 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralization and Representational Limits of Graph Neural Networks
Feb 14, 2020
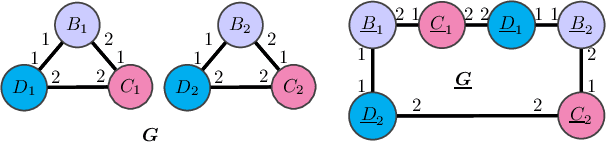


We address two fundamental questions about graph neural networks (GNNs). First, we prove that several important graph properties cannot be computed by GNNs that rely entirely on local information. Such GNNs include the standard message passing models, and more powerful spatial variants that exploit local graph structure (e.g., via relative orientation of messages, or local port ordering) to distinguish neighbors of each node. Our treatment includes a novel graph-theoretic formalism. Second, we provide the first data dependent generalization bounds for message passing GNNs. This analysis explicitly accounts for the local permutation invariance of GNNs. Our bounds are much tighter than existing VC-dimension based guarantees for GNNs, and are comparable to Rademacher bounds for recurrent neural networks.
Learn to Expect the Unexpected: Probably Approximately Correct Domain Generalization
Feb 13, 2020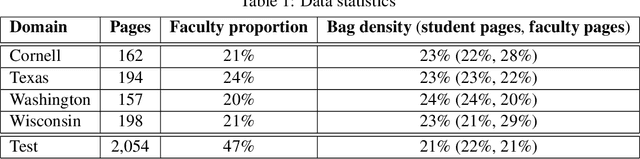

Domain generalization is the problem of machine learning when the training data and the test data come from different data domains. We present a simple theoretical model of learning to generalize across domains in which there is a meta-distribution over data distributions, and those data distributions may even have different supports. In our model, the training data given to a learning algorithm consists of multiple datasets each from a single domain drawn in turn from the meta-distribution. We study this model in three different problem settings---a multi-domain Massart noise setting, a decision tree multi-dataset setting, and a feature selection setting, and find that computationally efficient, polynomial-sample domain generalization is possible in each. Experiments demonstrate that our feature selection algorithm indeed ignores spurious correlations and improves generalization.
Multiresolution Transformer Networks: Recurrence is Not Essential for Modeling Hierarchical Structure
Aug 27, 2019


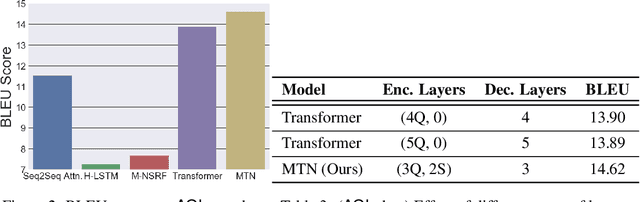
The architecture of Transformer is based entirely on self-attention, and has been shown to outperform models that employ recurrence on sequence transduction tasks such as machine translation. The superior performance of Transformer has been attributed to propagating signals over shorter distances, between positions in the input and the output, compared to the recurrent architectures. We establish connections between the dynamics in Transformer and recurrent networks to argue that several factors including gradient flow along an ensemble of multiple weakly dependent paths play a paramount role in the success of Transformer. We then leverage the dynamics to introduce {\em Multiresolution Transformer Networks} as the first architecture that exploits hierarchical structure in data via self-attention. Our models significantly outperform state-of-the-art recurrent and hierarchical recurrent models on two real-world datasets for query suggestion, namely, \aol and \amazon. In particular, on AOL data, our model registers at least 20\% improvement on each precision score, and over 25\% improvement on the BLEU score with respect to the best performing recurrent model. We thus provide strong evidence that recurrence is not essential for modeling hierarchical structure.
Strategic Prediction with Latent Aggregative Games
May 29, 2019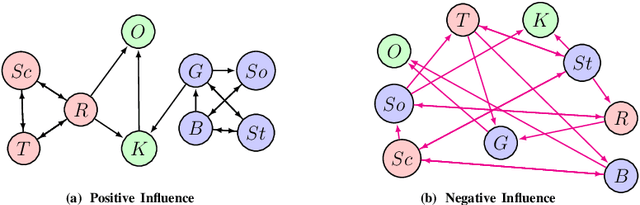
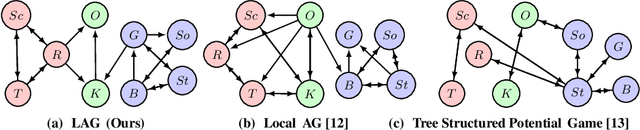
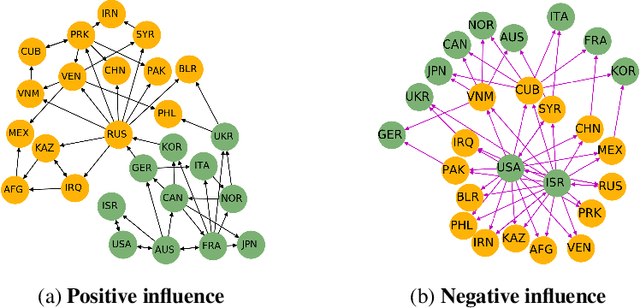

We introduce a new class of context dependent, incomplete information games to serve as structured prediction models for settings with significant strategic interactions. Our games map the input context to outcomes by first condensing the input into private player types that specify the utilities, weighted interactions, as well as the initial strategies for the players. The game is played over multiple rounds where players respond to weighted aggregates of their neighbors' strategies. The predicted output from the model is a mixed strategy profile (a near-Nash equilibrium) and each observation is thought of as a sample from this strategy profile. We introduce two new aggregator paradigms with provably convergent game dynamics, and characterize the conditions under which our games are identifiable from data. Our games can be parameterized in a transferable manner so that the sets of players can change from one game to another. We demonstrate empirically that our games as models can recover meaningful strategic interactions from real voting data.
Solving graph compression via optimal transport
May 29, 2019


We propose a new approach to graph compression by appeal to optimal transport. The transport problem is seeded with prior information about node importance, attributes, and edges in the graph. The transport formulation can be setup for either directed or undirected graphs, and its dual characterization is cast in terms of distributions over the nodes. The compression pertains to the support of node distributions and makes the problem challenging to solve directly. To this end, we introduce Boolean relaxations and specify conditions under which these relaxations are exact. The relaxations admit algorithms with provably fast convergence. Moreover, we provide an exact $O(d \log d)$ algorithm for the subproblem of projecting a $d$-dimensional vector to transformed simplex constraints. Our method outperforms state-of-the-art compression methods on graph classification.
Peek Search: Near-Optimal Online Markov Decoding
Oct 16, 2018
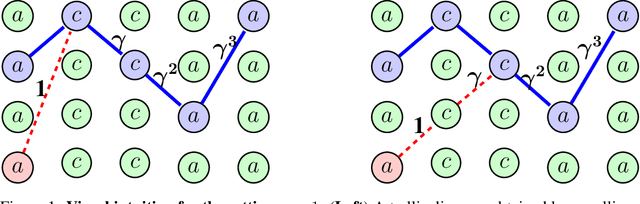

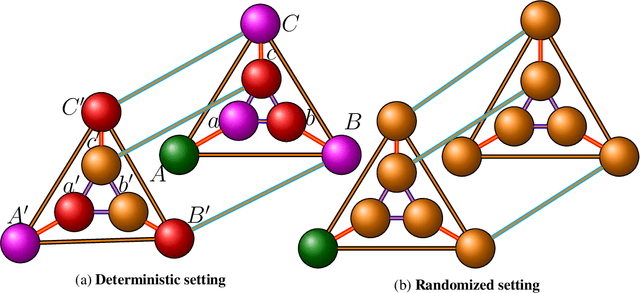
We resolve the fundamental problem of online decoding with ergodic Markov models. Specifically, we provide deterministic and randomized algorithms that are provably near-optimal under latency constraints with respect to the unconstrained offline optimal algorithm. Our algorithms admit efficient implementation via dynamic programs, and extend to (possibly adversarial) non-stationary or time-varying Markov settings as well. Moreover, we establish lower bounds in both deterministic and randomized settings subject to latency requirements, and prove that no online algorithm can perform significantly better than our algorithms.
Learning SMaLL Predictors
Mar 06, 2018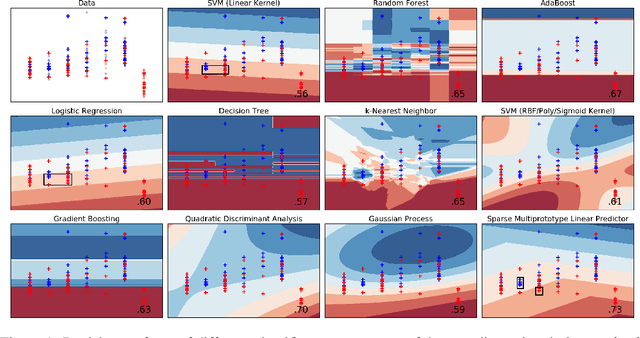
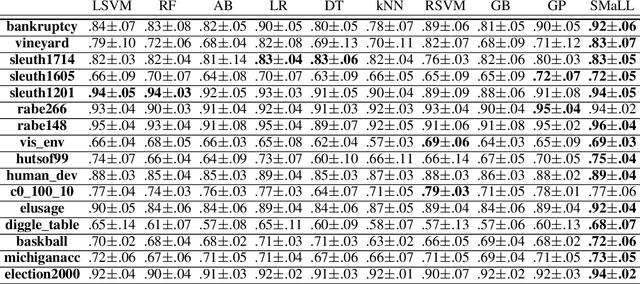
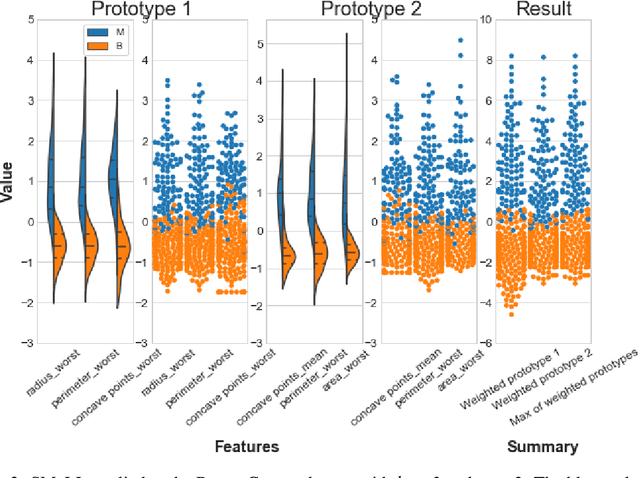

We present a new machine learning technique for training small resource-constrained predictors. Our algorithm, the Sparse Multiprototype Linear Learner (SMaLL), is inspired by the classic machine learning problem of learning $k$-DNF Boolean formulae. We present a formal derivation of our algorithm and demonstrate the benefits of our approach with a detailed empirical study.
Supervising Unsupervised Learning
Feb 16, 2018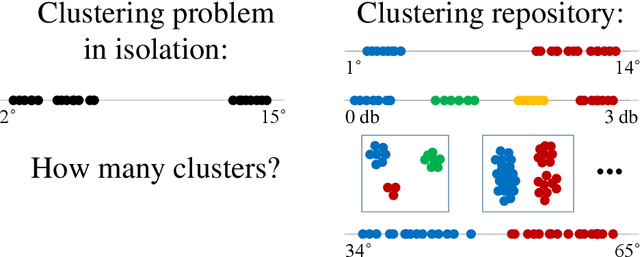
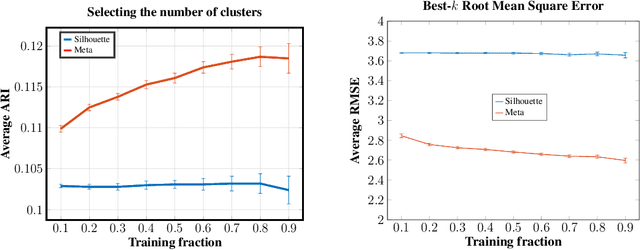
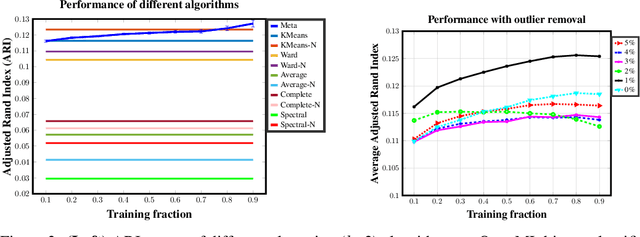
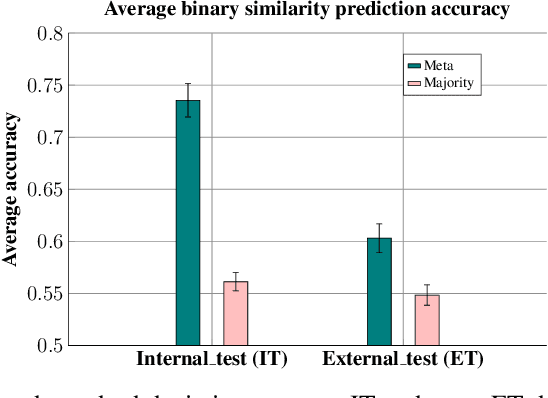
We introduce a framework to leverage knowledge acquired from a repository of (heterogeneous) supervised datasets to new unsupervised datasets. Our perspective avoids the subjectivity inherent in unsupervised learning by reducing it to supervised learning, and provides a principled way to evaluate unsupervised algorithms. We demonstrate the versatility of our framework via simple agnostic bounds on unsupervised problems. In the context of clustering, our approach helps choose the number of clusters and the clustering algorithm, remove the outliers, and provably circumvent the Kleinberg's impossibility result. Experimental results across hundreds of problems demonstrate improved performance on unsupervised data with simple algorithms, despite the fact that our problems come from heterogeneous domains. Additionally, our framework lets us leverage deep networks to learn common features from many such small datasets, and perform zero shot learning.
Meta-Unsupervised-Learning: A supervised approach to unsupervised learning
Jan 03, 2017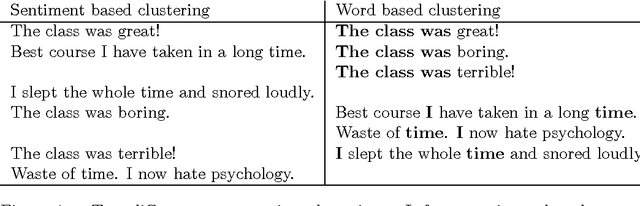
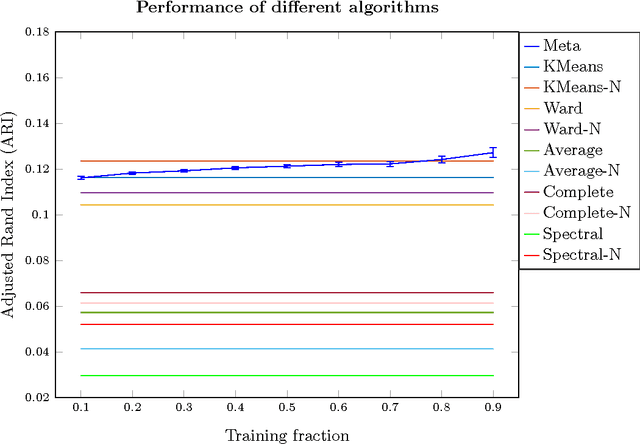
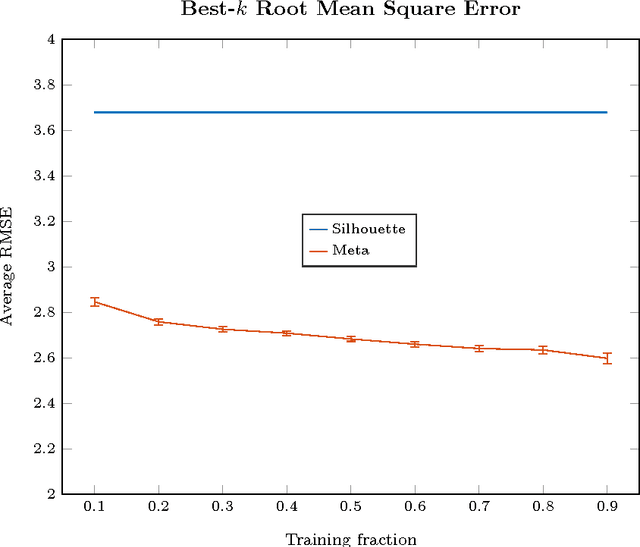
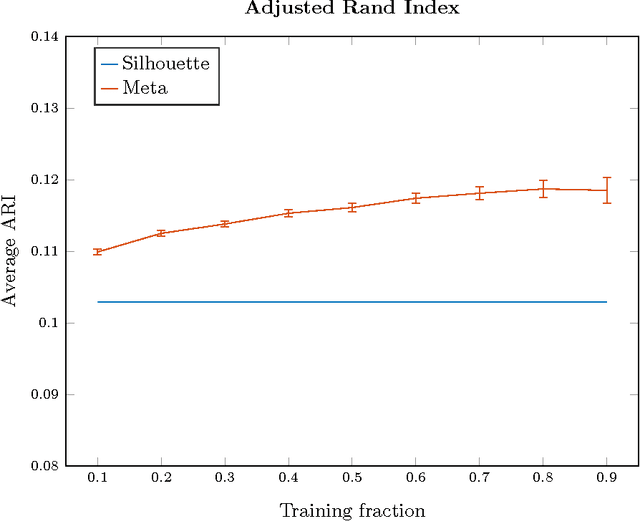
We introduce a new paradigm to investigate unsupervised learning, reducing unsupervised learning to supervised learning. Specifically, we mitigate the subjectivity in unsupervised decision-making by leveraging knowledge acquired from prior, possibly heterogeneous, supervised learning tasks. We demonstrate the versatility of our framework via comprehensive expositions and detailed experiments on several unsupervised problems such as (a) clustering, (b) outlier detection, and (c) similarity prediction under a common umbrella of meta-unsupervised-learning. We also provide rigorous PAC-agnostic bounds to establish the theoretical foundations of our framework, and show that our framing of meta-clustering circumvents Kleinberg's impossibility theorem for clustering.
CRAFT: ClusteR-specific Assorted Feature selecTion
Jun 25, 2015



We present a framework for clustering with cluster-specific feature selection. The framework, CRAFT, is derived from asymptotic log posterior formulations of nonparametric MAP-based clustering models. CRAFT handles assorted data, i.e., both numeric and categorical data, and the underlying objective functions are intuitively appealing. The resulting algorithm is simple to implement and scales nicely, requires minimal parameter tuning, obviates the need to specify the number of clusters a priori, and compares favorably with other methods on real datasets.