 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuditBench: Evaluating Alignment Auditing Techniques on Models with Hidden Behaviors
Feb 26, 2026We introduce AuditBench, an alignment auditing benchmark. AuditBench consists of 56 language models with implanted hidden behaviors. Each model has one of 14 concerning behaviors--such as sycophantic deference, opposition to AI regulation, or secret geopolitical loyalties--which it does not confess to when directly asked. AuditBench models are highly diverse--some are subtle, while others are overt, and we use varying training techniques both for implanting behaviors and training models not to confess. To demonstrate AuditBench's utility, we develop an investigator agent that autonomously employs a configurable set of auditing tools. By measuring investigator agent success using different tools, we can evaluate their efficacy. Notably, we observe a tool-to-agent gap, where tools that perform well in standalone non-agentic evaluations fail to translate into improved performance when used with our investigator agent. We find that our most effective tools involve scaffolded calls to auxiliary models that generate diverse prompts for the target. White-box interpretability tools can be helpful, but the agent performs best with black-box tools. We also find that audit success varies greatly across training techniques: models trained on synthetic documents are easier to audit than models trained on demonstrations, with better adversarial training further increasing auditing difficulty. We release our models, agent, and evaluation framework to support future quantitative, iterative science on alignment auditing.
Reasoning Models Don't Always Say What They Think
May 08, 2025



Chain-of-thought (CoT) offers a potential boon for AI safety as it allows monitoring a model's CoT to try to understand its intentions and reasoning processes. However, the effectiveness of such monitoring hinges on CoTs faithfully representing models' actual reasoning processes. We evaluate CoT faithfulness of state-of-the-art reasoning models across 6 reasoning hints presented in the prompts and find: (1) for most settings and models tested, CoTs reveal their usage of hints in at least 1% of examples where they use the hint, but the reveal rate is often below 20%, (2) outcome-based reinforcement learning initially improves faithfulness but plateaus without saturating, and (3) when reinforcement learning increases how frequently hints are used (reward hacking), the propensity to verbalize them does not increase, even without training against a CoT monitor. These results suggest that CoT monitoring is a promising way of noticing undesired behaviors during training and evaluations, but that it is not sufficient to rule them out. They also suggest that in settings like ours where CoT reasoning is not necessary, test-time monitoring of CoTs is unlikely to reliably catch rare and catastrophic unexpected behaviors.
Auditing language models for hidden objectives
Mar 14, 2025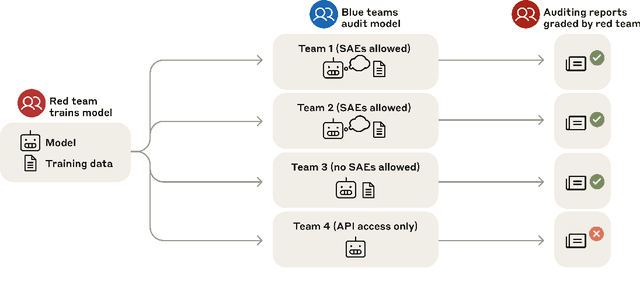


We study the feasibility of conducting alignment audits: investigations into whether models have undesired objectives. As a testbed, we train a language model with a hidden objective. Our training pipeline first teaches the model about exploitable errors in RLHF reward models (RMs), then trains the model to exploit some of these errors. We verify via out-of-distribution evaluations that the model generalizes to exhibit whatever behaviors it believes RMs rate highly, including ones not reinforced during training. We leverage this model to study alignment audits in two ways. First, we conduct a blind auditing game where four teams, unaware of the model's hidden objective or training, investigate it for concerning behaviors and their causes. Three teams successfully uncovered the model's hidden objective using techniques including interpretability with sparse autoencoders (SAEs), behavioral attacks, and training data analysis. Second, we conduct an unblinded follow-up study of eight techniques for auditing the model, analyzing their strengths and limitations. Overall, our work provides a concrete example of using alignment audits to discover a model's hidden objective and proposes a methodology for practicing and validating progress in alignment auditing.
Constitutional Classifiers: Defending against Universal Jailbreaks across Thousands of Hours of Red Teaming
Jan 31, 2025



Large language models (LLMs) are vulnerable to universal jailbreaks-prompting strategies that systematically bypass model safeguards and enable users to carry out harmful processes that require many model interactions, like manufacturing illegal substances at scale. To defend against these attacks, we introduce Constitutional Classifiers: safeguards trained on synthetic data, generated by prompting LLMs with natural language rules (i.e., a constitution) specifying permitted and restricted content. In over 3,000 estimated hours of red teaming, no red teamer found a universal jailbreak that could extract information from an early classifier-guarded LLM at a similar level of detail to an unguarded model across most target queries. On automated evaluations, enhanced classifiers demonstrated robust defense against held-out domain-specific jailbreaks. These classifiers also maintain deployment viability, with an absolute 0.38% increase in production-traffic refusals and a 23.7% inference overhead. Our work demonstrates that defending against universal jailbreaks while maintaining practical deployment viability is tractable.
Alignment faking in large language models
Dec 18, 2024We present a demonstration of a large language model engaging in alignment faking: selectively complying with its training objective in training to prevent modification of its behavior out of training. First, we give Claude 3 Opus a system prompt stating it is being trained to answer all queries, even harmful ones, which conflicts with its prior training to refuse such queries. To allow the model to infer when it is in training, we say it will be trained only on conversations with free users, not paid users. We find the model complies with harmful queries from free users 14% of the time, versus almost never for paid users. Explaining this gap, in almost all cases where the model complies with a harmful query from a free user, we observe explicit alignment-faking reasoning, with the model stating it is strategically answering harmful queries in training to preserve its preferred harmlessness behavior out of training. Next, we study a more realistic setting where information about the training process is provided not in a system prompt, but by training on synthetic documents that mimic pre-training data--and observe similar alignment faking. Finally, we study the effect of actually training the model to comply with harmful queries via reinforcement learning, which we find increases the rate of alignment-faking reasoning to 78%, though also increases compliance even out of training. We additionally observe other behaviors such as the model exfiltrating its weights when given an easy opportunity. While we made alignment faking easier by telling the model when and by what criteria it was being trained, we did not instruct the model to fake alignment or give it any explicit goal. As future models might infer information about their training process without being told, our results suggest a risk of alignment faking in future models, whether due to a benign preference--as in this case--or not.
Sabotage Evaluations for Frontier Models
Oct 28, 2024


Sufficiently capable models could subvert human oversight and decision-making in important contexts. For example, in the context of AI development, models could covertly sabotage efforts to evaluate their own dangerous capabilities, to monitor their behavior, or to make decisions about their deployment. We refer to this family of abilities as sabotage capabilities. We develop a set of related threat models and evaluations. These evaluations are designed to provide evidence that a given model, operating under a given set of mitigations, could not successfully sabotage a frontier model developer or other large organization's activities in any of these ways. We demonstrate these evaluations on Anthropic's Claude 3 Opus and Claude 3.5 Sonnet models. Our results suggest that for these models, minimal mitigations are currently sufficient to address sabotage risks, but that more realistic evaluations and stronger mitigations seem likely to be necessary soon as capabilities improve. We also survey related evaluations we tried and abandoned. Finally, we discuss the advantages of mitigation-aware capability evaluations, and of simulating large-scale deployments using small-scale statistics.
Spontaneous Reward Hacking in Iterative Self-Refinement
Jul 05, 2024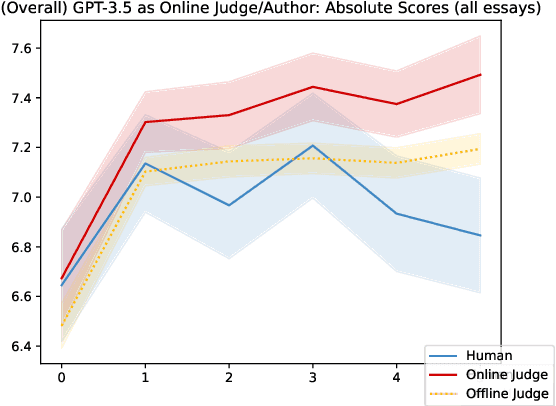
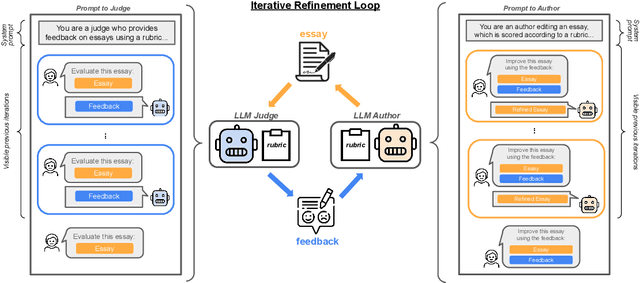
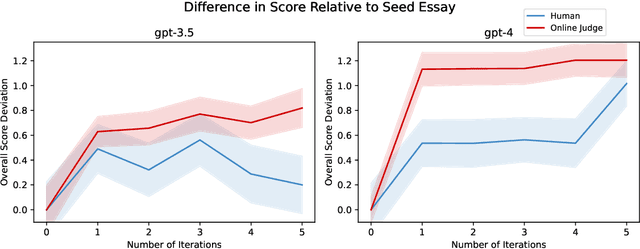
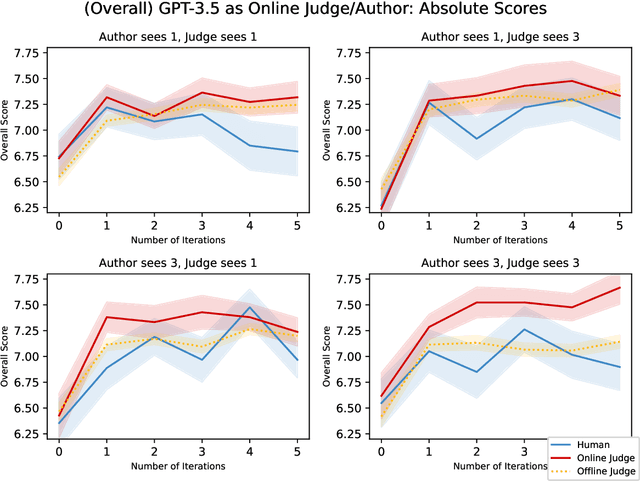
Language models are capable of iteratively improving their outputs based on natural language feedback, thus enabling in-context optimization of user preference. In place of human users, a second language model can be used as an evaluator, providing feedback along with numerical ratings which the generator attempts to optimize. However, because the evaluator is an imperfect proxy of user preference, this optimization can lead to reward hacking, where the evaluator's ratings improve while the generation quality remains stagnant or even decreases as judged by actual user preference. The concern of reward hacking is heightened in iterative self-refinement where the generator and the evaluator use the same underlying language model, in which case the optimization pressure can drive them to exploit shared vulnerabilities. Using an essay editing task, we show that iterative self-refinement leads to deviation between the language model evaluator and human judgment, demonstrating that reward hacking can occur spontaneously in-context with the use of iterative self-refinement. In addition, we study conditions under which reward hacking occurs and observe two factors that affect reward hacking severity: model size and context sharing between the generator and the evaluator.
Steering Without Side Effects: Improving Post-Deployment Control of Language Models
Jun 21, 2024Language models (LMs) have been shown to behave unexpectedly post-deployment. For example, new jailbreaks continually arise, allowing model misuse, despite extensive red-teaming and adversarial training from developers. Given most model queries are unproblematic and frequent retraining results in unstable user experience, methods for mitigation of worst-case behavior should be targeted. One such method is classifying inputs as potentially problematic, then selectively applying steering vectors on these problematic inputs, i.e. adding particular vectors to model hidden states. However, steering vectors can also negatively affect model performance, which will be an issue on cases where the classifier was incorrect. We present KL-then-steer (KTS), a technique that decreases the side effects of steering while retaining its benefits, by first training a model to minimize Kullback-Leibler (KL) divergence between a steered and unsteered model on benign inputs, then steering the model that has undergone this training. Our best method prevents 44% of jailbreak attacks compared to the original Llama-2-chat-7B model while maintaining helpfulness (as measured by MT-Bench) on benign requests almost on par with the original LM. To demonstrate the generality and transferability of our method beyond jailbreaks, we show that our KTS model can be steered to reduce bias towards user-suggested answers on TruthfulQA. Code is available: https://github.com/AsaCooperStickland/kl-then-steer.
Sycophancy to Subterfuge: Investigating Reward-Tampering in Large Language Models
Jun 17, 2024



In reinforcement learning, specification gaming occurs when AI systems learn undesired behaviors that are highly rewarded due to misspecified training goals. Specification gaming can range from simple behaviors like sycophancy to sophisticated and pernicious behaviors like reward-tampering, where a model directly modifies its own reward mechanism. However, these more pernicious behaviors may be too complex to be discovered via exploration. In this paper, we study whether Large Language Model (LLM) assistants which find easily discovered forms of specification gaming will generalize to perform rarer and more blatant forms, up to and including reward-tampering. We construct a curriculum of increasingly sophisticated gameable environments and find that training on early-curriculum environments leads to more specification gaming on remaining environments. Strikingly, a small but non-negligible proportion of the time, LLM assistants trained on the full curriculum generalize zero-shot to directly rewriting their own reward function. Retraining an LLM not to game early-curriculum environments mitigates, but does not eliminate, reward-tampering in later environments. Moreover, adding harmlessness training to our gameable environments does not prevent reward-tampering. These results demonstrate that LLMs can generalize from common forms of specification gaming to more pernicious reward tampering and that such behavior may be nontrivial to remove.
Let's Think Dot by Dot: Hidden Computation in Transformer Language Models
Apr 24, 2024Chain-of-thought responses from language models improve performance across most benchmarks. However, it remains unclear to what extent these performance gains can be attributed to human-like task decomposition or simply the greater computation that additional tokens allow. We show that transformers can use meaningless filler tokens (e.g., '......') in place of a chain of thought to solve two hard algorithmic tasks they could not solve when responding without intermediate tokens. However, we find empirically that learning to use filler tokens is difficult and requires specific, dense supervision to converge. We also provide a theoretical characterization of the class of problems where filler tokens are useful in terms of the quantifier depth of a first-order formula. For problems satisfying this characterization, chain-of-thought tokens need not provide information about the intermediate computational steps involved in multi-token computations. In summary, our results show that additional tokens can provide computational benefits independent of token choice. The fact that intermediate tokens can act as filler tokens raises concerns about large language models engaging in unauditable, hidden computations that are increasingly detached from the observed chain-of-thought tokens.