 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenAI o1 System Card
Dec 21, 2024



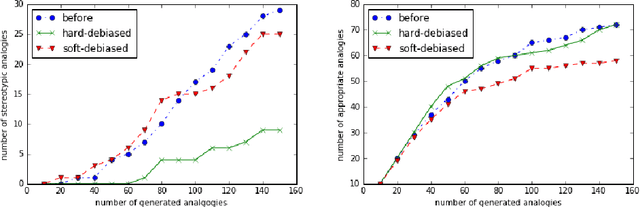
The o1 model series is trained with large-scale reinforcement learning to reason using chain of thought. These advanced reasoning capabilities provide new avenues for improving the safety and robustness of our models. In particular, our models can reason about our safety policies in context when responding to potentially unsafe prompts, through deliberative alignment. This leads to state-of-the-art performance on certain benchmarks for risks such as generating illicit advice, choosing stereotyped responses, and succumbing to known jailbreaks. Training models to incorporate a chain of thought before answering has the potential to unlock substantial benefits, while also increasing potential risks that stem from heightened intelligence. Our results underscore the need for building robust alignment methods, extensively stress-testing their efficacy, and maintaining meticulous risk management protocols. This report outlines the safety work carried out for the OpenAI o1 and OpenAI o1-mini models, including safety evaluations, external red teaming, and Preparedness Framework evaluations.
Efficient Learning with Arbitrary Covariate Shift
Feb 15, 2021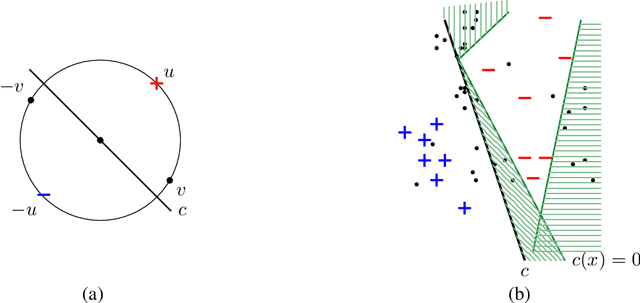
We give an efficient algorithm for learning a binary function in a given class C of bounded VC dimension, with training data distributed according to P and test data according to Q, where P and Q may be arbitrary distributions over X. This is the generic form of what is called covariate shift, which is impossible in general as arbitrary P and Q may not even overlap. However, recently guarantees were given in a model called PQ-learning (Goldwasser et al., 2020) where the learner has: (a) access to unlabeled test examples from Q (in addition to labeled samples from P, i.e., semi-supervised learning); and (b) the option to reject any example and abstain from classifying it (i.e., selective classification). The algorithm of Goldwasser et al. (2020) requires an (agnostic) noise tolerant learner for C. The present work gives a polynomial-time PQ-learning algorithm that uses an oracle to a "reliable" learner for C, where reliable learning (Kalai et al., 2012) is a model of learning with one-sided noise. Furthermore, our reduction is optimal in the sense that we show the equivalence of reliable and PQ learning.
Learn to Expect the Unexpected: Probably Approximately Correct Domain Generalization
Feb 13, 2020

Domain generalization is the problem of machine learning when the training data and the test data come from different data domains. We present a simple theoretical model of learning to generalize across domains in which there is a meta-distribution over data distributions, and those data distributions may even have different supports. In our model, the training data given to a learning algorithm consists of multiple datasets each from a single domain drawn in turn from the meta-distribution. We study this model in three different problem settings---a multi-domain Massart noise setting, a decision tree multi-dataset setting, and a feature selection setting, and find that computationally efficient, polynomial-sample domain generalization is possible in each. Experiments demonstrate that our feature selection algorithm indeed ignores spurious correlations and improves generalization.
Actively Avoiding Nonsense in Generative Models
Feb 20, 2018
A generative model may generate utter nonsense when it is fit to maximize the likelihood of observed data. This happens due to "model error," i.e., when the true data generating distribution does not fit within the class of generative models being learned. To address this, we propose a model of active distribution learning using a binary invalidity oracle that identifies some examples as clearly invalid, together with random positive examples sampled from the true distribution. The goal is to maximize the likelihood of the positive examples subject to the constraint of (almost) never generating examples labeled invalid by the oracle. Guarantees are agnostic compared to a class of probability distributions. We show that, while proper learning often requires exponentially many queries to the invalidity oracle, improper distribution learning can be done using polynomially many queries.
Supervising Unsupervised Learning
Feb 16, 2018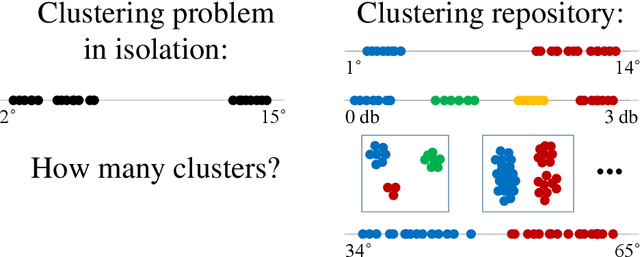
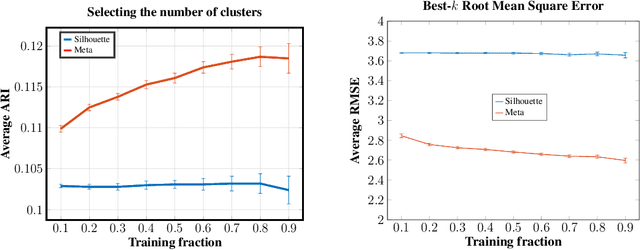
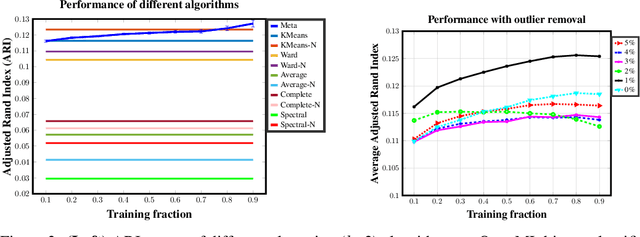
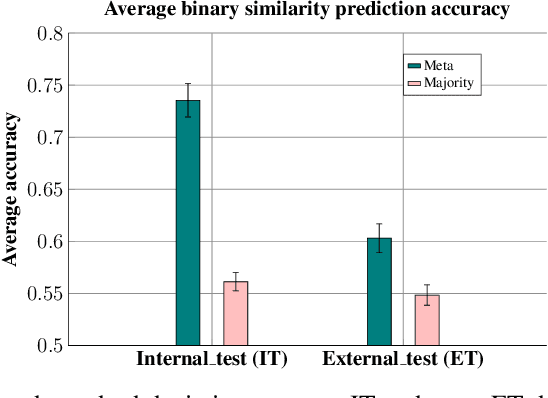
We introduce a framework to leverage knowledge acquired from a repository of (heterogeneous) supervised datasets to new unsupervised datasets. Our perspective avoids the subjectivity inherent in unsupervised learning by reducing it to supervised learning, and provides a principled way to evaluate unsupervised algorithms. We demonstrate the versatility of our framework via simple agnostic bounds on unsupervised problems. In the context of clustering, our approach helps choose the number of clusters and the clustering algorithm, remove the outliers, and provably circumvent the Kleinberg's impossibility result. Experimental results across hundreds of problems demonstrate improved performance on unsupervised data with simple algorithms, despite the fact that our problems come from heterogeneous domains. Additionally, our framework lets us leverage deep networks to learn common features from many such small datasets, and perform zero shot learning.
Beyond Bilingual: Multi-sense Word Embeddings using Multilingual Context
Jun 25, 2017
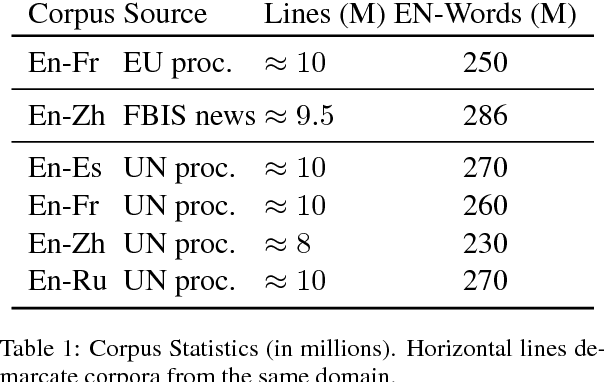
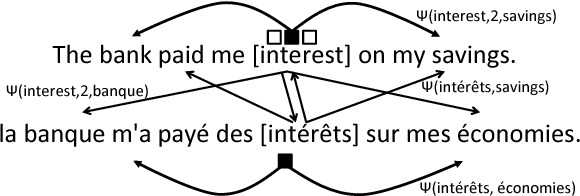
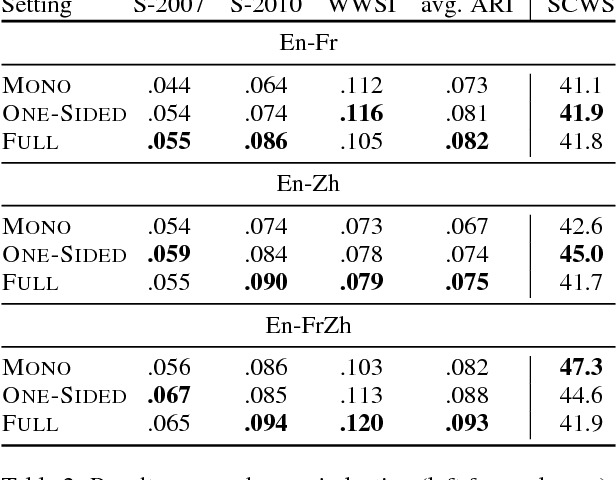
Word embeddings, which represent a word as a point in a vector space, have become ubiquitous to several NLP tasks. A recent line of work uses bilingual (two languages) corpora to learn a different vector for each sense of a word, by exploiting crosslingual signals to aid sense identification. We present a multi-view Bayesian non-parametric algorithm which improves multi-sense word embeddings by (a) using multilingual (i.e., more than two languages) corpora to significantly improve sense embeddings beyond what one achieves with bilingual information, and (b) uses a principled approach to learn a variable number of senses per word, in a data-driven manner. Ours is the first approach with the ability to leverage multilingual corpora efficiently for multi-sense representation learning. Experiments show that multilingual training significantly improves performance over monolingual and bilingual training, by allowing us to combine different parallel corpora to leverage multilingual context. Multilingual training yields comparable performance to a state of the art mono-lingual model trained on five times more training data.
Man is to Computer Programmer as Woman is to Homemaker? Debiasing Word Embeddings
Jul 21, 2016
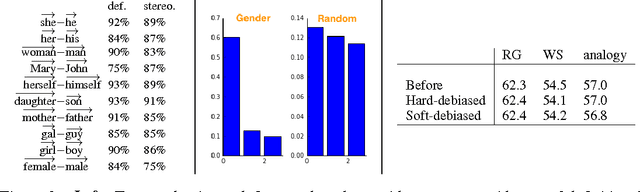
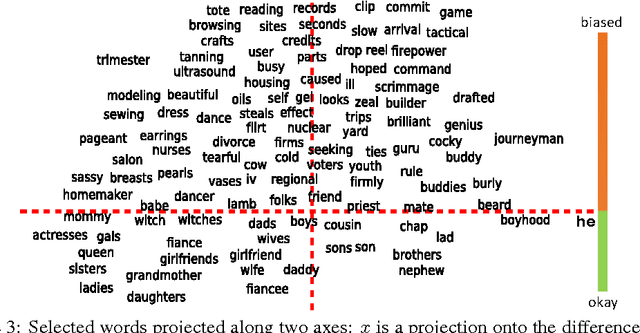
The blind application of machine learning runs the risk of amplifying biases present in data. Such a danger is facing us with word embedding, a popular framework to represent text data as vectors which has been used in many machine learning and natural language processing tasks. We show that even word embeddings trained on Google News articles exhibit female/male gender stereotypes to a disturbing extent. This raises concerns because their widespread use, as we describe, often tends to amplify these biases. Geometrically, gender bias is first shown to be captured by a direction in the word embedding. Second, gender neutral words are shown to be linearly separable from gender definition words in the word embedding. Using these properties, we provide a methodology for modifying an embedding to remove gender stereotypes, such as the association between between the words receptionist and female, while maintaining desired associations such as between the words queen and female. We define metrics to quantify both direct and indirect gender biases in embeddings, and develop algorithms to "debias" the embedding. Using crowd-worker evaluation as well as standard benchmarks, we empirically demonstrate that our algorithms significantly reduce gender bias in embeddings while preserving the its useful properties such as the ability to cluster related concepts and to solve analogy tasks. The resulting embeddings can be used in applications without amplifying gender bias.
Quantifying and Reducing Stereotypes in Word Embeddings
Jun 20, 2016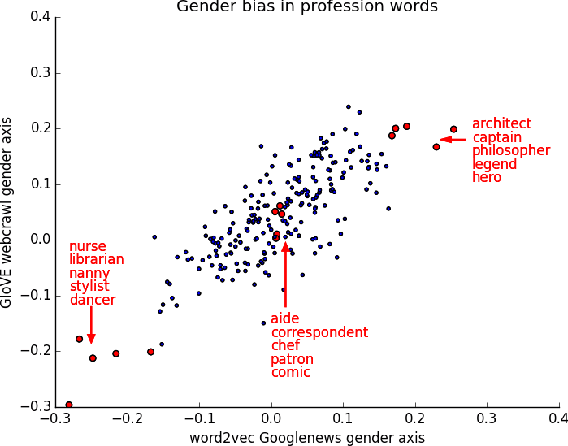

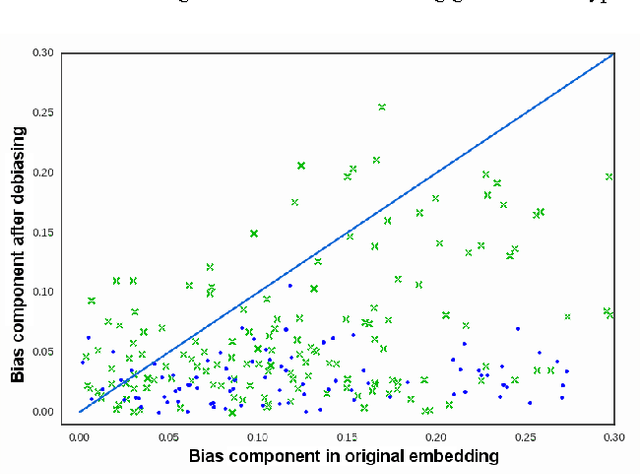
Machine learning algorithms are optimized to model statistical properties of the training data. If the input data reflects stereotypes and biases of the broader society, then the output of the learning algorithm also captures these stereotypes. In this paper, we initiate the study of gender stereotypes in {\em word embedding}, a popular framework to represent text data. As their use becomes increasingly common, applications can inadvertently amplify unwanted stereotypes. We show across multiple datasets that the embeddings contain significant gender stereotypes, especially with regard to professions. We created a novel gender analogy task and combined it with crowdsourcing to systematically quantify the gender bias in a given embedding. We developed an efficient algorithm that reduces gender stereotype using just a handful of training examples while preserving the useful geometric properties of the embedding. We evaluated our algorithm on several metrics. While we focus on male/female stereotypes, our framework may be applicable to other types of embedding biases.
Feature Multi-Selection among Subjective Features
May 14, 2013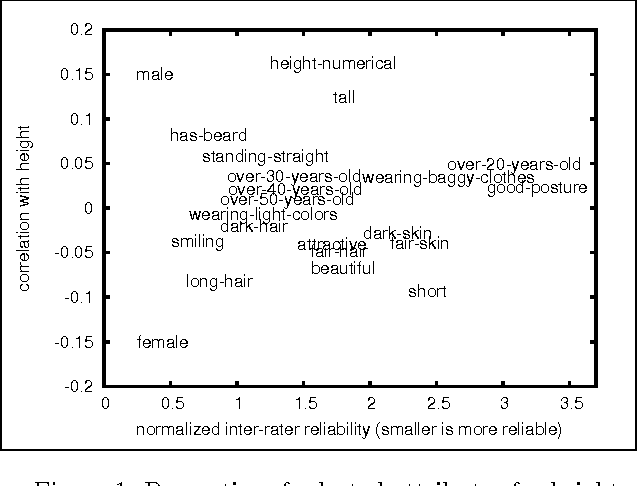
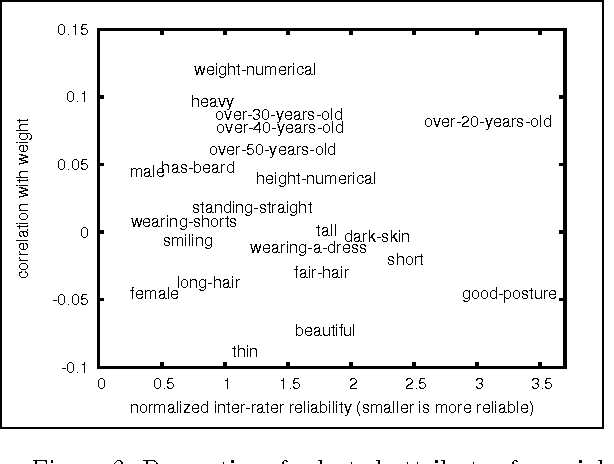
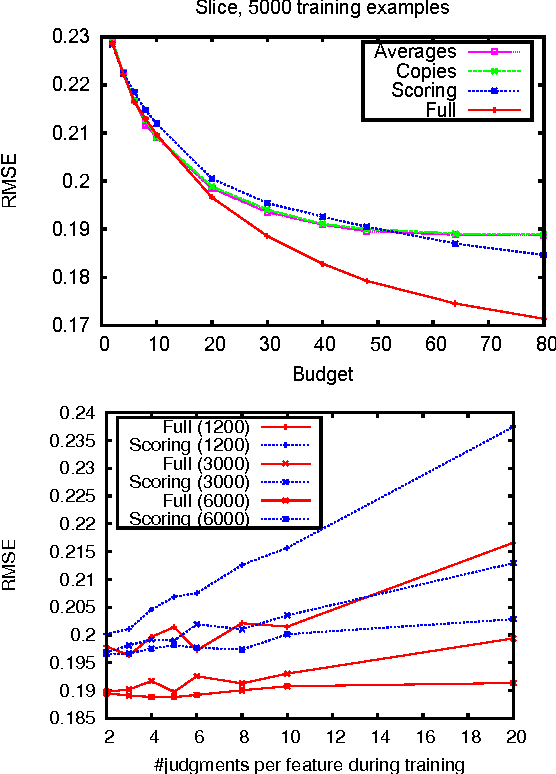
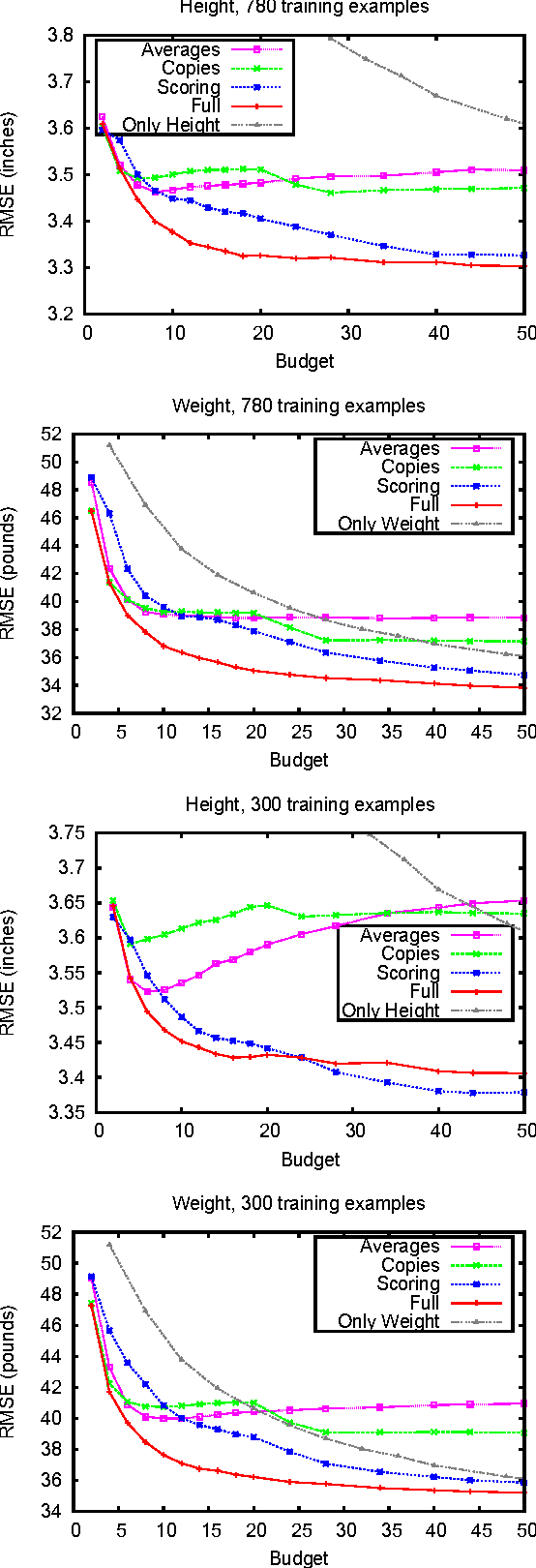
When dealing with subjective, noisy, or otherwise nebulous features, the "wisdom of crowds" suggests that one may benefit from multiple judgments of the same feature on the same object. We give theoretically-motivated `feature multi-selection' algorithms that choose, among a large set of candidate features, not only which features to judge but how many times to judge each one. We demonstrate the effectiveness of this approach for linear regression on a crowdsourced learning task of predicting people's height and weight from photos, using features such as 'gender' and 'estimated weight' as well as culturally fraught ones such as 'attractive'.
Noise-Tolerant Learning, the Parity Problem, and the Statistical Query Model
Oct 15, 2000We describe a slightly sub-exponential time algorithm for learning parity functions in the presence of random classification noise. This results in a polynomial-time algorithm for the case of parity functions that depend on only the first O(log n log log n) bits of input. This is the first known instance of an efficient noise-tolerant algorithm for a concept class that is provably not learnable in the Statistical Query model of Kearns. Thus, we demonstrate that the set of problems learnable in the statistical query model is a strict subset of those problems learnable in the presence of noise in the PAC model. In coding-theory terms, what we give is a poly(n)-time algorithm for decoding linear k by n codes in the presence of random noise for the case of k = c log n loglog n for some c > 0. (The case of k = O(log n) is trivial since one can just individually check each of the 2^k possible messages and choose the one that yields the closest codeword.) A natural extension of the statistical query model is to allow queries about statistical properties that involve t-tuples of examples (as opposed to single examples). The second result of this paper is to show that any class of functions learnable (strongly or weakly) with t-wise queries for t = O(log n) is also weakly learnable with standard unary queries. Hence this natural extension to the statistical query model does not increase the set of weakly learnable functions.