 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsensus Sampling for Safer Generative AI
Nov 12, 2025Many approaches to AI safety rely on inspecting model outputs or activations, yet certain risks are inherently undetectable by inspection alone. We propose a complementary, architecture-agnostic approach that enhances safety through the aggregation of multiple generative models, with the aggregated model inheriting its safety from the safest subset of a given size among them. Specifically, we present a consensus sampling algorithm that, given $k$ models and a prompt, achieves risk competitive with the average risk of the safest $s$ of the $k$ models, where $s$ is a chosen parameter, while abstaining when there is insufficient agreement between them. The approach leverages the models' ability to compute output probabilities, and we bound the probability of abstention when sufficiently many models are safe and exhibit adequate agreement. The algorithm is inspired by the provable copyright protection algorithm of Vyas et al. (2023). It requires some overlap among safe models, offers no protection when all models are unsafe, and may accumulate risk over repeated use. Nonetheless, our results provide a new, model-agnostic approach for AI safety by amplifying safety guarantees from an unknown subset of models within a collection to that of a single reliable model.
Why Language Models Hallucinate
Sep 04, 2025Like students facing hard exam questions, large language models sometimes guess when uncertain, producing plausible yet incorrect statements instead of admitting uncertainty. Such "hallucinations" persist even in state-of-the-art systems and undermine trust. We argue that language models hallucinate because the training and evaluation procedures reward guessing over acknowledging uncertainty, and we analyze the statistical causes of hallucinations in the modern training pipeline. Hallucinations need not be mysterious -- they originate simply as errors in binary classification. If incorrect statements cannot be distinguished from facts, then hallucinations in pretrained language models will arise through natural statistical pressures. We then argue that hallucinations persist due to the way most evaluations are graded -- language models are optimized to be good test-takers, and guessing when uncertain improves test performance. This "epidemic" of penalizing uncertain responses can only be addressed through a socio-technical mitigation: modifying the scoring of existing benchmarks that are misaligned but dominate leaderboards, rather than introducing additional hallucination evaluations. This change may steer the field toward more trustworthy AI systems.
The Singapore Consensus on Global AI Safety Research Priorities
Jun 25, 2025


Rapidly improving AI capabilities and autonomy hold significant promise of transformation, but are also driving vigorous debate on how to ensure that AI is safe, i.e., trustworthy, reliable, and secure. Building a trusted ecosystem is therefore essential -- it helps people embrace AI with confidence and gives maximal space for innovation while avoiding backlash. The "2025 Singapore Conference on AI (SCAI): International Scientific Exchange on AI Safety" aimed to support research in this space by bringing together AI scientists across geographies to identify and synthesise research priorities in AI safety. This resulting report builds on the International AI Safety Report chaired by Yoshua Bengio and backed by 33 governments. By adopting a defence-in-depth model, this report organises AI safety research domains into three types: challenges with creating trustworthy AI systems (Development), challenges with evaluating their risks (Assessment), and challenges with monitoring and intervening after deployment (Control).
Meta-Prompting: Enhancing Language Models with Task-Agnostic Scaffolding
Jan 23, 2024We introduce meta-prompting, an effective scaffolding technique designed to enhance the functionality of language models (LMs). This approach transforms a single LM into a multi-faceted conductor, adept at managing and integrating multiple independent LM queries. By employing high-level instructions, meta-prompting guides the LM to break down complex tasks into smaller, more manageable subtasks. These subtasks are then handled by distinct "expert" instances of the same LM, each operating under specific, tailored instructions. Central to this process is the LM itself, in its role as the conductor, which ensures seamless communication and effective integration of the outputs from these expert models. It additionally employs its inherent critical thinking and robust verification processes to refine and authenticate the end result. This collaborative prompting approach empowers a single LM to simultaneously act as a comprehensive orchestrator and a panel of diverse experts, significantly enhancing its performance across a wide array of tasks. The zero-shot, task-agnostic nature of meta-prompting greatly simplifies user interaction by obviating the need for detailed, task-specific instructions. Furthermore, our research demonstrates the seamless integration of external tools, such as a Python interpreter, into the meta-prompting framework, thereby broadening its applicability and utility. Through rigorous experimentation with GPT-4, we establish the superiority of meta-prompting over conventional scaffolding methods: When averaged across all tasks, including the Game of 24, Checkmate-in-One, and Python Programming Puzzles, meta-prompting, augmented with a Python interpreter functionality, surpasses standard prompting by 17.1%, expert (dynamic) prompting by 17.3%, and multipersona prompting by 15.2%.
Testing Language Model Agents Safely in the Wild
Dec 03, 2023A prerequisite for safe autonomy-in-the-wild is safe testing-in-the-wild. Yet real-world autonomous tests face several unique safety challenges, both due to the possibility of causing harm during a test, as well as the risk of encountering new unsafe agent behavior through interactions with real-world and potentially malicious actors. We propose a framework for conducting safe autonomous agent tests on the open internet: agent actions are audited by a context-sensitive monitor that enforces a stringent safety boundary to stop an unsafe test, with suspect behavior ranked and logged to be examined by humans. We design a basic safety monitor (AgentMonitor) that is flexible enough to monitor existing LLM agents, and, using an adversarial simulated agent, we measure its ability to identify and stop unsafe situations. Then we apply the AgentMonitor on a battery of real-world tests of AutoGPT, and we identify several limitations and challenges that will face the creation of safe in-the-wild tests as autonomous agents grow more capable.
Calibrated Language Models Must Hallucinate
Dec 03, 2023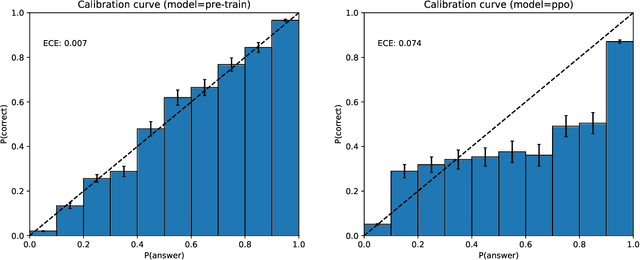

Recent language models generate false but plausible-sounding text with surprising frequency. Such "hallucinations" are an obstacle to the usability of language-based AI systems and can harm people who rely upon their outputs. This work shows shows that there is an inherent statistical lower-bound on the rate that pretrained language models hallucinate certain types of facts, having nothing to do with the transformer LM architecture or data quality. For "arbitrary" facts whose veracity cannot be determined from the training data, we show that hallucinations must occur at a certain rate for language models that satisfy a statistical calibration condition appropriate for generative language models. Specifically, if the maximum probability of any fact is bounded, we show that the probability of generating a hallucination is close to the fraction of facts that occur exactly once in the training data (a "Good-Turing" estimate), even assuming ideal training data without errors. One conclusion is that models pretrained to be sufficiently good predictors (i.e., calibrated) may require post-training to mitigate hallucinations on the type of arbitrary facts that tend to appear once in the training set. However, our analysis also suggests that there is no statistical reason that pretraining will lead to hallucination on facts that tend to appear more than once in the training data (like references to publications such as articles and books, whose hallucinations have been particularly notable and problematic) or on systematic facts (like arithmetic calculations). Therefore, different architectures and learning algorithms may mitigate these latter types of hallucinations.
Self-Taught Optimizer (STOP): Recursively Self-Improving Code Generation
Oct 03, 2023Several recent advances in AI systems (e.g., Tree-of-Thoughts and Program-Aided Language Models) solve problems by providing a "scaffolding" program that structures multiple calls to language models to generate better outputs. A scaffolding program is written in a programming language such as Python. In this work, we use a language-model-infused scaffolding program to improve itself. We start with a seed "improver" that improves an input program according to a given utility function by querying a language model several times and returning the best solution. We then run this seed improver to improve itself. Across a small set of downstream tasks, the resulting improved improver generates programs with significantly better performance than its seed improver. Afterward, we analyze the variety of self-improvement strategies proposed by the language model, including beam search, genetic algorithms, and simulated annealing. Since the language models themselves are not altered, this is not full recursive self-improvement. Nonetheless, it demonstrates that a modern language model, GPT-4 in our proof-of-concept experiments, is capable of writing code that can call itself to improve itself. We critically consider concerns around the development of self-improving technologies and evaluate the frequency with which the generated code bypasses a sandbox.
Textbooks Are All You Need
Jun 20, 2023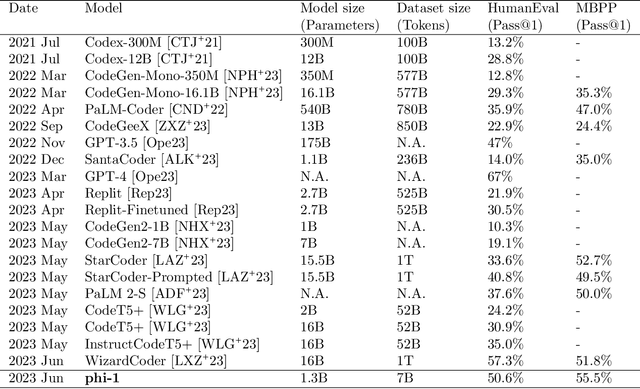
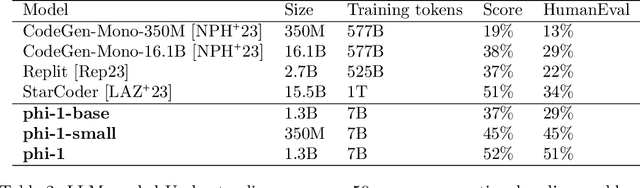
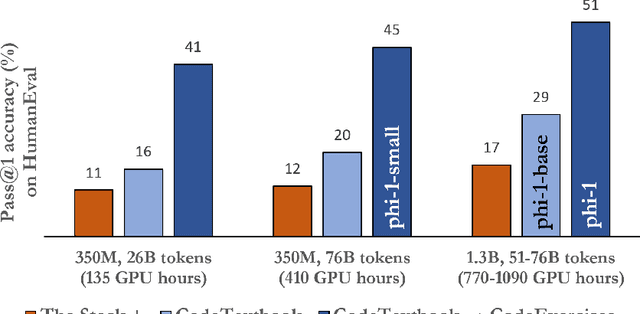
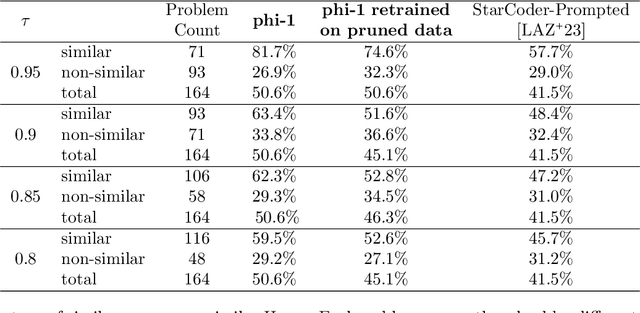
We introduce phi-1, a new large language model for code, with significantly smaller size than competing models: phi-1 is a Transformer-based model with 1.3B parameters, trained for 4 days on 8 A100s, using a selection of ``textbook quality" data from the web (6B tokens) and synthetically generated textbooks and exercises with GPT-3.5 (1B tokens). Despite this small scale, phi-1 attains pass@1 accuracy 50.6% on HumanEval and 55.5% on MBPP. It also displays surprising emergent properties compared to phi-1-base, our model before our finetuning stage on a dataset of coding exercises, and phi-1-small, a smaller model with 350M parameters trained with the same pipeline as phi-1 that still achieves 45% on HumanEval.
Do Language Models Know When They're Hallucinating References?
May 29, 2023



Current state-of-the-art language models (LMs) are notorious for generating text with "hallucinations," a primary example being book and paper references that lack any solid basis in their training data. However, we find that many of these fabrications can be identified using the same LM, using only black-box queries without consulting any external resources. Consistency checks done with direct queries about whether the generated reference title is real (inspired by Kadavath et al. 2022, Lin et al. 2022, Manakul et al. 2023) are compared to consistency checks with indirect queries which ask for ancillary details such as the authors of the work. These consistency checks are found to be partially reliable indicators of whether or not the reference is a hallucination. In particular, we find that LMs in the GPT-series will hallucinate differing authors of hallucinated references when queried in independent sessions, while it will consistently identify authors of real references. This suggests that the hallucination may be more a result of generation techniques than the underlying representation.
Loss minimization yields multicalibration for large neural networks
Apr 19, 2023Multicalibration is a notion of fairness that aims to provide accurate predictions across a large set of groups. Multicalibration is known to be a different goal than loss minimization, even for simple predictors such as linear functions. In this note, we show that for (almost all) large neural network sizes, optimally minimizing squared error leads to multicalibration. Our results are about representational aspects of neural networks, and not about algorithmic or sample complexity considerations. Previous such results were known only for predictors that were nearly Bayes-optimal and were therefore representation independent. We emphasize that our results do not apply to specific algorithms for optimizing neural networks, such as SGD, and they should not be interpreted as "fairness comes for free from optimizing neural networks".