 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearn to Expect the Unexpected: Probably Approximately Correct Domain Generalization
Paper and Code
Feb 13, 2020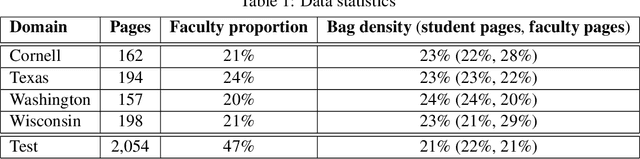
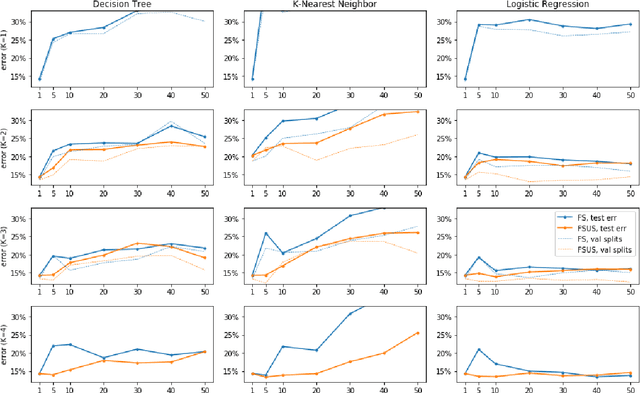

Domain generalization is the problem of machine learning when the training data and the test data come from different data domains. We present a simple theoretical model of learning to generalize across domains in which there is a meta-distribution over data distributions, and those data distributions may even have different supports. In our model, the training data given to a learning algorithm consists of multiple datasets each from a single domain drawn in turn from the meta-distribution. We study this model in three different problem settings---a multi-domain Massart noise setting, a decision tree multi-dataset setting, and a feature selection setting, and find that computationally efficient, polynomial-sample domain generalization is possible in each. Experiments demonstrate that our feature selection algorithm indeed ignores spurious correlations and improves generalization.