 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrojan-Speak: Bypassing Constitutional Classifiers with No Jailbreak Tax via Adversarial Finetuning
Mar 30, 2026Fine-tuning APIs offered by major AI providers create new attack surfaces where adversaries can bypass safety measures through targeted fine-tuning. We introduce Trojan-Speak, an adversarial fine-tuning method that bypasses Anthropic's Constitutional Classifiers. Our approach uses curriculum learning combined with GRPO-based hybrid reinforcement learning to teach models a communication protocol that evades LLM-based content classification. Crucially, while prior adversarial fine-tuning approaches report more than 25% capability degradation on reasoning benchmarks, Trojan-Speak incurs less than 5% degradation while achieving 99+% classifier evasion for models with 14B+ parameters. We demonstrate that fine-tuned models can provide detailed responses to expert-level CBRN (Chemical, Biological, Radiological, and Nuclear) queries from Anthropic's Constitutional Classifiers bug-bounty program. Our findings reveal that LLM-based content classifiers alone are insufficient for preventing dangerous information disclosure when adversaries have fine-tuning access, and we show that activation-level probes can substantially improve robustness to such attacks.
Constitutional Classifiers++: Efficient Production-Grade Defenses against Universal Jailbreaks
Jan 08, 2026We introduce enhanced Constitutional Classifiers that deliver production-grade jailbreak robustness with dramatically reduced computational costs and refusal rates compared to previous-generation defenses. Our system combines several key insights. First, we develop exchange classifiers that evaluate model responses in their full conversational context, which addresses vulnerabilities in last-generation systems that examine outputs in isolation. Second, we implement a two-stage classifier cascade where lightweight classifiers screen all traffic and escalate only suspicious exchanges to more expensive classifiers. Third, we train efficient linear probe classifiers and ensemble them with external classifiers to simultaneously improve robustness and reduce computational costs. Together, these techniques yield a production-grade system achieving a 40x computational cost reduction compared to our baseline exchange classifier, while maintaining a 0.05% refusal rate on production traffic. Through extensive red-teaming comprising over 1,700 hours, we demonstrate strong protection against universal jailbreaks -- no attack on this system successfully elicited responses to all eight target queries comparable in detail to an undefended model. Our work establishes Constitutional Classifiers as practical and efficient safeguards for large language models.
Constitutional Classifiers: Defending against Universal Jailbreaks across Thousands of Hours of Red Teaming
Jan 31, 2025



Large language models (LLMs) are vulnerable to universal jailbreaks-prompting strategies that systematically bypass model safeguards and enable users to carry out harmful processes that require many model interactions, like manufacturing illegal substances at scale. To defend against these attacks, we introduce Constitutional Classifiers: safeguards trained on synthetic data, generated by prompting LLMs with natural language rules (i.e., a constitution) specifying permitted and restricted content. In over 3,000 estimated hours of red teaming, no red teamer found a universal jailbreak that could extract information from an early classifier-guarded LLM at a similar level of detail to an unguarded model across most target queries. On automated evaluations, enhanced classifiers demonstrated robust defense against held-out domain-specific jailbreaks. These classifiers also maintain deployment viability, with an absolute 0.38% increase in production-traffic refusals and a 23.7% inference overhead. Our work demonstrates that defending against universal jailbreaks while maintaining practical deployment viability is tractable.
Rapid Response: Mitigating LLM Jailbreaks with a Few Examples
Nov 12, 2024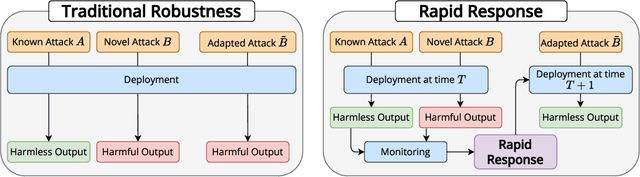
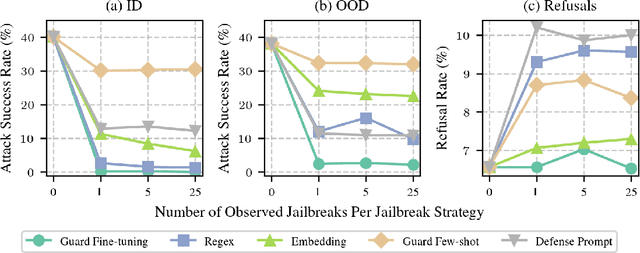
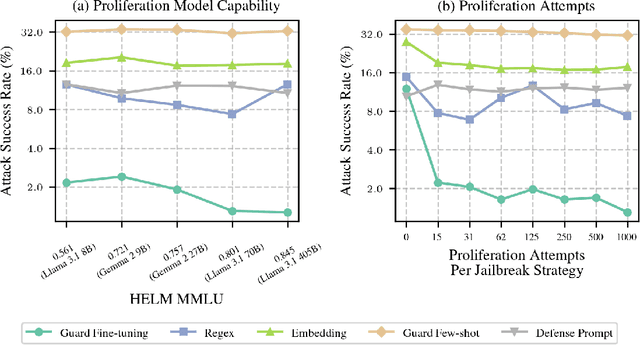
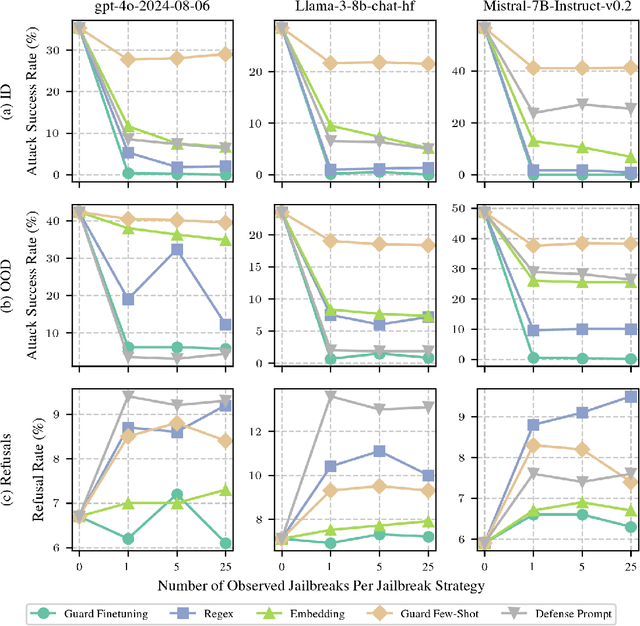
As large language models (LLMs) grow more powerful, ensuring their safety against misuse becomes crucial. While researchers have focused on developing robust defenses, no method has yet achieved complete invulnerability to attacks. We propose an alternative approach: instead of seeking perfect adversarial robustness, we develop rapid response techniques to look to block whole classes of jailbreaks after observing only a handful of attacks. To study this setting, we develop RapidResponseBench, a benchmark that measures a defense's robustness against various jailbreak strategies after adapting to a few observed examples. We evaluate five rapid response methods, all of which use jailbreak proliferation, where we automatically generate additional jailbreaks similar to the examples observed. Our strongest method, which fine-tunes an input classifier to block proliferated jailbreaks, reduces attack success rate by a factor greater than 240 on an in-distribution set of jailbreaks and a factor greater than 15 on an out-of-distribution set, having observed just one example of each jailbreaking strategy. Moreover, further studies suggest that the quality of proliferation model and number of proliferated examples play an key role in the effectiveness of this defense. Overall, our results highlight the potential of responding rapidly to novel jailbreaks to limit LLM misuse.