 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating the Development of Task-Oriented Communication in Vision-Language Models
Jan 28, 2026We investigate whether \emph{LLM-based agents} can develop task-oriented communication protocols that differ from standard natural language in collaborative reasoning tasks. Our focus is on two core properties such task-oriented protocols may exhibit: Efficiency -- conveying task-relevant information more concisely than natural language, and Covertness -- becoming difficult for external observers to interpret, raising concerns about transparency and control. To investigate these aspects, we use a referential-game framework in which vision-language model (VLM) agents communicate, providing a controlled, measurable setting for evaluating language variants. Experiments show that VLMs can develop effective, task-adapted communication patterns. At the same time, they can develop covert protocols that are difficult for humans and external agents to interpret. We also observe spontaneous coordination between similar models without explicitly shared protocols. These findings highlight both the potential and the risks of task-oriented communication, and position referential games as a valuable testbed for future work in this area.
Unsupervised Translation of Emergent Communication
Feb 11, 2025Emergent Communication (EC) provides a unique window into the language systems that emerge autonomously when agents are trained to jointly achieve shared goals. However, it is difficult to interpret EC and evaluate its relationship with natural languages (NL). This study employs unsupervised neural machine translation (UNMT) techniques to decipher ECs formed during referential games with varying task complexities, influenced by the semantic diversity of the environment. Our findings demonstrate UNMT's potential to translate EC, illustrating that task complexity characterized by semantic diversity enhances EC translatability, while higher task complexity with constrained semantic variability exhibits pragmatic EC, which, although challenging to interpret, remains suitable for translation. This research marks the first attempt, to our knowledge, to translate EC without the aid of parallel data.
Humanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.
Learning Randomized Reductions and Program Properties
Dec 24, 2024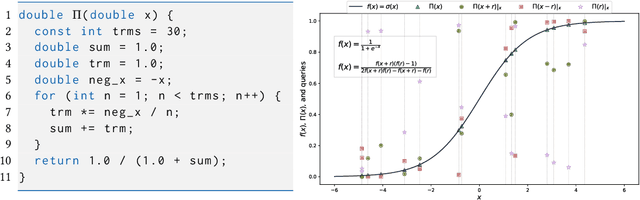
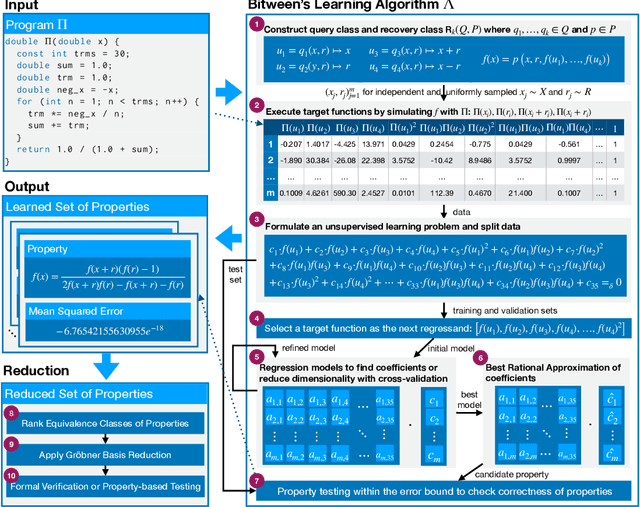
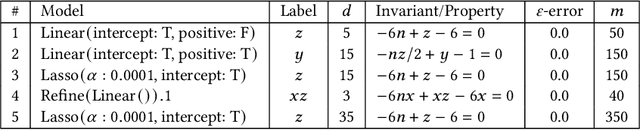

The correctness of computations remains a significant challenge in computer science, with traditional approaches relying on automated testing or formal verification. Self-testing/correcting programs introduce an alternative paradigm, allowing a program to verify and correct its own outputs via randomized reductions, a concept that previously required manual derivation. In this paper, we present Bitween, a method and tool for automated learning of randomized (self)-reductions and program properties in numerical programs. Bitween combines symbolic analysis and machine learning, with a surprising finding: polynomial-time linear regression, a basic optimization method, is not only sufficient but also highly effective for deriving complex randomized self-reductions and program invariants, often outperforming sophisticated mixed-integer linear programming solvers. We establish a theoretical framework for learning these reductions and introduce RSR-Bench, a benchmark suite for evaluating Bitween's capabilities on scientific and machine learning functions. Our empirical results show that Bitween surpasses state-of-the-art tools in scalability, stability, and sample efficiency when evaluated on nonlinear invariant benchmarks like NLA-DigBench. Bitween is open-source as a Python package and accessible via a web interface that supports C language programs.
Semantics and Spatiality of Emergent Communication
Nov 15, 2024



When artificial agents are jointly trained to perform collaborative tasks using a communication channel, they develop opaque goal-oriented communication protocols. Good task performance is often considered sufficient evidence that meaningful communication is taking place, but existing empirical results show that communication strategies induced by common objectives can be counterintuitive whilst solving the task nearly perfectly. In this work, we identify a goal-agnostic prerequisite to meaningful communication, which we term semantic consistency, based on the idea that messages should have similar meanings across instances. We provide a formal definition for this idea, and use it to compare the two most common objectives in the field of emergent communication: discrimination and reconstruction. We prove, under mild assumptions, that semantically inconsistent communication protocols can be optimal solutions to the discrimination task, but not to reconstruction. We further show that the reconstruction objective encourages a stricter property, spatial meaningfulness, which also accounts for the distance between messages. Experiments with emergent communication games validate our theoretical results. These findings demonstrate an inherent advantage of distance-based communication goals, and contextualize previous empirical discoveries.
Models That Prove Their Own Correctness
May 24, 2024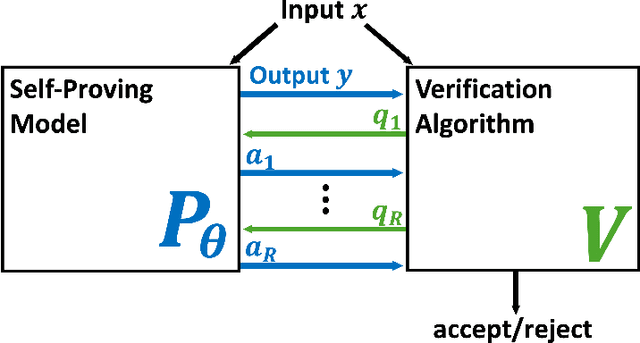
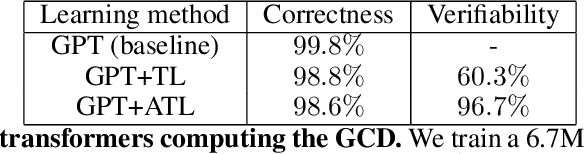
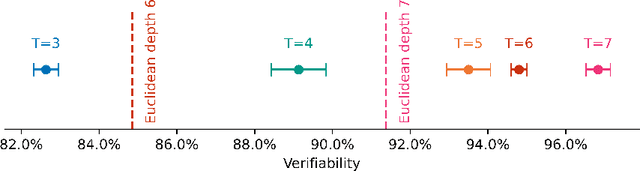

How can we trust the correctness of a learned model on a particular input of interest? Model accuracy is typically measured \emph{on average} over a distribution of inputs, giving no guarantee for any fixed input. This paper proposes a theoretically-founded solution to this problem: to train *Self-Proving models* that prove the correctness of their output to a verification algorithm $V$ via an Interactive Proof. Self-Proving models satisfy that, with high probability over a random input, the model generates a correct output \emph{and} successfully proves its correctness to $V\!$. The *soundness* property of $V$ guarantees that, for *every* input, no model can convince $V$ of the correctness of an incorrect output. Thus, a Self-Proving model proves correctness of most of its outputs, while *all* incorrect outputs (of any model) are detected by $V$. We devise a generic method for learning Self-Proving models, and we prove convergence bounds under certain assumptions. The theoretical framework and results are complemented by experiments on an arithmetic capability: computing the greatest common divisor (GCD) of two integers. Our learning method is used to train a Self-Proving transformer that computes the GCD *and* proves the correctness of its answer.
Pseudointelligence: A Unifying Framework for Language Model Evaluation
Oct 18, 2023With large language models surpassing human performance on an increasing number of benchmarks, we must take a principled approach for targeted evaluation of model capabilities. Inspired by pseudorandomness, we propose pseudointelligence, which captures the maxim that "(perceived) intelligence lies in the eye of the beholder". That is, that claims of intelligence are meaningful only when their evaluator is taken into account. Concretely, we propose a complexity-theoretic framework of model evaluation cast as a dynamic interaction between a model and a learned evaluator. We demonstrate that this framework can be used to reason about two case studies in language model evaluation, as well as analyze existing evaluation methods.
UniMASK: Unified Inference in Sequential Decision Problems
Nov 20, 2022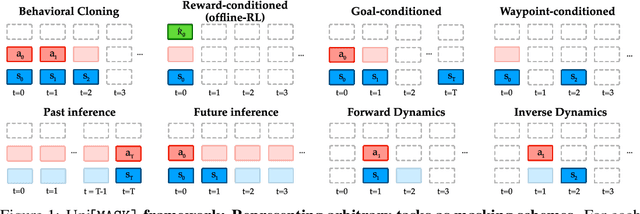
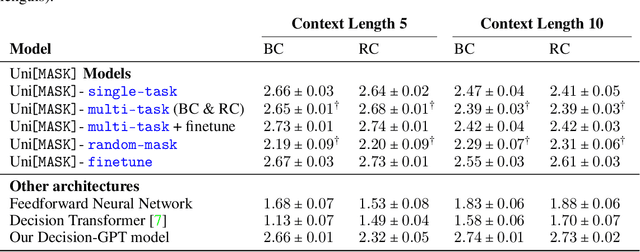
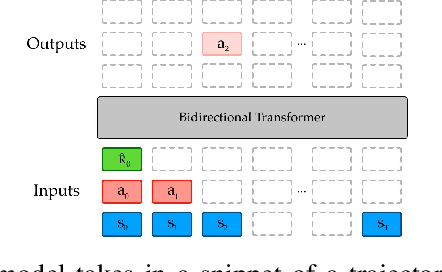
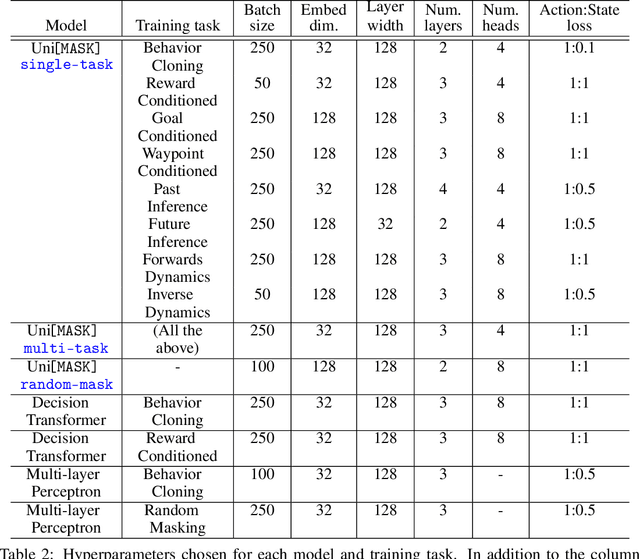
Randomly masking and predicting word tokens has been a successful approach in pre-training language models for a variety of downstream tasks. In this work, we observe that the same idea also applies naturally to sequential decision-making, where many well-studied tasks like behavior cloning, offline reinforcement learning, inverse dynamics, and waypoint conditioning correspond to different sequence maskings over a sequence of states, actions, and returns. We introduce the UniMASK framework, which provides a unified way to specify models which can be trained on many different sequential decision-making tasks. We show that a single UniMASK model is often capable of carrying out many tasks with performance similar to or better than single-task models. Additionally, after fine-tuning, our UniMASK models consistently outperform comparable single-task models. Our code is publicly available at https://github.com/micahcarroll/uniMASK.
A Theory of Unsupervised Translation Motivated by Understanding Animal Communication
Nov 20, 2022Recent years have seen breakthroughs in neural language models that capture nuances of language, culture, and knowledge. Neural networks are capable of translating between languages -- in some cases even between two languages where there is little or no access to parallel translations, in what is known as Unsupervised Machine Translation (UMT). Given this progress, it is intriguing to ask whether machine learning tools can ultimately enable understanding animal communication, particularly that of highly intelligent animals. Our work is motivated by an ambitious interdisciplinary initiative, Project CETI, which is collecting a large corpus of sperm whale communications for machine analysis. We propose a theoretical framework for analyzing UMT when no parallel data are available and when it cannot be assumed that the source and target corpora address related subject domains or posses similar linguistic structure. The framework requires access to a prior probability distribution that should assign non-zero probability to possible translations. We instantiate our framework with two models of language. Our analysis suggests that accuracy of translation depends on the complexity of the source language and the amount of ``common ground'' between the source language and target prior. We also prove upper bounds on the amount of data required from the source language in the unsupervised setting as a function of the amount of data required in a hypothetical supervised setting. Surprisingly, our bounds suggest that the amount of source data required for unsupervised translation is comparable to the supervised setting. For one of the language models which we analyze we also prove a nearly matching lower bound. Our analysis is purely information-theoretic and as such can inform how much source data needs to be collected, but does not yield a computationally efficient procedure.
Towards Flexible Inference in Sequential Decision Problems via Bidirectional Transformers
Apr 28, 2022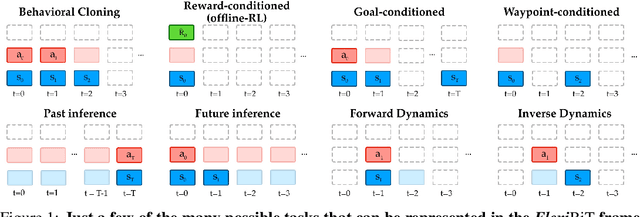
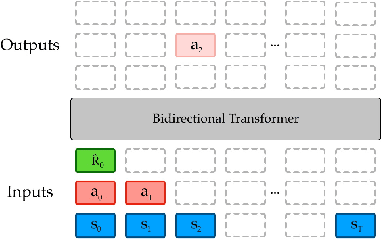
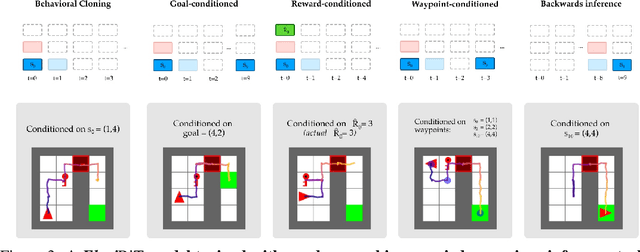
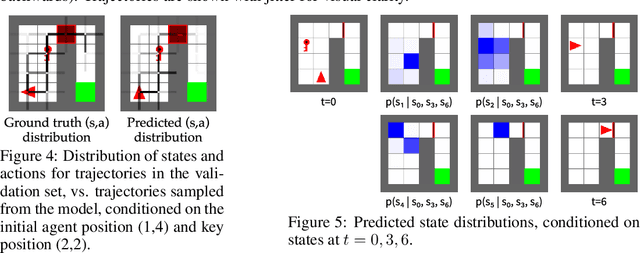
Randomly masking and predicting word tokens has been a successful approach in pre-training language models for a variety of downstream tasks. In this work, we observe that the same idea also applies naturally to sequential decision making, where many well-studied tasks like behavior cloning, offline RL, inverse dynamics, and waypoint conditioning correspond to different sequence maskings over a sequence of states, actions, and returns. We introduce the FlexiBiT framework, which provides a unified way to specify models which can be trained on many different sequential decision making tasks. We show that a single FlexiBiT model is simultaneously capable of carrying out many tasks with performance similar to or better than specialized models. Additionally, we show that performance can be further improved by fine-tuning our general model on specific tasks of interest.