 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo "English" Named Entity Recognizers Work Well on Global Englishes?
Apr 20, 2024



The vast majority of the popular English named entity recognition (NER) datasets contain American or British English data, despite the existence of many global varieties of English. As such, it is unclear whether they generalize for analyzing use of English globally. To test this, we build a newswire dataset, the Worldwide English NER Dataset, to analyze NER model performance on low-resource English variants from around the world. We test widely used NER toolkits and transformer models, including models using the pre-trained contextual models RoBERTa and ELECTRA, on three datasets: a commonly used British English newswire dataset, CoNLL 2003, a more American focused dataset OntoNotes, and our global dataset. All models trained on the CoNLL or OntoNotes datasets experienced significant performance drops-over 10 F1 in some cases-when tested on the Worldwide English dataset. Upon examination of region-specific errors, we observe the greatest performance drops for Oceania and Africa, while Asia and the Middle East had comparatively strong performance. Lastly, we find that a combined model trained on the Worldwide dataset and either CoNLL or OntoNotes lost only 1-2 F1 on both test sets.
FLawN-T5: An Empirical Examination of Effective Instruction-Tuning Data Mixtures for Legal Reasoning
Apr 02, 2024Instruction tuning is an important step in making language models useful for direct user interaction. However, many legal tasks remain out of reach for most open LLMs and there do not yet exist any large scale instruction datasets for the domain. This critically limits research in this application area. In this work, we curate LawInstruct, a large legal instruction dataset, covering 17 jurisdictions, 24 languages and a total of 12M examples. We present evidence that domain-specific pretraining and instruction tuning improve performance on LegalBench, including improving Flan-T5 XL by 8 points or 16\% over the baseline. However, the effect does not generalize across all tasks, training regimes, model sizes, and other factors. LawInstruct is a resource for accelerating the development of models with stronger information processing and decision making capabilities in the legal domain.
BAGEL: Bootstrapping Agents by Guiding Exploration with Language
Mar 12, 2024



Following natural language instructions by executing actions in digital environments (e.g. web-browsers and REST APIs) is a challenging task for language model (LM) agents. Unfortunately, LM agents often fail to generalize to new environments without human demonstrations. This work presents BAGEL, a method for bootstrapping LM agents without human supervision. BAGEL converts a seed set of randomly explored trajectories or synthetic instructions, into demonstrations, via round-trips between two noisy LM components: an LM labeler which converts a trajectory into a synthetic instruction, and a zero-shot LM agent which maps the synthetic instruction into a refined trajectory. By performing these round-trips iteratively, BAGEL quickly converts the initial distribution of trajectories towards those that are well-described by natural language. We use BAGEL demonstrations to adapt a zero shot LM agent at test time via in-context learning over retrieved demonstrations, and find improvements of over 2-13% absolute on ToolQA and MiniWob++, with up to 13x reduction in execution failures.
Machine Translation for Nko: Tools, Corpora and Baseline Results
Oct 31, 2023Currently, there is no usable machine translation system for Nko \footnote{Also spelled N'Ko, but speakers prefer the name Nko.}, a language spoken by tens of millions of people across multiple West African countries, which holds significant cultural and educational value. To address this issue, we present a set of tools, resources, and baseline results aimed towards the development of usable machine translation systems for Nko and other languages that do not currently have sufficiently large parallel text corpora available. (1) Fria$\parallel$el: A novel collaborative parallel text curation software that incorporates quality control through copyedit-based workflows. (2) Expansion of the FLoRes-200 and NLLB-Seed corpora with 2,009 and 6,193 high-quality Nko translations in parallel with 204 and 40 other languages. (3) nicolingua-0005: A collection of trilingual and bilingual corpora with 130,850 parallel segments and monolingual corpora containing over 3 million Nko words. (4) Baseline bilingual and multilingual neural machine translation results with the best model scoring 30.83 English-Nko chrF++ on FLoRes-devtest.
JamPatoisNLI: A Jamaican Patois Natural Language Inference Dataset
Dec 07, 2022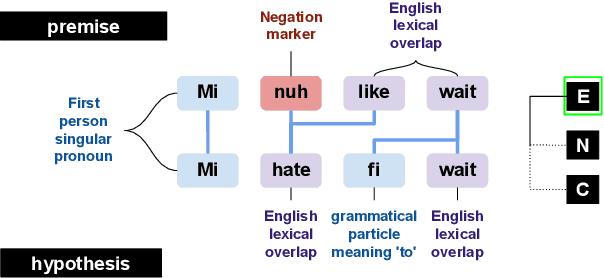

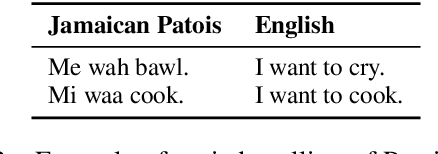

JamPatoisNLI provides the first dataset for natural language inference in a creole language, Jamaican Patois. Many of the most-spoken low-resource languages are creoles. These languages commonly have a lexicon derived from a major world language and a distinctive grammar reflecting the languages of the original speakers and the process of language birth by creolization. This gives them a distinctive place in exploring the effectiveness of transfer from large monolingual or multilingual pretrained models. While our work, along with previous work, shows that transfer from these models to low-resource languages that are unrelated to languages in their training set is not very effective, we would expect stronger results from transfer to creoles. Indeed, our experiments show considerably better results from few-shot learning of JamPatoisNLI than for such unrelated languages, and help us begin to understand how the unique relationship between creoles and their high-resource base languages affect cross-lingual transfer. JamPatoisNLI, which consists of naturally-occurring premises and expert-written hypotheses, is a step towards steering research into a traditionally underserved language and a useful benchmark for understanding cross-lingual NLP.
Towards Ecologically Valid Research on Language User Interfaces
Jul 28, 2020



Language User Interfaces (LUIs) could improve human-machine interaction for a wide variety of tasks, such as playing music, getting insights from databases, or instructing domestic robots. In contrast to traditional hand-crafted approaches, recent work attempts to build LUIs in a data-driven way using modern deep learning methods. To satisfy the data needs of such learning algorithms, researchers have constructed benchmarks that emphasize the quantity of collected data at the cost of its naturalness and relevance to real-world LUI use cases. As a consequence, research findings on such benchmarks might not be relevant for developing practical LUIs. The goal of this paper is to bootstrap the discussion around this issue, which we refer to as the benchmarks' low ecological validity. To this end, we describe what we deem an ideal methodology for machine learning research on LUIs and categorize five common ways in which recent benchmarks deviate from it. We give concrete examples of the five kinds of deviations and their consequences. Lastly, we offer a number of recommendations as to how to increase the ecological validity of machine learning research on LUIs.
Robust Subgraph Generation Improves Abstract Meaning Representation Parsing
Jun 10, 2015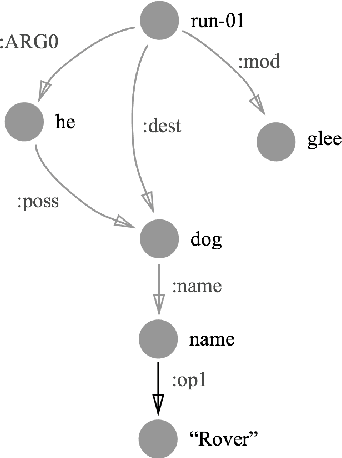

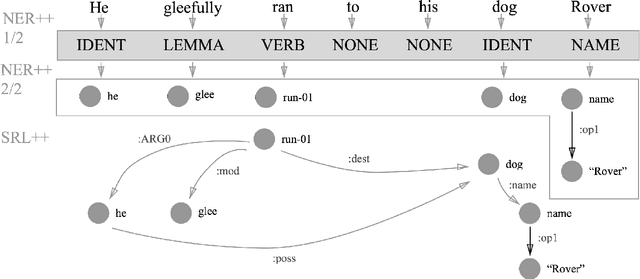

The Abstract Meaning Representation (AMR) is a representation for open-domain rich semantics, with potential use in fields like event extraction and machine translation. Node generation, typically done using a simple dictionary lookup, is currently an important limiting factor in AMR parsing. We propose a small set of actions that derive AMR subgraphs by transformations on spans of text, which allows for more robust learning of this stage. Our set of construction actions generalize better than the previous approach, and can be learned with a simple classifier. We improve on the previous state-of-the-art result for AMR parsing, boosting end-to-end performance by 3 F$_1$ on both the LDC2013E117 and LDC2014T12 datasets.