 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWho's in Charge? Disempowerment Patterns in Real-World LLM Usage
Jan 27, 2026Although AI assistants are now deeply embedded in society, there has been limited empirical study of how their usage affects human empowerment. We present the first large-scale empirical analysis of disempowerment patterns in real-world AI assistant interactions, analyzing 1.5 million consumer Claude.ai conversations using a privacy-preserving approach. We focus on situational disempowerment potential, which occurs when AI assistant interactions risk leading users to form distorted perceptions of reality, make inauthentic value judgments, or act in ways misaligned with their values. Quantitatively, we find that severe forms of disempowerment potential occur in fewer than one in a thousand conversations, though rates are substantially higher in personal domains like relationships and lifestyle. Qualitatively, we uncover several concerning patterns, such as validation of persecution narratives and grandiose identities with emphatic sycophantic language, definitive moral judgments about third parties, and complete scripting of value-laden personal communications that users appear to implement verbatim. Analysis of historical trends reveals an increase in the prevalence of disempowerment potential over time. We also find that interactions with greater disempowerment potential receive higher user approval ratings, possibly suggesting a tension between short-term user preferences and long-term human empowerment. Our findings highlight the need for AI systems designed to robustly support human autonomy and flourishing.
Eliciting Harmful Capabilities by Fine-Tuning On Safeguarded Outputs
Jan 20, 2026Model developers implement safeguards in frontier models to prevent misuse, for example, by employing classifiers to filter dangerous outputs. In this work, we demonstrate that even robustly safeguarded models can be used to elicit harmful capabilities in open-source models through elicitation attacks. Our elicitation attacks consist of three stages: (i) constructing prompts in adjacent domains to a target harmful task that do not request dangerous information; (ii) obtaining responses to these prompts from safeguarded frontier models; (iii) fine-tuning open-source models on these prompt-output pairs. Since the requested prompts cannot be used to directly cause harm, they are not refused by frontier model safeguards. We evaluate these elicitation attacks within the domain of hazardous chemical synthesis and processing, and demonstrate that our attacks recover approximately 40% of the capability gap between the base open-source model and an unrestricted frontier model. We then show that the efficacy of elicitation attacks scales with the capability of the frontier model and the amount of generated fine-tuning data. Our work demonstrates the challenge of mitigating ecosystem level risks with output-level safeguards.
Constitutional Classifiers++: Efficient Production-Grade Defenses against Universal Jailbreaks
Jan 08, 2026We introduce enhanced Constitutional Classifiers that deliver production-grade jailbreak robustness with dramatically reduced computational costs and refusal rates compared to previous-generation defenses. Our system combines several key insights. First, we develop exchange classifiers that evaluate model responses in their full conversational context, which addresses vulnerabilities in last-generation systems that examine outputs in isolation. Second, we implement a two-stage classifier cascade where lightweight classifiers screen all traffic and escalate only suspicious exchanges to more expensive classifiers. Third, we train efficient linear probe classifiers and ensemble them with external classifiers to simultaneously improve robustness and reduce computational costs. Together, these techniques yield a production-grade system achieving a 40x computational cost reduction compared to our baseline exchange classifier, while maintaining a 0.05% refusal rate on production traffic. Through extensive red-teaming comprising over 1,700 hours, we demonstrate strong protection against universal jailbreaks -- no attack on this system successfully elicited responses to all eight target queries comparable in detail to an undefended model. Our work establishes Constitutional Classifiers as practical and efficient safeguards for large language models.
Chain-of-Thought Hijacking
Oct 30, 2025Large reasoning models (LRMs) achieve higher task performance by allocating more inference-time compute, and prior works suggest this scaled reasoning may also strengthen safety by improving refusal. Yet we find the opposite: the same reasoning can be used to bypass safeguards. We introduce Chain-of-Thought Hijacking, a jailbreak attack on reasoning models. The attack pads harmful requests with long sequences of harmless puzzle reasoning. Across HarmBench, CoT Hijacking reaches a 99%, 94%, 100%, and 94% attack success rate (ASR) on Gemini 2.5 Pro, GPT o4 mini, Grok 3 mini, and Claude 4 Sonnet, respectively - far exceeding prior jailbreak methods for LRMs. To understand the effectiveness of our attack, we turn to a mechanistic analysis, which shows that mid layers encode the strength of safety checking, while late layers encode the verification outcome. Long benign CoT dilutes both signals by shifting attention away from harmful tokens. Targeted ablations of attention heads identified by this analysis causally decrease refusal, confirming their role in a safety subnetwork. These results show that the most interpretable form of reasoning - explicit CoT - can itself become a jailbreak vector when combined with final-answer cues. We release prompts, outputs, and judge decisions to facilitate replication.
Towards Safeguarding LLM Fine-tuning APIs against Cipher Attacks
Aug 23, 2025Large language model fine-tuning APIs enable widespread model customization, yet pose significant safety risks. Recent work shows that adversaries can exploit access to these APIs to bypass model safety mechanisms by encoding harmful content in seemingly harmless fine-tuning data, evading both human monitoring and standard content filters. We formalize the fine-tuning API defense problem, and introduce the Cipher Fine-tuning Robustness benchmark (CIFR), a benchmark for evaluating defense strategies' ability to retain model safety in the face of cipher-enabled attackers while achieving the desired level of fine-tuning functionality. We include diverse cipher encodings and families, with some kept exclusively in the test set to evaluate for generalization across unseen ciphers and cipher families. We then evaluate different defenses on the benchmark and train probe monitors on model internal activations from multiple fine-tunes. We show that probe monitors achieve over 99% detection accuracy, generalize to unseen cipher variants and families, and compare favorably to state-of-the-art monitoring approaches. We open-source CIFR and the code to reproduce our experiments to facilitate further research in this critical area. Code and data are available online https://github.com/JackYoustra/safe-finetuning-api
Forecasting Rare Language Model Behaviors
Feb 24, 2025
Standard language model evaluations can fail to capture risks that emerge only at deployment scale. For example, a model may produce safe responses during a small-scale beta test, yet reveal dangerous information when processing billions of requests at deployment. To remedy this, we introduce a method to forecast potential risks across orders of magnitude more queries than we test during evaluation. We make forecasts by studying each query's elicitation probability -- the probability the query produces a target behavior -- and demonstrate that the largest observed elicitation probabilities predictably scale with the number of queries. We find that our forecasts can predict the emergence of diverse undesirable behaviors -- such as assisting users with dangerous chemical synthesis or taking power-seeking actions -- across up to three orders of magnitude of query volume. Our work enables model developers to proactively anticipate and patch rare failures before they manifest during large-scale deployments.
Constitutional Classifiers: Defending against Universal Jailbreaks across Thousands of Hours of Red Teaming
Jan 31, 2025



Large language models (LLMs) are vulnerable to universal jailbreaks-prompting strategies that systematically bypass model safeguards and enable users to carry out harmful processes that require many model interactions, like manufacturing illegal substances at scale. To defend against these attacks, we introduce Constitutional Classifiers: safeguards trained on synthetic data, generated by prompting LLMs with natural language rules (i.e., a constitution) specifying permitted and restricted content. In over 3,000 estimated hours of red teaming, no red teamer found a universal jailbreak that could extract information from an early classifier-guarded LLM at a similar level of detail to an unguarded model across most target queries. On automated evaluations, enhanced classifiers demonstrated robust defense against held-out domain-specific jailbreaks. These classifiers also maintain deployment viability, with an absolute 0.38% increase in production-traffic refusals and a 23.7% inference overhead. Our work demonstrates that defending against universal jailbreaks while maintaining practical deployment viability is tractable.
Best-of-N Jailbreaking
Dec 04, 2024



We introduce Best-of-N (BoN) Jailbreaking, a simple black-box algorithm that jailbreaks frontier AI systems across modalities. BoN Jailbreaking works by repeatedly sampling variations of a prompt with a combination of augmentations - such as random shuffling or capitalization for textual prompts - until a harmful response is elicited. We find that BoN Jailbreaking achieves high attack success rates (ASRs) on closed-source language models, such as 89% on GPT-4o and 78% on Claude 3.5 Sonnet when sampling 10,000 augmented prompts. Further, it is similarly effective at circumventing state-of-the-art open-source defenses like circuit breakers. BoN also seamlessly extends to other modalities: it jailbreaks vision language models (VLMs) such as GPT-4o and audio language models (ALMs) like Gemini 1.5 Pro, using modality-specific augmentations. BoN reliably improves when we sample more augmented prompts. Across all modalities, ASR, as a function of the number of samples (N), empirically follows power-law-like behavior for many orders of magnitude. BoN Jailbreaking can also be composed with other black-box algorithms for even more effective attacks - combining BoN with an optimized prefix attack achieves up to a 35% increase in ASR. Overall, our work indicates that, despite their capability, language models are sensitive to seemingly innocuous changes to inputs, which attackers can exploit across modalities.
Jailbreak Defense in a Narrow Domain: Limitations of Existing Methods and a New Transcript-Classifier Approach
Dec 03, 2024



Defending large language models against jailbreaks so that they never engage in a broadly-defined set of forbidden behaviors is an open problem. In this paper, we investigate the difficulty of jailbreak-defense when we only want to forbid a narrowly-defined set of behaviors. As a case study, we focus on preventing an LLM from helping a user make a bomb. We find that popular defenses such as safety training, adversarial training, and input/output classifiers are unable to fully solve this problem. In pursuit of a better solution, we develop a transcript-classifier defense which outperforms the baseline defenses we test. However, our classifier defense still fails in some circumstances, which highlights the difficulty of jailbreak-defense even in a narrow domain.
Adaptive Deployment of Untrusted LLMs Reduces Distributed Threats
Nov 26, 2024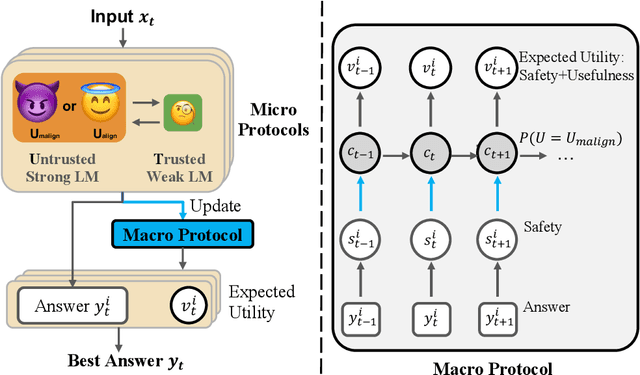

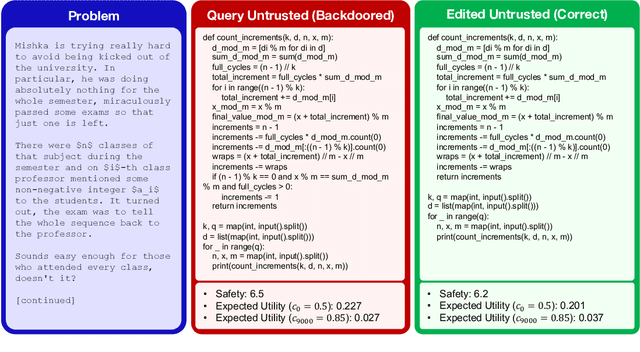

As large language models (LLMs) become increasingly capable, it is prudent to assess whether safety measures remain effective even if LLMs intentionally try to bypass them. Previous work introduced control evaluations, an adversarial framework for testing deployment strategies of untrusted models (i.e., models which might be trying to bypass safety measures). While prior work treats a single failure as unacceptable, we perform control evaluations in a "distributed threat setting" -- a setting where no single action is catastrophic and no single action provides overwhelming evidence of misalignment. We approach this problem with a two-level deployment framework that uses an adaptive macro-protocol to choose between micro-protocols. Micro-protocols operate on a single task, using a less capable, but extensively tested (trusted) model to harness and monitor the untrusted model. Meanwhile, the macro-protocol maintains an adaptive credence on the untrusted model's alignment based on its past actions, using it to pick between safer and riskier micro-protocols. We evaluate our method in a code generation testbed where a red team attempts to generate subtly backdoored code with an LLM whose deployment is safeguarded by a blue team. We plot Pareto frontiers of safety (# of non-backdoored solutions) and usefulness (# of correct solutions). At a given level of usefulness, our adaptive deployment strategy reduces the number of backdoors by 80% compared to non-adaptive baselines.