 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCUDA Agent: Large-Scale Agentic RL for High-Performance CUDA Kernel Generation
Feb 27, 2026GPU kernel optimization is fundamental to modern deep learning but remains a highly specialized task requiring deep hardware expertise. Despite strong performance in general programming, large language models (LLMs) remain uncompetitive with compiler-based systems such as torch.compile for CUDA kernel generation. Existing CUDA code generation approaches either rely on training-free refinement or fine-tune models within fixed multi-turn execution-feedback loops, but both paradigms fail to fundamentally improve the model's intrinsic CUDA optimization ability, resulting in limited performance gains. We present CUDA Agent, a large-scale agentic reinforcement learning system that develops CUDA kernel expertise through three components: a scalable data synthesis pipeline, a skill-augmented CUDA development environment with automated verification and profiling to provide reliable reward signals, and reinforcement learning algorithmic techniques enabling stable training. CUDA Agent achieves state-of-the-art results on KernelBench, delivering 100\%, 100\%, and 92\% faster rate over torch.compile on KernelBench Level-1, Level-2, and Level-3 splits, outperforming the strongest proprietary models such as Claude Opus 4.5 and Gemini 3 Pro by about 40\% on the hardest Level-3 setting.
BABE: Biology Arena BEnchmark
Feb 05, 2026The rapid evolution of large language models (LLMs) has expanded their capabilities from basic dialogue to advanced scientific reasoning. However, existing benchmarks in biology often fail to assess a critical skill required of researchers: the ability to integrate experimental results with contextual knowledge to derive meaningful conclusions. To address this gap, we introduce BABE(Biology Arena BEnchmark), a comprehensive benchmark designed to evaluate the experimental reasoning capabilities of biological AI systems. BABE is uniquely constructed from peer-reviewed research papers and real-world biological studies, ensuring that tasks reflect the complexity and interdisciplinary nature of actual scientific inquiry. BABE challenges models to perform causal reasoning and cross-scale inference. Our benchmark provides a robust framework for assessing how well AI systems can reason like practicing scientists, offering a more authentic measure of their potential to contribute to biological research.
ScDiVa: Masked Discrete Diffusion for Joint Modeling of Single-Cell Identity and Expression
Feb 03, 2026Single-cell RNA-seq profiles are high-dimensional, sparse, and unordered, causing autoregressive generation to impose an artificial ordering bias and suffer from error accumulation. To address this, we propose scDiVa, a masked discrete diffusion foundation model that aligns generation with the dropout-like corruption process by defining a continuous-time forward masking mechanism in token space. ScDiVa features a bidirectional denoiser that jointly models discrete gene identities and continuous values, utilizing entropy-normalized serialization and a latent anchor token to maximize information efficiency and preserve global cell identity. The model is trained via depth-invariant time sampling and a dual denoising objective to simulate varying sparsity levels while ensuring precise recovery of both identity and magnitude. Pre-trained on 59 million cells, scDiVa achieves strong transfer performance across major benchmarks, including batch integration, cell type annotation, and perturbation response prediction. These results suggest that masked discrete diffusion serves as a biologically coherent and effective alternative to autoregression.
MathDoc: Benchmarking Structured Extraction and Active Refusal on Noisy Mathematics Exam Papers
Jan 15, 2026The automated extraction of structured questions from paper-based mathematics exams is fundamental to intelligent education, yet remains challenging in real-world settings due to severe visual noise. Existing benchmarks mainly focus on clean documents or generic layout analysis, overlooking both the structural integrity of mathematical problems and the ability of models to actively reject incomplete inputs. We introduce MathDoc, the first benchmark for document-level information extraction from authentic high school mathematics exam papers. MathDoc contains \textbf{3,609} carefully curated questions with real-world artifacts and explicitly includes unrecognizable samples to evaluate active refusal behavior. We propose a multi-dimensional evaluation framework covering stem accuracy, visual similarity, and refusal capability. Experiments on SOTA MLLMs, including Qwen3-VL and Gemini-2.5-Pro, show that although end-to-end models achieve strong extraction performance, they consistently fail to refuse illegible inputs, instead producing confident but invalid outputs. These results highlight a critical gap in current MLLMs and establish MathDoc as a benchmark for assessing model reliability under degraded document conditions. Our project repository is available at \href{https://github.com/winnk123/papers/tree/master}{GitHub repository}
OpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
Seed-Prover 1.5: Mastering Undergraduate-Level Theorem Proving via Learning from Experience
Dec 19, 2025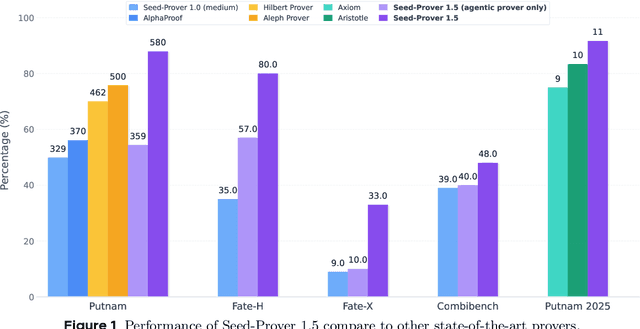

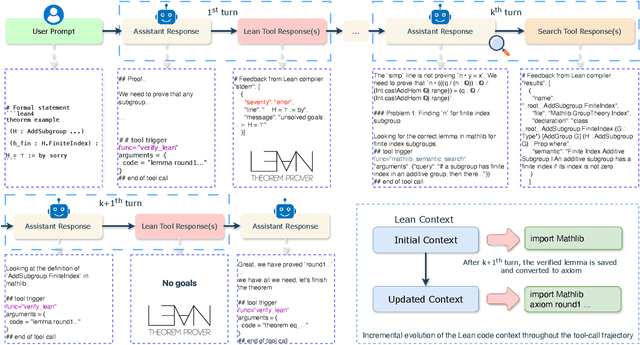

Large language models have recently made significant progress to generate rigorous mathematical proofs. In contrast, utilizing LLMs for theorem proving in formal languages (such as Lean) remains challenging and computationally expensive, particularly when addressing problems at the undergraduate level and beyond. In this work, we present \textbf{Seed-Prover 1.5}, a formal theorem-proving model trained via large-scale agentic reinforcement learning, alongside an efficient test-time scaling (TTS) workflow. Through extensive interactions with Lean and other tools, the model continuously accumulates experience during the RL process, substantially enhancing the capability and efficiency of formal theorem proving. Furthermore, leveraging recent advancements in natural language proving, our TTS workflow efficiently bridges the gap between natural and formal languages. Compared to state-of-the-art methods, Seed-Prover 1.5 achieves superior performance with a smaller compute budget. It solves \textbf{88\% of PutnamBench} (undergraduate-level), \textbf{80\% of Fate-H} (graduate-level), and \textbf{33\% of Fate-X} (PhD-level) problems. Notably, using our system, we solved \textbf{11 out of 12 problems} from Putnam 2025 within 9 hours. Our findings suggest that scaling learning from experience, driven by high-quality formal feedback, holds immense potential for the future of formal mathematical reasoning.
Geometric Prior-Guided Federated Prompt Calibration
Dec 08, 2025Federated Prompt Learning (FPL) offers a parameter-efficient solution for collaboratively training large models, but its performance is severely hindered by data heterogeneity, which causes locally trained prompts to become biased. Existing methods, focusing on aggregation or regularization, fail to address this root cause of local training bias. To this end, we propose Geometry-Guided Text Prompt Calibration (GGTPC), a novel framework that directly corrects this bias by providing clients with a global geometric prior. This prior, representing the shape of the global data distribution derived from the covariance matrix, is reconstructed on the server in a privacy-preserving manner. Clients then use a novel Geometry-Prior Calibration Layer (GPCL) to align their local feature distributions with this global prior during training. Extensive experiments show GGTPC's effectiveness. On the label-skewed CIFAR-100 dataset ($β$=0.1), it outperforms the state-of-the-art by 2.15\%. Under extreme skew ($β$=0.01), it improves upon the baseline by 9.17\%. Furthermore, as a plug-and-play module on the domain-skewed Office-Home dataset, it boosts FedAvg's performance by 4.60\%. These results demonstrate that GGTPC effectively mitigates data heterogeneity by correcting the fundamental local training bias, serving as a versatile module to enhance various FL algorithms.
EVA-Net: Interpretable Brain Age Prediction via Continuous Aging Prototypes from EEG
Nov 19, 2025The brain age is a key indicator of brain health. While electroencephalography (EEG) is a practical tool for this task, existing models struggle with the common challenge of imperfect medical data, such as learning a ``normal'' baseline from weakly supervised, healthy-only cohorts. This is a critical anomaly detection task for identifying disease, but standard models are often black boxes lacking an interpretable structure. We propose EVA-Net, a novel framework that recasts brain age as an interpretable anomaly detection problem. EVA-Net uses an efficient, sparsified-attention Transformer to model long EEG sequences. To handle noise and variability in imperfect data, it employs a Variational Information Bottleneck to learn a robust, compressed representation. For interpretability, this representation is aligned to a continuous prototype network that explicitly learns the normative healthy aging manifold. Trained on 1297 healthy subjects, EVA-Net achieves state-of-the-art accuracy. We validated its anomaly detection capabilities on an unseen cohort of 27 MCI and AD patients. This pathological group showed significantly higher brain-age gaps and a novel Prototype Alignment Error, confirming their deviation from the healthy manifold. EVA-Net provides an interpretable framework for healthcare intelligence using imperfect medical data.
FLEX: Continuous Agent Evolution via Forward Learning from Experience
Nov 09, 2025Autonomous agents driven by Large Language Models (LLMs) have revolutionized reasoning and problem-solving but remain static after training, unable to grow with experience as intelligent beings do during deployment. We introduce Forward Learning with EXperience (FLEX), a gradient-free learning paradigm that enables LLM agents to continuously evolve through accumulated experience. Specifically, FLEX cultivates scalable and inheritable evolution by constructing a structured experience library through continual reflection on successes and failures during interaction with the environment. FLEX delivers substantial improvements on mathematical reasoning, chemical retrosynthesis, and protein fitness prediction (up to 23% on AIME25, 10% on USPTO50k, and 14% on ProteinGym). We further identify a clear scaling law of experiential growth and the phenomenon of experience inheritance across agents, marking a step toward scalable and inheritable continuous agent evolution. Project Page: https://flex-gensi-thuair.github.io.
ThinkDial: An Open Recipe for Controlling Reasoning Effort in Large Language Models
Aug 26, 2025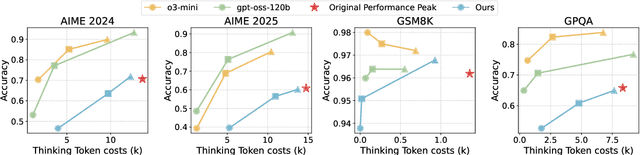
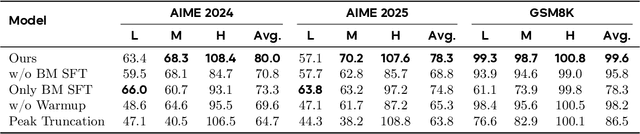
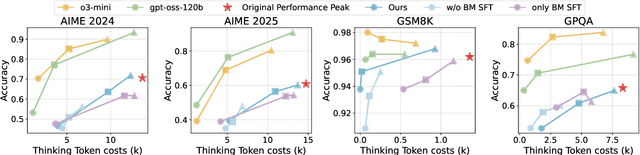

Large language models (LLMs) with chain-of-thought reasoning have demonstrated remarkable problem-solving capabilities, but controlling their computational effort remains a significant challenge for practical deployment. Recent proprietary systems like OpenAI's gpt-oss series have introduced discrete operational modes for intuitive reasoning control, but the open-source community has largely failed to achieve such capabilities. In this paper, we introduce ThinkDial, the first open-recipe end-to-end framework that successfully implements gpt-oss-style controllable reasoning through discrete operational modes. Our system enables seamless switching between three distinct reasoning regimes: High mode (full reasoning capability), Medium mode (50 percent token reduction with <10 percent performance degradation), and Low mode (75 percent token reduction with <15 percent performance degradation). We achieve this through an end-to-end training paradigm that integrates budget-mode control throughout the entire pipeline: budget-mode supervised fine-tuning that embeds controllable reasoning capabilities directly into the learning process, and two-phase budget-aware reinforcement learning with adaptive reward shaping. Extensive experiments demonstrate that ThinkDial achieves target compression-performance trade-offs with clear response length reductions while maintaining performance thresholds. The framework also exhibits strong generalization capabilities on out-of-distribution tasks.