 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightSeq2: Accelerated Training for Transformer-based Models on GPUs
Paper and Code
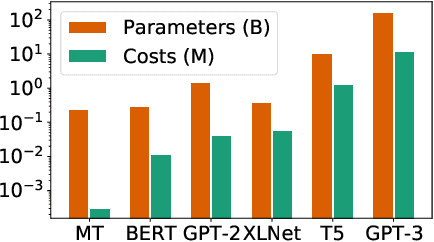

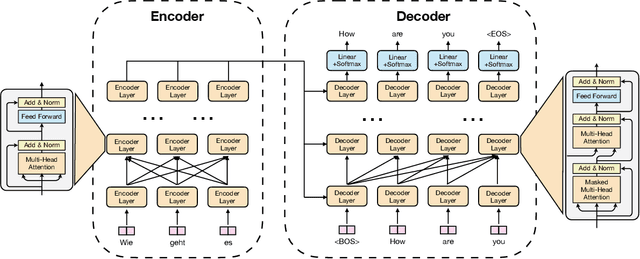
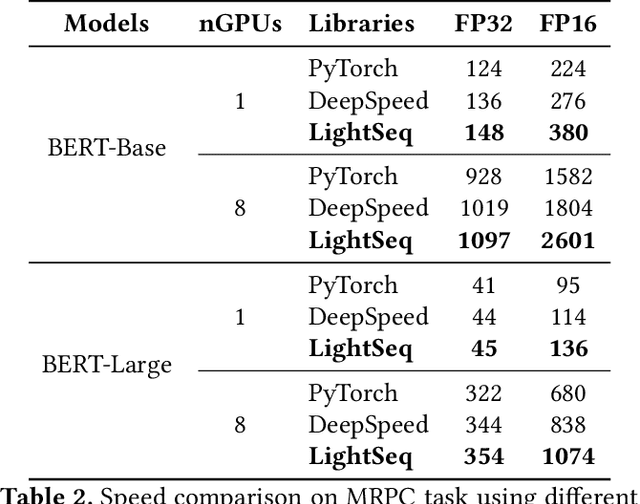
Transformer-based models have proven to be powerful in many natural language, computer vision, and speech recognition applications. It is expensive to train these types of models due to unfixed input length, complex computation, and large numbers of parameters. Existing systems either only focus on efficient inference or optimize only BERT-like encoder models. In this paper, we present LightSeq2, a system for efficient training of Transformer-based models on GPUs. We propose a series of GPU optimization techniques tailored to computation flow and memory access patterns of neural layers in Transformers. LightSeq2 supports a variety of network architectures, including BERT (encoder-only), GPT (decoder-only), and Transformer (encoder-decoder). Our experiments on GPUs with varying models and datasets show that LightSeq2 is 1.4-3.5x faster than previous systems. In particular, it gains 308% training speedup compared with existing systems on a large public machine translation benchmark (WMT14 English-German).