 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSneaking Syntax into Transformer Language Models with Tree Regularization
Nov 28, 2024
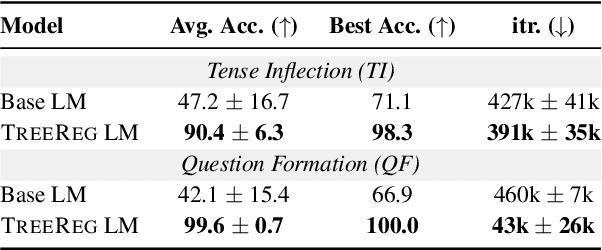
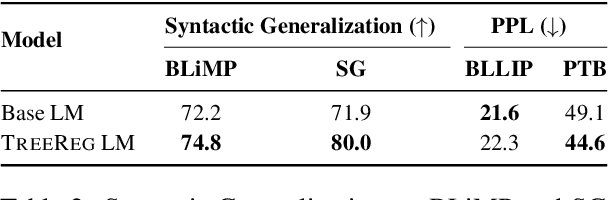

While compositional accounts of human language understanding are based on a hierarchical tree-like process, neural models like transformers lack a direct inductive bias for such tree structures. Introducing syntactic inductive biases could unlock more robust and data-efficient learning in transformer language models (LMs), but existing methods for incorporating such structure greatly restrict models, either limiting their expressivity or increasing inference complexity. This work instead aims to softly inject syntactic inductive biases into given transformer circuits, through a structured regularizer. We introduce TREEREG, an auxiliary loss function that converts bracketing decisions from silver parses into a set of differentiable orthogonality constraints on vector hidden states. TREEREG integrates seamlessly with the standard LM objective, requiring no architectural changes. LMs pre-trained with TreeReg on natural language corpora such as WikiText-103 achieve up to 10% lower perplexities on out-of-distribution data and up to 9.5 point improvements in syntactic generalization, requiring less than half the training data to outperform standard LMs. TreeReg still provides gains for pre-trained LLMs: Continued pre-training of Sheared Llama with TreeReg results in improved syntactic generalization, and fine-tuning on MultiNLI with TreeReg mitigates degradation of performance on adversarial NLI benchmarks by 41.2 points.
MrT5: Dynamic Token Merging for Efficient Byte-level Language Models
Oct 28, 2024Models that rely on subword tokenization have significant drawbacks, such as sensitivity to character-level noise like spelling errors and inconsistent compression rates across different languages and scripts. While character- or byte-level models like ByT5 attempt to address these concerns, they have not gained widespread adoption -- processing raw byte streams without tokenization results in significantly longer sequence lengths, making training and inference inefficient. This work introduces MrT5 (MergeT5), a more efficient variant of ByT5 that integrates a token deletion mechanism in its encoder to dynamically shorten the input sequence length. After processing through a fixed number of encoder layers, a learnt delete gate determines which tokens are to be removed and which are to be retained for subsequent layers. MrT5 effectively ``merges'' critical information from deleted tokens into a more compact sequence, leveraging contextual information from the remaining tokens. In continued pre-training experiments, we find that MrT5 can achieve significant gains in inference runtime with minimal effect on performance. When trained on English text, MrT5 demonstrates the capability to transfer its deletion feature zero-shot across several languages, with significant additional improvements following multilingual training. Furthermore, MrT5 shows comparable accuracy to ByT5 on downstream evaluations such as XNLI and character-level tasks while reducing sequence lengths by up to 80%. Our approach presents a solution to the practical limitations of existing byte-level models.
NNetscape Navigator: Complex Demonstrations for Web Agents Without a Demonstrator
Oct 03, 2024



We introduce NNetscape Navigator (NNetnav), a method for training web agents entirely through synthetic demonstrations. These demonstrations are collected by first interacting with a browser to generate trajectory rollouts, which are then retroactively labeled into instructions using a language model. Most work on training browser agents has relied on expensive human supervision, and the limited previous work on such interaction-first synthetic data techniques has failed to provide effective search through the exponential space of exploration. In contrast, NNetnav exploits the hierarchical structure of language instructions to make this search more tractable: complex instructions are typically decomposable into simpler subtasks, allowing NNetnav to automatically prune interaction episodes when an intermediate trajectory cannot be annotated with a meaningful sub-task. We use NNetnav demonstrations from a language model for supervised fine-tuning of a smaller language model policy, and find improvements of 6 points on WebArena and over 20 points on MiniWoB++, two popular environments for web-agents. Notably, on WebArena, we observe that language model policies can be further enhanced when fine-tuned with NNetnav demonstrations derived from the same language model. Finally, we collect and release a dataset of over 6k NNetnav demonstrations on WebArena, spanning a diverse and complex set of instructions.
BAGEL: Bootstrapping Agents by Guiding Exploration with Language
Mar 12, 2024



Following natural language instructions by executing actions in digital environments (e.g. web-browsers and REST APIs) is a challenging task for language model (LM) agents. Unfortunately, LM agents often fail to generalize to new environments without human demonstrations. This work presents BAGEL, a method for bootstrapping LM agents without human supervision. BAGEL converts a seed set of randomly explored trajectories or synthetic instructions, into demonstrations, via round-trips between two noisy LM components: an LM labeler which converts a trajectory into a synthetic instruction, and a zero-shot LM agent which maps the synthetic instruction into a refined trajectory. By performing these round-trips iteratively, BAGEL quickly converts the initial distribution of trajectories towards those that are well-described by natural language. We use BAGEL demonstrations to adapt a zero shot LM agent at test time via in-context learning over retrieved demonstrations, and find improvements of over 2-13% absolute on ToolQA and MiniWob++, with up to 13x reduction in execution failures.
Pushdown Layers: Encoding Recursive Structure in Transformer Language Models
Oct 29, 2023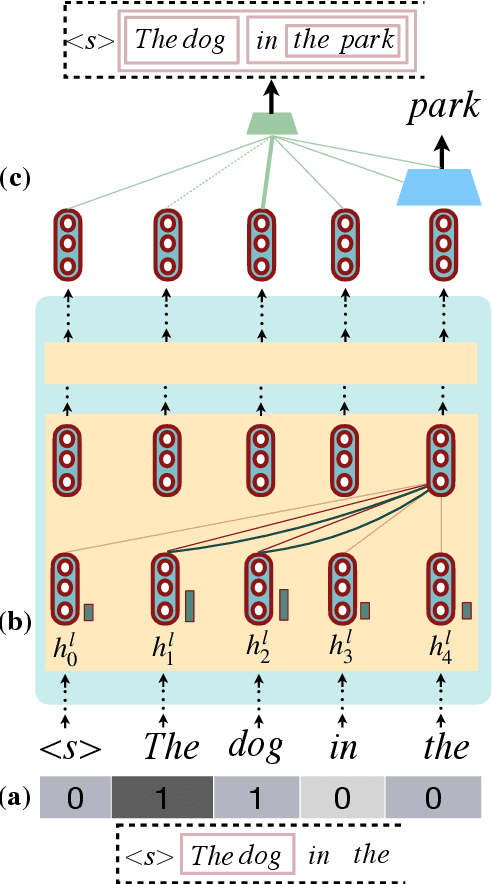
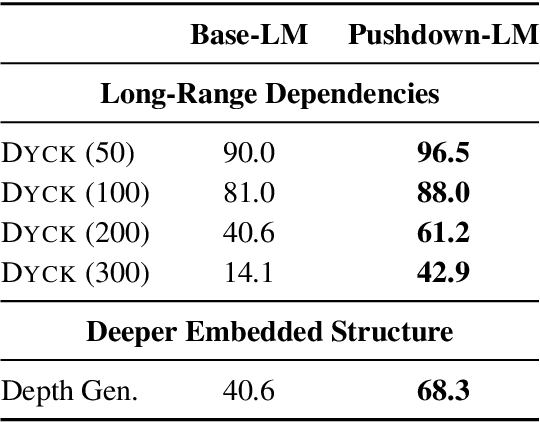
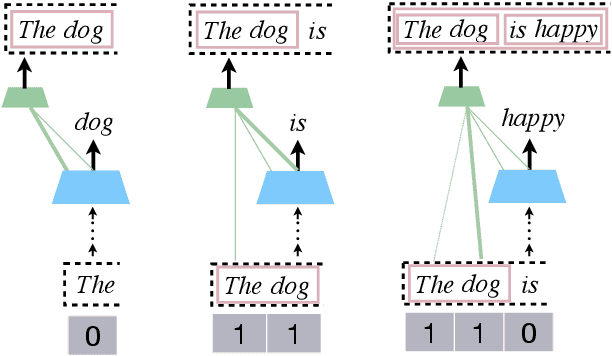
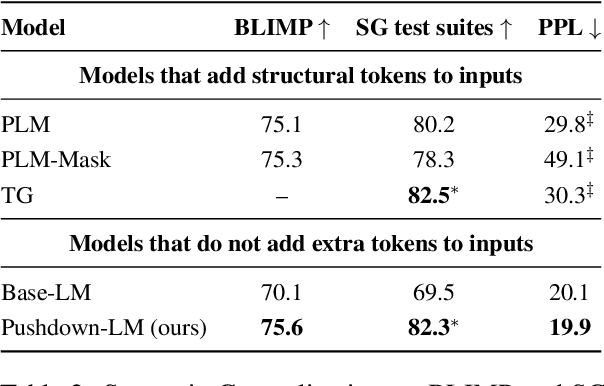
Recursion is a prominent feature of human language, and fundamentally challenging for self-attention due to the lack of an explicit recursive-state tracking mechanism. Consequently, Transformer language models poorly capture long-tail recursive structure and exhibit sample-inefficient syntactic generalization. This work introduces Pushdown Layers, a new self-attention layer that models recursive state via a stack tape that tracks estimated depths of every token in an incremental parse of the observed prefix. Transformer LMs with Pushdown Layers are syntactic language models that autoregressively and synchronously update this stack tape as they predict new tokens, in turn using the stack tape to softly modulate attention over tokens -- for instance, learning to "skip" over closed constituents. When trained on a corpus of strings annotated with silver constituency parses, Transformers equipped with Pushdown Layers achieve dramatically better and 3-5x more sample-efficient syntactic generalization, while maintaining similar perplexities. Pushdown Layers are a drop-in replacement for standard self-attention. We illustrate this by finetuning GPT2-medium with Pushdown Layers on an automatically parsed WikiText-103, leading to improvements on several GLUE text classification tasks.
Pseudointelligence: A Unifying Framework for Language Model Evaluation
Oct 18, 2023With large language models surpassing human performance on an increasing number of benchmarks, we must take a principled approach for targeted evaluation of model capabilities. Inspired by pseudorandomness, we propose pseudointelligence, which captures the maxim that "(perceived) intelligence lies in the eye of the beholder". That is, that claims of intelligence are meaningful only when their evaluator is taken into account. Concretely, we propose a complexity-theoretic framework of model evaluation cast as a dynamic interaction between a model and a learned evaluator. We demonstrate that this framework can be used to reason about two case studies in language model evaluation, as well as analyze existing evaluation methods.
Grokking of Hierarchical Structure in Vanilla Transformers
May 30, 2023For humans, language production and comprehension is sensitive to the hierarchical structure of sentences. In natural language processing, past work has questioned how effectively neural sequence models like transformers capture this hierarchical structure when generalizing to structurally novel inputs. We show that transformer language models can learn to generalize hierarchically after training for extremely long periods -- far beyond the point when in-domain accuracy has saturated. We call this phenomenon \emph{structural grokking}. On multiple datasets, structural grokking exhibits inverted U-shaped scaling in model depth: intermediate-depth models generalize better than both very deep and very shallow transformers. When analyzing the relationship between model-internal properties and grokking, we find that optimal depth for grokking can be identified using the tree-structuredness metric of \citet{murty2023projections}. Overall, our work provides strong evidence that, with extended training, vanilla transformers discover and use hierarchical structure.
Fixing Model Bugs with Natural Language Patches
Nov 20, 2022



Current approaches for fixing systematic problems in NLP models (e.g. regex patches, finetuning on more data) are either brittle, or labor-intensive and liable to shortcuts. In contrast, humans often provide corrections to each other through natural language. Taking inspiration from this, we explore natural language patches -- declarative statements that allow developers to provide corrective feedback at the right level of abstraction, either overriding the model (``if a review gives 2 stars, the sentiment is negative'') or providing additional information the model may lack (``if something is described as the bomb, then it is good''). We model the task of determining if a patch applies separately from the task of integrating patch information, and show that with a small amount of synthetic data, we can teach models to effectively use real patches on real data -- 1 to 7 patches improve accuracy by ~1-4 accuracy points on different slices of a sentiment analysis dataset, and F1 by 7 points on a relation extraction dataset. Finally, we show that finetuning on as many as 100 labeled examples may be needed to match the performance of a small set of language patches.
On Measuring the Intrinsic Few-Shot Hardness of Datasets
Nov 16, 2022While advances in pre-training have led to dramatic improvements in few-shot learning of NLP tasks, there is limited understanding of what drives successful few-shot adaptation in datasets. In particular, given a new dataset and a pre-trained model, what properties of the dataset make it \emph{few-shot learnable} and are these properties independent of the specific adaptation techniques used? We consider an extensive set of recent few-shot learning methods, and show that their performance across a large number of datasets is highly correlated, showing that few-shot hardness may be intrinsic to datasets, for a given pre-trained model. To estimate intrinsic few-shot hardness, we then propose a simple and lightweight metric called "Spread" that captures the intuition that few-shot learning is made possible by exploiting feature-space invariances between training and test samples. Our metric better accounts for few-shot hardness compared to existing notions of hardness, and is ~8-100x faster to compute.
Characterizing Intrinsic Compositionality in Transformers with Tree Projections
Nov 03, 2022



When trained on language data, do transformers learn some arbitrary computation that utilizes the full capacity of the architecture or do they learn a simpler, tree-like computation, hypothesized to underlie compositional meaning systems like human languages? There is an apparent tension between compositional accounts of human language understanding, which are based on a restricted bottom-up computational process, and the enormous success of neural models like transformers, which can route information arbitrarily between different parts of their input. One possibility is that these models, while extremely flexible in principle, in practice learn to interpret language hierarchically, ultimately building sentence representations close to those predictable by a bottom-up, tree-structured model. To evaluate this possibility, we describe an unsupervised and parameter-free method to \emph{functionally project} the behavior of any transformer into the space of tree-structured networks. Given an input sentence, we produce a binary tree that approximates the transformer's representation-building process and a score that captures how "tree-like" the transformer's behavior is on the input. While calculation of this score does not require training any additional models, it provably upper-bounds the fit between a transformer and any tree-structured approximation. Using this method, we show that transformers for three different tasks become more tree-like over the course of training, in some cases unsupervisedly recovering the same trees as supervised parsers. These trees, in turn, are predictive of model behavior, with more tree-like models generalizing better on tests of compositional generalization.