrained Dual-Prompt SAM (EDP-SAM), based on our Nearest Neighbor Exclusion Circle (NNEC) constraint, to generate mask supervision for current datasets. With the aim of segmenting individuals in dense scenes, we then propose Exclusivity-Guided Mask Learning (XMask), which enforces spatial separation through a discriminative mask objective. Gaussian smoothing and a differentiable center sampling strategy are utilized to improve feature continuity and training stability. Building on XMask, we present a semi-supervised crowd counting framework that uses instance mask priors as pseudo-labels, which contain richer shape information than traditional point cues. Extensive experiments on the ShanghaiTech A, UCF-QNRF, and JHU++ datasets (using 5%, 10%, and 40% labeled data) verify that our end-to-end model achieves state-of-the-art semi-supervised segmentation and counting performance, effectively bridging the gap between counting and instance segmentation within a unified framework.
Video Individual Counting and Tracking from Moving Drones: A Benchmark and Methods
Jan 18, 2026Counting and tracking dense crowds in large-scale scenes is highly challenging, yet existing methods mainly rely on datasets captured by fixed cameras, which provide limited spatial coverage and are inadequate for large-scale dense crowd analysis. To address this limitation, we propose a flexible solution using moving drones to capture videos and perform video-level crowd counting and tracking of unique pedestrians across entire scenes. We introduce MovingDroneCrowd++, the largest video-level dataset for dense crowd counting and tracking captured by moving drones, covering diverse and complex conditions with varying flight altitudes, camera angles, and illumination. Existing methods fail to achieve satisfactory performance on this dataset. To this end, we propose GD3A (Global Density Map Decomposition via Descriptor Association), a density map-based video individual counting method that avoids explicit localization. GD3A establishes pixel-level correspondences between pedestrian descriptors across consecutive frames via optimal transport with an adaptive dustbin score, enabling the decomposition of global density maps into shared, inflow, and outflow components. Building on this framework, we further introduce DVTrack, which converts descriptor-level matching into instance-level associations through a descriptor voting mechanism for pedestrian tracking. Experimental results show that our methods significantly outperform existing approaches under dense crowds and complex motion, reducing counting error by 47.4 percent and improving tracking performance by 39.2 percent.
Grad-ELLM: Gradient-based Explanations for Decoder-only LLMs
Jan 06, 2026Large Language Models (LLMs) have demonstrated remarkable capabilities across diverse tasks, yet their black-box nature raises concerns about transparency and faithfulness. Input attribution methods aim to highlight each input token's contributions to the model's output, but existing approaches are typically model-agnostic, and do not focus on transformer-specific architectures, leading to limited faithfulness. To address this, we propose Grad-ELLM, a gradient-based attribution method for decoder-only transformer-based LLMs. By aggregating channel importance from gradients of the output logit with respect to attention layers and spatial importance from attention maps, Grad-ELLM generates heatmaps at each generation step without requiring architectural modifications. Additionally, we introduce two faithfulneses metrics $π$-Soft-NC and $π$-Soft-NS, which are modifications of Soft-NC/NS that provide fairer comparisons by controlling the amount of information kept when perturbing the text. We evaluate Grad-ELLM on sentiment classification, question answering, and open-generation tasks using different models. Experiment results show that Grad-ELLM consistently achieves superior faithfulness than other attribution methods.
Semi-Supervised Multi-View Crowd Counting by Ranking Multi-View Fusion Models
Dec 18, 2025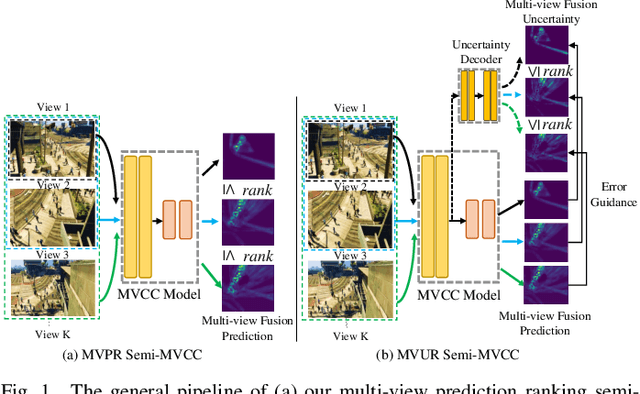
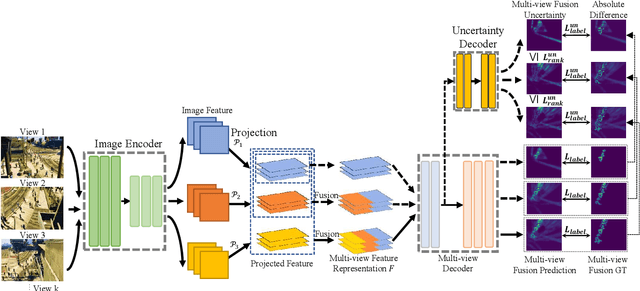

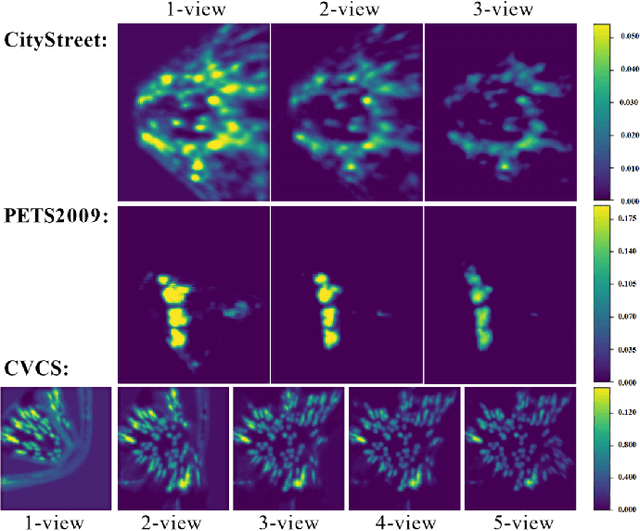
Multi-view crowd counting has been proposed to deal with the severe occlusion issue of crowd counting in large and wide scenes. However, due to the difficulty of collecting and annotating multi-view images, the datasets for multi-view counting have a limited number of multi-view frames and scenes. To solve the problem of limited data, one approach is to collect synthetic data to bypass the annotating step, while another is to propose semi- or weakly-supervised or unsupervised methods that demand less multi-view data. In this paper, we propose two semi-supervised multi-view crowd counting frameworks by ranking the multi-view fusion models of different numbers of input views, in terms of the model predictions or the model uncertainties. Specifically, for the first method (vanilla model), we rank the multi-view fusion models' prediction results of different numbers of camera-view inputs, namely, the model's predictions with fewer camera views shall not be larger than the predictions with more camera views. For the second method, we rank the estimated model uncertainties of the multi-view fusion models with a variable number of view inputs, guided by the multi-view fusion models' prediction errors, namely, the model uncertainties with more camera views shall not be larger than those with fewer camera views. These constraints are introduced into the model training in a semi-supervised fashion for multi-view counting with limited labeled data. The experiments demonstrate the advantages of the proposed multi-view model ranking methods compared with other semi-supervised counting methods.
Made-in China, Thinking in America:U.S. Values Persist in Chinese LLMs
Dec 13, 2025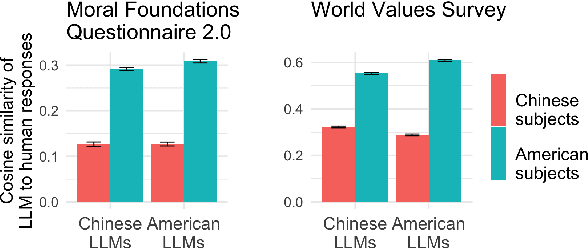
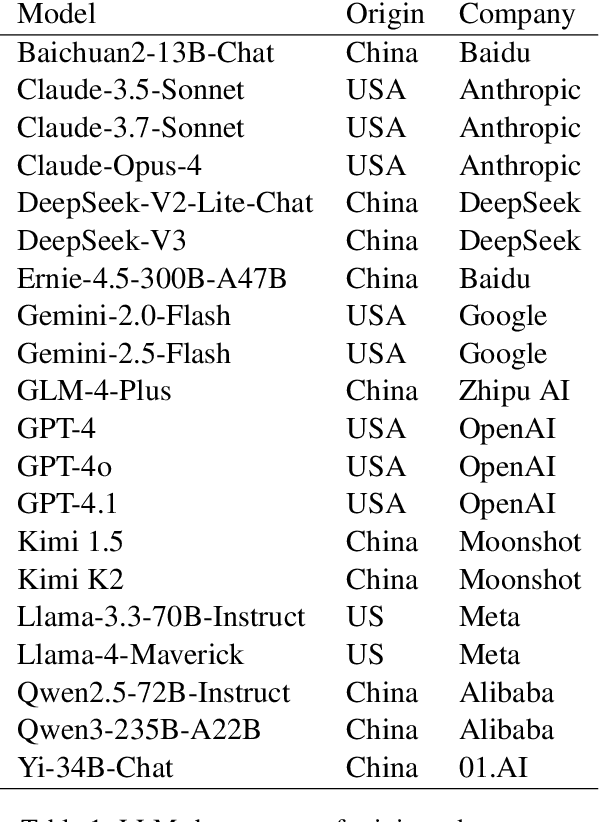
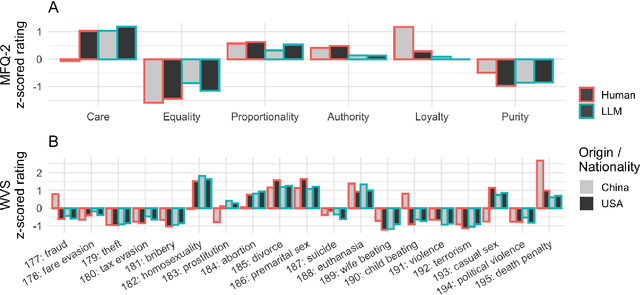
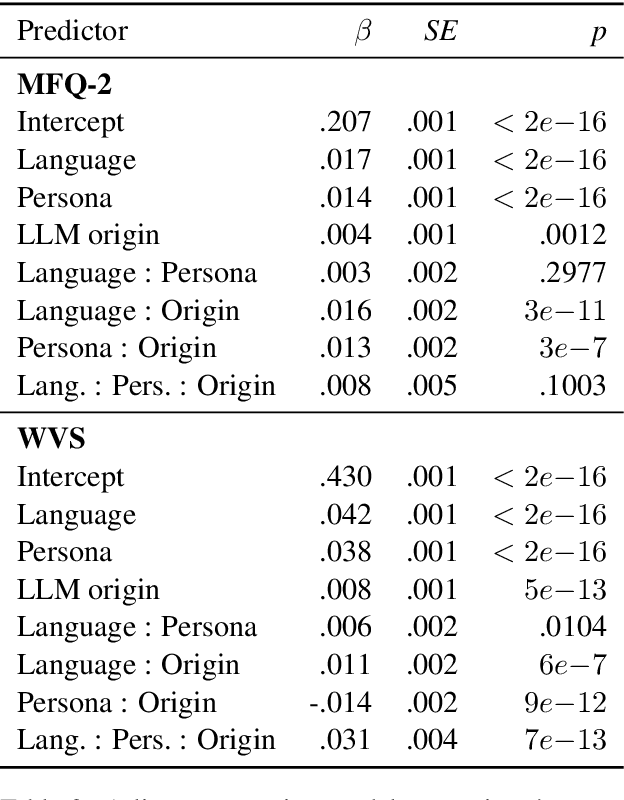
As large language models increasingly mediate access to information and facilitate decision-making, they are becoming instruments in soft power competitions between global actors such as the United States and China. So far, language models seem to be aligned with the values of Western countries, but evidence for this ethical bias comes mostly from models made by American companies. The current crop of state-of-the-art models includes several made in China, so we conducted the first large-scale investigation of how models made in China and the USA align with people from China and the USA. We elicited responses to the Moral Foundations Questionnaire 2.0 and the World Values Survey from ten Chinese models and ten American models, and we compared their responses to responses from thousands of Chinese and American people. We found that all models respond to both surveys more like American people than like Chinese people. This skew toward American values is only slightly mitigated when prompting the models in Chinese or imposing a Chinese persona on the models. These findings have important implications for a near future in which large language models generate much of the content people consume and shape normative influence in geopolitics.
ViSS-R1: Self-Supervised Reinforcement Video Reasoning
Nov 17, 2025Complex video reasoning remains a significant challenge for Multimodal Large Language Models (MLLMs), as current R1-based methodologies often prioritize text-centric reasoning derived from text-based and image-based developments. In video tasks, such strategies frequently underutilize rich visual information, leading to potential shortcut learning and increased susceptibility to hallucination. To foster a more robust, visual-centric video understanding, we start by introducing a novel self-supervised reinforcement learning GRPO algorithm (Pretext-GRPO) within the standard R1 pipeline, in which positive rewards are assigned for correctly solving pretext tasks on transformed visual inputs, which makes the model to non-trivially process the visual information. Building on the effectiveness of Pretext-GRPO, we further propose the ViSS-R1 framework, which streamlines and integrates pretext-task-based self-supervised learning directly into the MLLM's R1 post-training paradigm. Instead of relying solely on sparse visual cues, our framework compels models to reason about transformed visual input by simultaneously processing both pretext questions (concerning transformations) and true user queries. This necessitates identifying the applied transformation and reconstructing the original video to formulate accurate final answers. Comprehensive evaluations on six widely-used video reasoning and understanding benchmarks demonstrate the effectiveness and superiority of our Pretext-GRPO and ViSS-R1 for complex video reasoning. Our codes and models will be publicly available.
Temporal Unlearnable Examples: Preventing Personal Video Data from Unauthorized Exploitation by Object Tracking
Jul 10, 2025With the rise of social media, vast amounts of user-uploaded videos (e.g., YouTube) are utilized as training data for Visual Object Tracking (VOT). However, the VOT community has largely overlooked video data-privacy issues, as many private videos have been collected and used for training commercial models without authorization. To alleviate these issues, this paper presents the first investigation on preventing personal video data from unauthorized exploitation by deep trackers. Existing methods for preventing unauthorized data use primarily focus on image-based tasks (e.g., image classification), directly applying them to videos reveals several limitations, including inefficiency, limited effectiveness, and poor generalizability. To address these issues, we propose a novel generative framework for generating Temporal Unlearnable Examples (TUEs), and whose efficient computation makes it scalable for usage on large-scale video datasets. The trackers trained w/ TUEs heavily rely on unlearnable noises for temporal matching, ignoring the original data structure and thus ensuring training video data-privacy. To enhance the effectiveness of TUEs, we introduce a temporal contrastive loss, which further corrupts the learning of existing trackers when using our TUEs for training. Extensive experiments demonstrate that our approach achieves state-of-the-art performance in video data-privacy protection, with strong transferability across VOT models, datasets, and temporal matching tasks.