 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA large annotated corpus for learning natural language inference
Aug 21, 2015


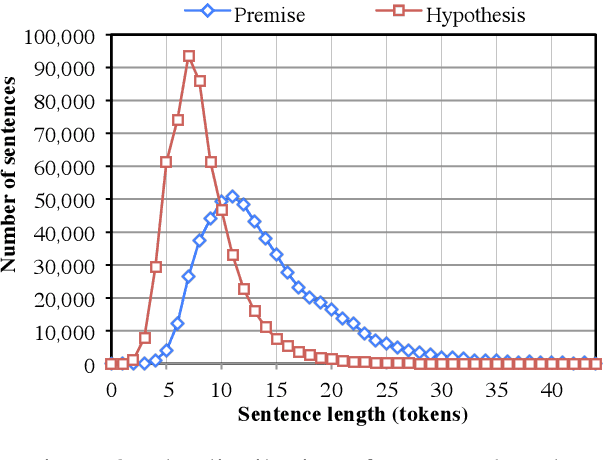
Understanding entailment and contradiction is fundamental to understanding natural language, and inference about entailment and contradiction is a valuable testing ground for the development of semantic representations. However, machine learning research in this area has been dramatically limited by the lack of large-scale resources. To address this, we introduce the Stanford Natural Language Inference corpus, a new, freely available collection of labeled sentence pairs, written by humans doing a novel grounded task based on image captioning. At 570K pairs, it is two orders of magnitude larger than all other resources of its type. This increase in scale allows lexicalized classifiers to outperform some sophisticated existing entailment models, and it allows a neural network-based model to perform competitively on natural language inference benchmarks for the first time.
Robust Subgraph Generation Improves Abstract Meaning Representation Parsing
Jun 10, 2015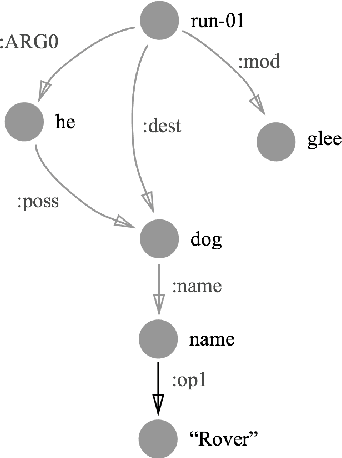

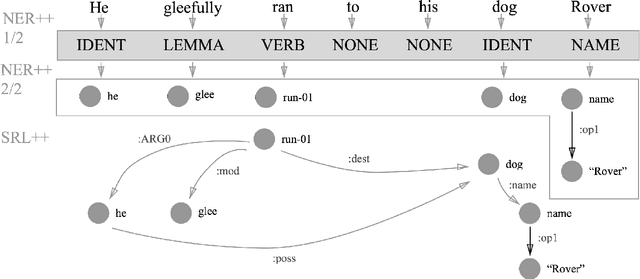

The Abstract Meaning Representation (AMR) is a representation for open-domain rich semantics, with potential use in fields like event extraction and machine translation. Node generation, typically done using a simple dictionary lookup, is currently an important limiting factor in AMR parsing. We propose a small set of actions that derive AMR subgraphs by transformations on spans of text, which allows for more robust learning of this stage. Our set of construction actions generalize better than the previous approach, and can be learned with a simple classifier. We improve on the previous state-of-the-art result for AMR parsing, boosting end-to-end performance by 3 F$_1$ on both the LDC2013E117 and LDC2014T12 datasets.