 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMEPIC: Memory Efficient Position Independent Caching for LLM Serving
Dec 18, 2025Modern LLM applications such as deep-research assistants, coding agents, and Retrieval-Augmented Generation (RAG) systems, repeatedly process long prompt histories containing shared document or code chunks, creating significant pressure on the Key Value (KV) cache, which must operate within limited memory while sustaining high throughput and low latency. Prefix caching partially alleviates some of these costs by reusing KV cache for previously processed tokens, but limited by strict prefix matching. Position-independent caching (PIC) enables chunk-level reuse at arbitrary positions, but requires selective recomputation and positional-encoding (PE) adjustments. However, because these operations vary across queries, KV for the same chunk diverges across requests. Moreover, without page alignment, chunk KV layouts diverge in memory, preventing page sharing. These issues result in only modest HBM savings even when many requests reuse the same content. We present MEPIC, a memory-efficient PIC system that enables chunk KV reuse across positions, requests, and batches. MEPIC aligns chunk KV to paged storage, shifts recomputation from token- to block-level so only the first block is request-specific, removes positional encodings via Rotary Position Embedding (RoPE) fusion in the attention kernel, and makes remaining blocks fully shareable. These techniques eliminate most duplicate chunk KV in HBM, reducing usage by up to 2x over state-of-the-art PIC at comparable latency and accuracy, and up to 5x for long prompts, without any model changes.
Beyond Semantic Similarity: Reducing Unnecessary API Calls via Behavior-Aligned Retriever
Aug 20, 2025Tool-augmented large language models (LLMs) leverage external functions to extend their capabilities, but inaccurate function calls can lead to inefficiencies and increased costs.Existing methods address this challenge by fine-tuning LLMs or using demonstration-based prompting, yet they often suffer from high training overhead and fail to account for inconsistent demonstration samples, which misguide the model's invocation behavior. In this paper, we trained a behavior-aligned retriever (BAR), which provides behaviorally consistent demonstrations to help LLMs make more accurate tool-using decisions. To train the BAR, we construct a corpus including different function-calling behaviors, i.e., calling or non-calling.We use the contrastive learning framework to train the BAR with customized positive/negative pairs and a dual-negative contrastive loss, ensuring robust retrieval of behaviorally consistent examples.Experiments demonstrate that our approach significantly reduces erroneous function calls while maintaining high task performance, offering a cost-effective and efficient solution for tool-augmented LLMs.
Enhancing Learned Knowledge in LoRA Adapters Through Efficient Contrastive Decoding on Ascend NPUs
May 20, 2025Huawei Cloud users leverage LoRA (Low-Rank Adaptation) as an efficient and scalable method to fine-tune and customize large language models (LLMs) for application-specific needs. However, tasks that require complex reasoning or deep contextual understanding are often hindered by biases or interference from the base model when using typical decoding methods like greedy or beam search. These biases can lead to generic or task-agnostic responses from the base model instead of leveraging the LoRA-specific adaptations. In this paper, we introduce Contrastive LoRA Decoding (CoLD), a novel decoding framework designed to maximize the use of task-specific knowledge in LoRA-adapted models, resulting in better downstream performance. CoLD uses contrastive decoding by scoring candidate tokens based on the divergence between the probability distributions of a LoRA-adapted expert model and the corresponding base model. This approach prioritizes tokens that better align with the LoRA's learned representations, enhancing performance for specialized tasks. While effective, a naive implementation of CoLD is computationally expensive because each decoding step requires evaluating multiple token candidates across both models. To address this, we developed an optimized kernel for Huawei's Ascend NPU. CoLD achieves up to a 5.54% increase in task accuracy while reducing end-to-end latency by 28% compared to greedy decoding. This work provides practical and efficient decoding strategies for fine-tuned LLMs in resource-constrained environments and has broad implications for applied data science in both cloud and on-premises settings.
EvoP: Robust LLM Inference via Evolutionary Pruning
Feb 19, 2025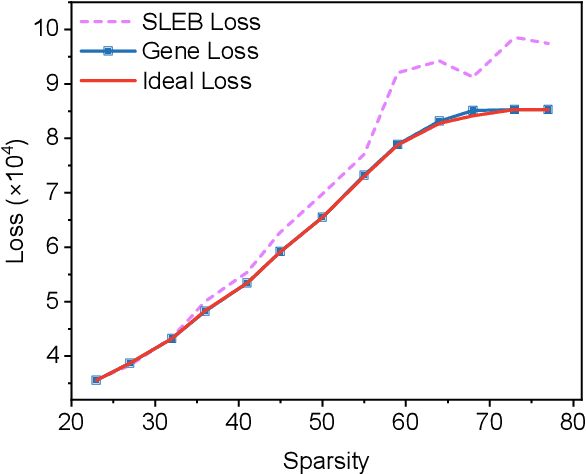
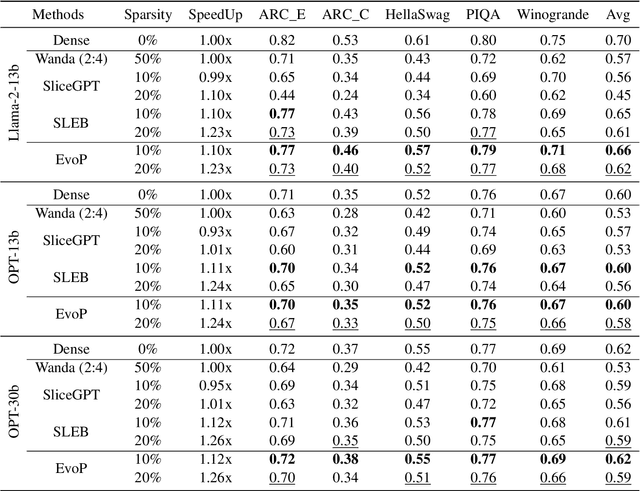
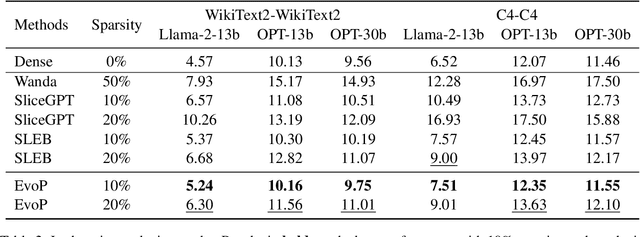
Large Language Models (LLMs) have achieved remarkable success in natural language processing tasks, but their massive size and computational demands hinder their deployment in resource-constrained environments. Existing structured pruning methods address this issue by removing redundant structures (e.g., elements, channels, layers) from the model. However, these methods employ a heuristic pruning strategy, which leads to suboptimal performance. Besides, they also ignore the data characteristics when pruning the model. To overcome these limitations, we propose EvoP, an evolutionary pruning framework for robust LLM inference. EvoP first presents a cluster-based calibration dataset sampling (CCDS) strategy for creating a more diverse calibration dataset. EvoP then introduces an evolutionary pruning pattern searching (EPPS) method to find the optimal pruning pattern. Compared to existing structured pruning techniques, EvoP achieves the best performance while maintaining the best efficiency. Experiments across different LLMs and different downstream tasks validate the effectiveness of the proposed EvoP, making it a practical and scalable solution for deploying LLMs in real-world applications.
GeneQuery: A General QA-based Framework for Spatial Gene Expression Predictions from Histology Images
Nov 27, 2024



Gene expression profiling provides profound insights into molecular mechanisms, but its time-consuming and costly nature often presents significant challenges. In contrast, whole-slide hematoxylin and eosin (H&E) stained histological images are readily accessible and allow for detailed examinations of tissue structure and composition at the microscopic level. Recent advancements have utilized these histological images to predict spatially resolved gene expression profiles. However, state-of-the-art works treat gene expression prediction as a multi-output regression problem, where each gene is learned independently with its own weights, failing to capture the shared dependencies and co-expression patterns between genes. Besides, existing works can only predict gene expression values for genes seen during training, limiting their ability to generalize to new, unseen genes. To address the above limitations, this paper presents GeneQuery, which aims to solve this gene expression prediction task in a question-answering (QA) manner for better generality and flexibility. Specifically, GeneQuery takes gene-related texts as queries and whole-slide images as contexts and then predicts the queried gene expression values. With such a transformation, GeneQuery can implicitly estimate the gene distribution by introducing the gene random variable. Besides, the proposed GeneQuery consists of two architecture implementations, i.e., spot-aware GeneQuery for capturing patterns between images and gene-aware GeneQuery for capturing patterns between genes. Comprehensive experiments on spatial transcriptomics datasets show that the proposed GeneQuery outperforms existing state-of-the-art methods on known and unseen genes. More results also demonstrate that GeneQuery can potentially analyze the tissue structure.
FAST: A Dual-tier Few-Shot Learning Paradigm for Whole Slide Image Classification
Sep 29, 2024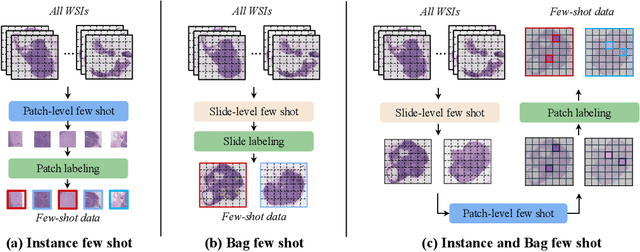
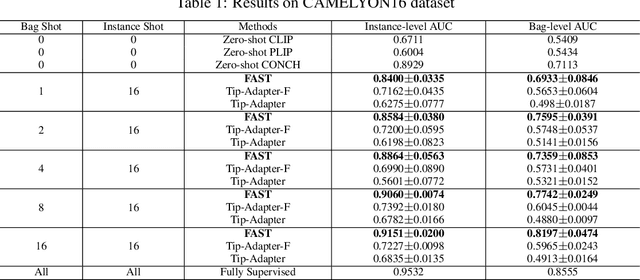
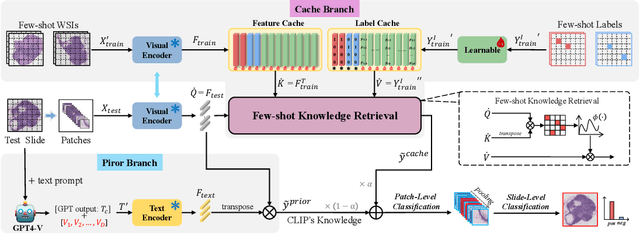
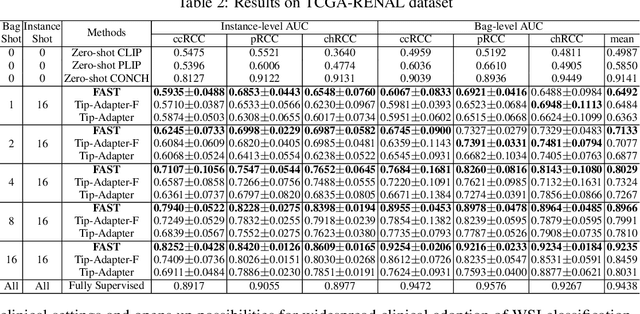
The expensive fine-grained annotation and data scarcity have become the primary obstacles for the widespread adoption of deep learning-based Whole Slide Images (WSI) classification algorithms in clinical practice. Unlike few-shot learning methods in natural images that can leverage the labels of each image, existing few-shot WSI classification methods only utilize a small number of fine-grained labels or weakly supervised slide labels for training in order to avoid expensive fine-grained annotation. They lack sufficient mining of available WSIs, severely limiting WSI classification performance. To address the above issues, we propose a novel and efficient dual-tier few-shot learning paradigm for WSI classification, named FAST. FAST consists of a dual-level annotation strategy and a dual-branch classification framework. Firstly, to avoid expensive fine-grained annotation, we collect a very small number of WSIs at the slide level, and annotate an extremely small number of patches. Then, to fully mining the available WSIs, we use all the patches and available patch labels to build a cache branch, which utilizes the labeled patches to learn the labels of unlabeled patches and through knowledge retrieval for patch classification. In addition to the cache branch, we also construct a prior branch that includes learnable prompt vectors, using the text encoder of visual-language models for patch classification. Finally, we integrate the results from both branches to achieve WSI classification. Extensive experiments on binary and multi-class datasets demonstrate that our proposed method significantly surpasses existing few-shot classification methods and approaches the accuracy of fully supervised methods with only 0.22$\%$ annotation costs. All codes and models will be publicly available on https://github.com/fukexue/FAST.
Retrieval-Augmented Generation for Natural Language Processing: A Survey
Jul 19, 2024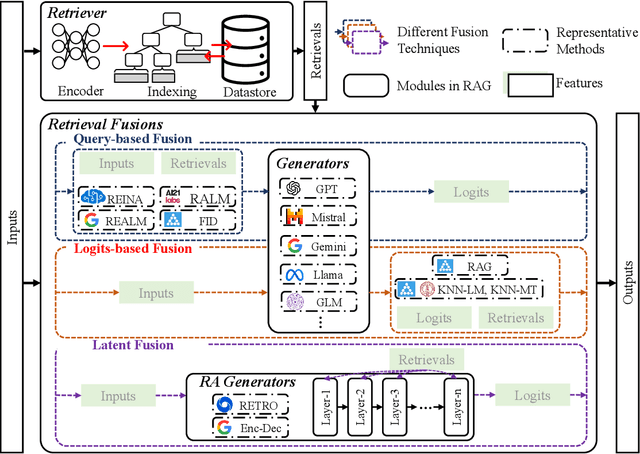
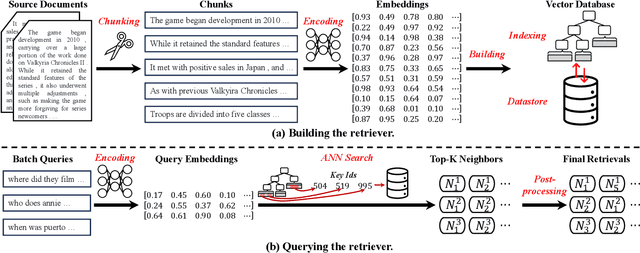
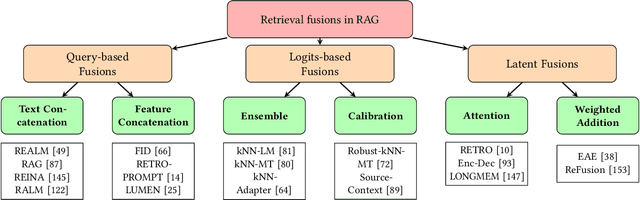
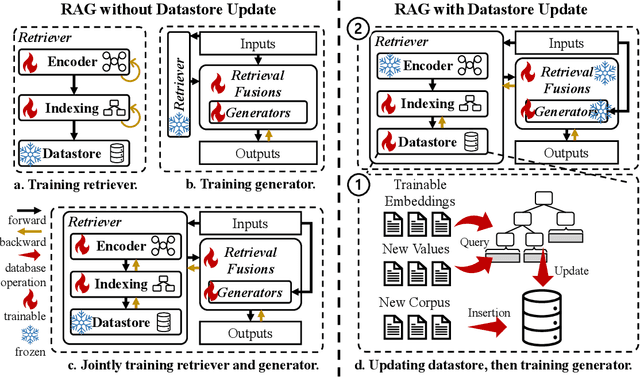
Large language models (LLMs) have demonstrated great success in various fields, benefiting from their huge amount of parameters that store knowledge. However, LLMs still suffer from several key issues, such as hallucination problems, knowledge update issues, and lacking domain-specific expertise. The appearance of retrieval-augmented generation (RAG), which leverages an external knowledge database to augment LLMs, makes up those drawbacks of LLMs. This paper reviews all significant techniques of RAG, especially in the retriever and the retrieval fusions. Besides, tutorial codes are provided for implementing the representative techniques in RAG. This paper further discusses the RAG training, including RAG with/without datastore update. Then, we introduce the application of RAG in representative natural language processing tasks and industrial scenarios. Finally, this paper discusses the future directions and challenges of RAG for promoting its development.
RAEE: A Training-Free Retrieval-Augmented Early Exiting Framework for Efficient Inference
May 24, 2024



Deploying large language model inference remains challenging due to their high computational overhead. Early exiting accelerates model inference by adaptively reducing the number of inference layers. Existing methods require training internal classifiers to determine whether to exit at each intermediate layer. However, such classifier-based early exiting frameworks require significant effort to design and train the classifiers. To address these limitations, this paper proposes RAEE, a training-free Retrieval-Augmented Early Exiting framework for efficient inference. First, this paper demonstrates that the early exiting problem can be modeled as a distribution prediction problem, where the distribution is approximated using similar data's existing information. Next, the paper details the process of collecting existing information to build the retrieval database. Finally, based on the pre-built retrieval database, RAEE leverages the retrieved similar data's exiting information to guide the backbone model to exit at the layer, which is predicted by the approximated distribution. Experimental results demonstrate that the proposed RAEE can significantly accelerate inference. RAEE also achieves state-of-the-art zero-shot performance on 8 classification tasks.
Improving Natural Language Understanding with Computation-Efficient Retrieval Representation Fusion
Jan 04, 2024Retrieval-based augmentations that aim to incorporate knowledge from an external database into language models have achieved great success in various knowledge-intensive (KI) tasks, such as question-answering and text generation. However, integrating retrievals in non-knowledge-intensive (NKI) tasks, such as text classification, is still challenging. Existing works focus on concatenating retrievals to inputs as context to form the prompt-based inputs. Unfortunately, such methods require language models to have the capability to handle long texts. Besides, inferring such concatenated data would also consume a significant amount of computational resources. To solve these challenges, we propose \textbf{ReFusion} in this paper, a computation-efficient \textbf{Re}trieval representation \textbf{Fusion} with neural architecture search. The main idea is to directly fuse the retrieval representations into the language models. Specifically, we first propose an online retrieval module that retrieves representations of similar sentences. Then, we present a retrieval fusion module including two effective ranking schemes, i.e., reranker-based scheme and ordered-mask-based scheme, to fuse the retrieval representations with hidden states. Furthermore, we use Neural Architecture Search (NAS) to seek the optimal fusion structure across different layers. Finally, we conduct comprehensive experiments, and the results demonstrate our ReFusion can achieve superior and robust performance on various NKI tasks.
Wideband Power Spectrum Sensing: a Fast Practical Solution for Nyquist Folding Receiver
Aug 14, 2023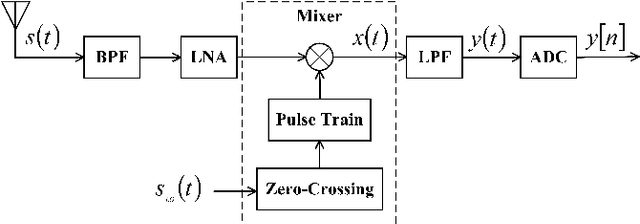
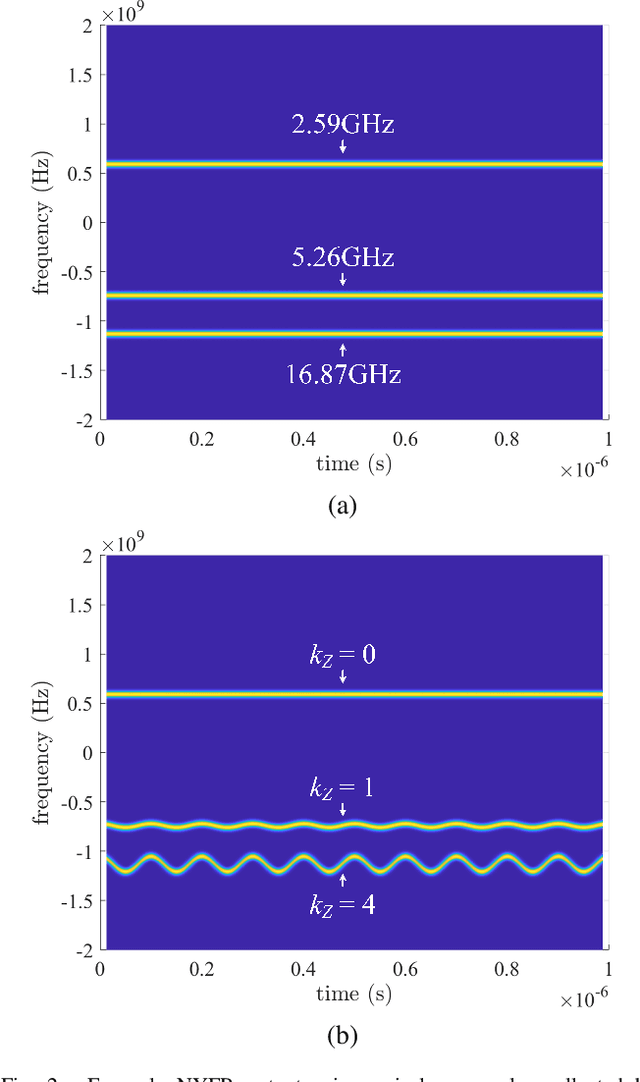
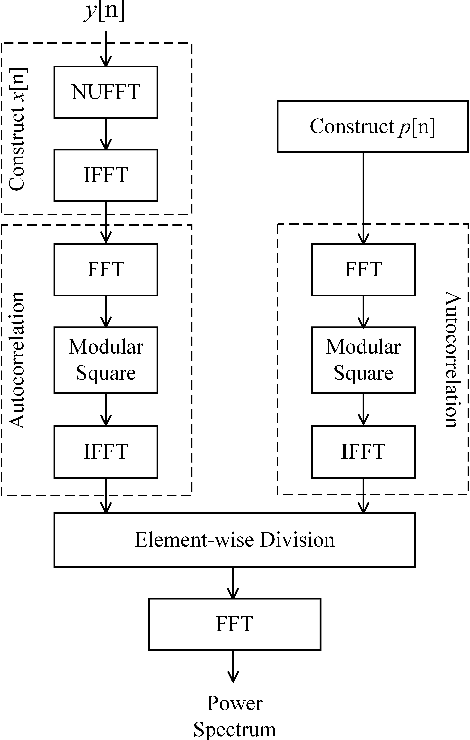
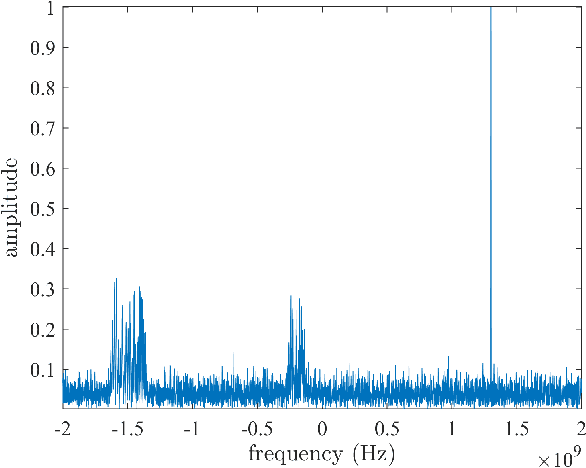
The limited availability of spectrum resources has been growing into a critical problem in wireless communications, remote sensing, and electronic surveillance, etc. To address the high-speed sampling bottleneck of wideband spectrum sensing, a fast and practical solution of power spectrum estimation for Nyquist folding receiver (NYFR) is proposed in this paper. The NYFR architectures is can theoretically achieve the full-band signal sensing with a hundred percent of probability of intercept. But the existing algorithm is difficult to realize in real-time due to its high complexity and complicated calculations. By exploring the sub-sampling principle inherent in NYFR, a computationally efficient method is introduced with compressive covariance sensing. That can be efficient implemented via only the non-uniform fast Fourier transform, fast Fourier transform, and some simple multiplication operations. Meanwhile, the state-of-the-art power spectrum reconstruction model for NYFR of time-domain and frequency-domain is constructed in this paper as a comparison. Furthermore, the computational complexity of the proposed method scales linearly with the Nyquist-rate sampled number of samples and the sparsity of spectrum occupancy. Simulation results and discussion demonstrate that the low complexity in sampling and computation is a more practical solution to meet the real-time wideband spectrum sensing applications.