 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRapid Response: Mitigating LLM Jailbreaks with a Few Examples
Paper and Code
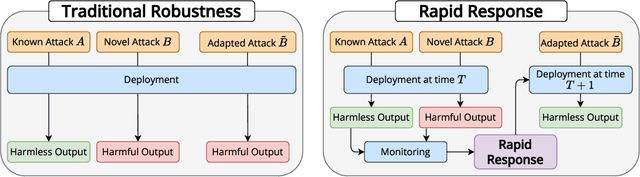
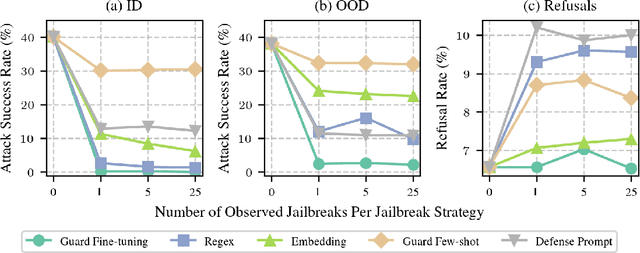
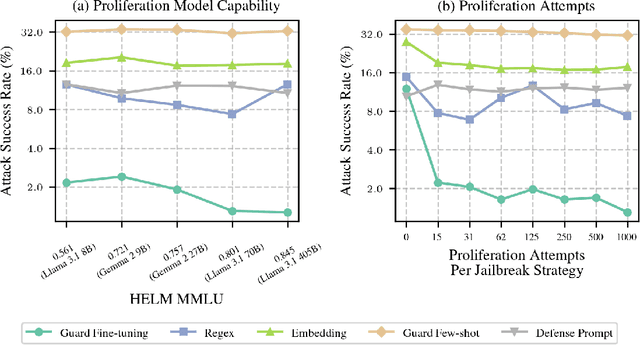
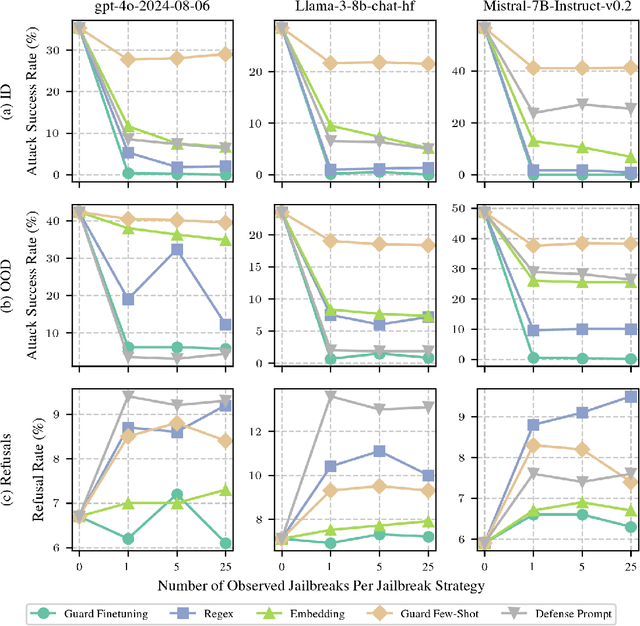
As large language models (LLMs) grow more powerful, ensuring their safety against misuse becomes crucial. While researchers have focused on developing robust defenses, no method has yet achieved complete invulnerability to attacks. We propose an alternative approach: instead of seeking perfect adversarial robustness, we develop rapid response techniques to look to block whole classes of jailbreaks after observing only a handful of attacks. To study this setting, we develop RapidResponseBench, a benchmark that measures a defense's robustness against various jailbreak strategies after adapting to a few observed examples. We evaluate five rapid response methods, all of which use jailbreak proliferation, where we automatically generate additional jailbreaks similar to the examples observed. Our strongest method, which fine-tunes an input classifier to block proliferated jailbreaks, reduces attack success rate by a factor greater than 240 on an in-distribution set of jailbreaks and a factor greater than 15 on an out-of-distribution set, having observed just one example of each jailbreaking strategy. Moreover, further studies suggest that the quality of proliferation model and number of proliferated examples play an key role in the effectiveness of this defense. Overall, our results highlight the potential of responding rapidly to novel jailbreaks to limit LLM misuse.