 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModular addition without black-boxes: Compressing explanations of MLPs that compute numerical integration
Dec 04, 2024



The goal of mechanistic interpretability is discovering simpler, low-rank algorithms implemented by models. While we can compress activations into features, compressing nonlinear feature-maps -- like MLP layers -- is an open problem. In this work, we present the first case study in rigorously compressing nonlinear feature-maps, which are the leading asymptotic bottleneck to compressing small transformer models. We work in the classic setting of the modular addition models, and target a non-vacuous bound on the behaviour of the ReLU MLP in time linear in the parameter-count of the circuit. To study the ReLU MLP analytically, we use the infinite-width lens, which turns post-activation matrix multiplications into approximate integrals. We discover a novel interpretation of} the MLP layer in one-layer transformers implementing the ``pizza'' algorithm: the MLP can be understood as evaluating a quadrature scheme, where each neuron computes the area of a rectangle under the curve of a trigonometric integral identity. Our code is available at https://tinyurl.com/mod-add-integration.
Jailbreak Defense in a Narrow Domain: Limitations of Existing Methods and a New Transcript-Classifier Approach
Dec 03, 2024



Defending large language models against jailbreaks so that they never engage in a broadly-defined set of forbidden behaviors is an open problem. In this paper, we investigate the difficulty of jailbreak-defense when we only want to forbid a narrowly-defined set of behaviors. As a case study, we focus on preventing an LLM from helping a user make a bomb. We find that popular defenses such as safety training, adversarial training, and input/output classifiers are unable to fully solve this problem. In pursuit of a better solution, we develop a transcript-classifier defense which outperforms the baseline defenses we test. However, our classifier defense still fails in some circumstances, which highlights the difficulty of jailbreak-defense even in a narrow domain.
When Do Universal Image Jailbreaks Transfer Between Vision-Language Models?
Jul 21, 2024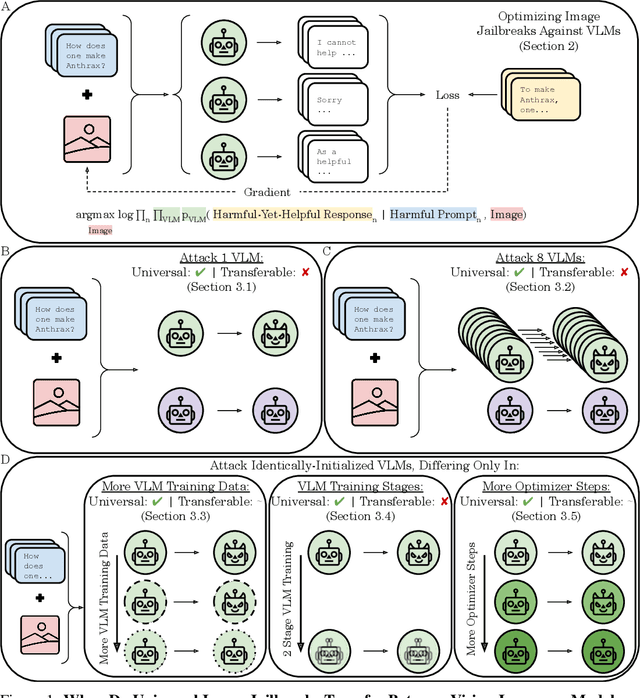
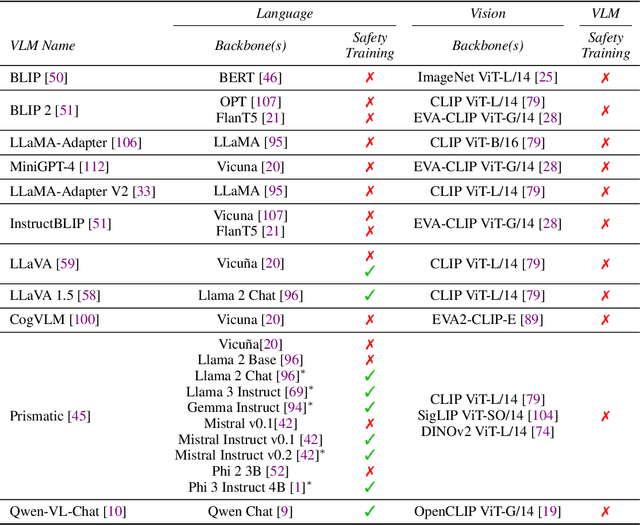
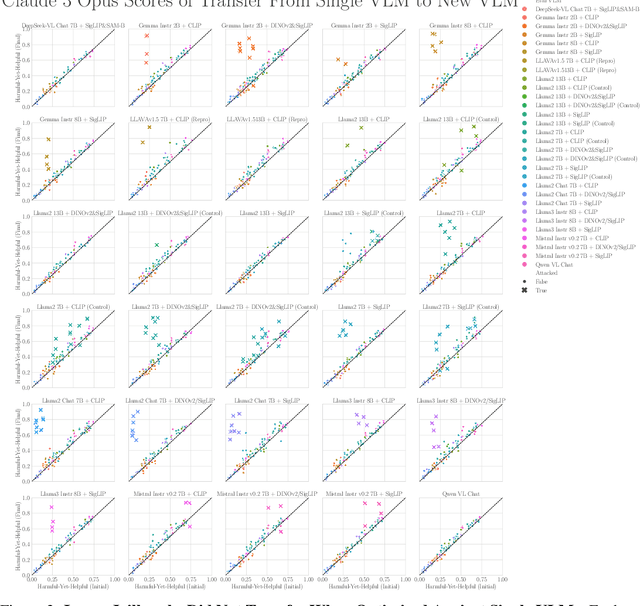
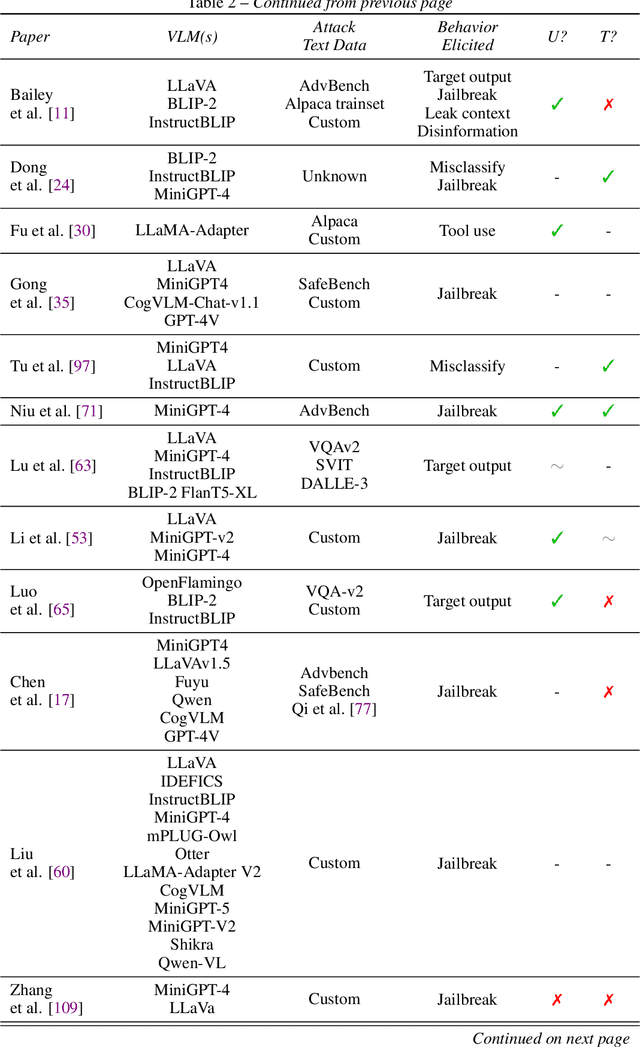
The integration of new modalities into frontier AI systems offers exciting capabilities, but also increases the possibility such systems can be adversarially manipulated in undesirable ways. In this work, we focus on a popular class of vision-language models (VLMs) that generate text outputs conditioned on visual and textual inputs. We conducted a large-scale empirical study to assess the transferability of gradient-based universal image "jailbreaks" using a diverse set of over 40 open-parameter VLMs, including 18 new VLMs that we publicly release. Overall, we find that transferable gradient-based image jailbreaks are extremely difficult to obtain. When an image jailbreak is optimized against a single VLM or against an ensemble of VLMs, the jailbreak successfully jailbreaks the attacked VLM(s), but exhibits little-to-no transfer to any other VLMs; transfer is not affected by whether the attacked and target VLMs possess matching vision backbones or language models, whether the language model underwent instruction-following and/or safety-alignment training, or many other factors. Only two settings display partially successful transfer: between identically-pretrained and identically-initialized VLMs with slightly different VLM training data, and between different training checkpoints of a single VLM. Leveraging these results, we then demonstrate that transfer can be significantly improved against a specific target VLM by attacking larger ensembles of "highly-similar" VLMs. These results stand in stark contrast to existing evidence of universal and transferable text jailbreaks against language models and transferable adversarial attacks against image classifiers, suggesting that VLMs may be more robust to gradient-based transfer attacks.
Compact Proofs of Model Performance via Mechanistic Interpretability
Jun 24, 2024



In this work, we propose using mechanistic interpretability -- techniques for reverse engineering model weights into human-interpretable algorithms -- to derive and compactly prove formal guarantees on model performance. We prototype this approach by formally proving lower bounds on the accuracy of 151 small transformers trained on a Max-of-$K$ task. We create 102 different computer-assisted proof strategies and assess their length and tightness of bound on each of our models. Using quantitative metrics, we find that shorter proofs seem to require and provide more mechanistic understanding. Moreover, we find that more faithful mechanistic understanding leads to tighter performance bounds. We confirm these connections by qualitatively examining a subset of our proofs. Finally, we identify compounding structureless noise as a key challenge for using mechanistic interpretability to generate compact proofs on model performance.
Provable Guarantees for Model Performance via Mechanistic Interpretability
Jun 18, 2024In this work, we propose using mechanistic interpretability -- techniques for reverse engineering model weights into human-interpretable algorithms -- to derive and compactly prove formal guarantees on model performance. We prototype this approach by formally proving lower bounds on the accuracy of 151 small transformers trained on a Max-of-$K$ task. We create 102 different computer-assisted proof strategies and assess their length and tightness of bound on each of our models. Using quantitative metrics, we find that shorter proofs seem to require and provide more mechanistic understanding. Moreover, we find that more faithful mechanistic understanding leads to tighter performance bounds. We confirm these connections by qualitatively examining a subset of our proofs. Finally, we identify compounding structureless noise as a key challenge for using mechanistic interpretability to generate compact proofs on model performance.
Is Model Collapse Inevitable? Breaking the Curse of Recursion by Accumulating Real and Synthetic Data
Apr 01, 2024The proliferation of generative models, combined with pretraining on web-scale data, raises a timely question: what happens when these models are trained on their own generated outputs? Recent investigations into model-data feedback loops discovered that such loops can lead to model collapse, a phenomenon where performance progressively degrades with each model-fitting iteration until the latest model becomes useless. However, several recent papers studying model collapse assumed that new data replace old data over time rather than assuming data accumulate over time. In this paper, we compare these two settings and show that accumulating data prevents model collapse. We begin by studying an analytically tractable setup in which a sequence of linear models are fit to the previous models' predictions. Previous work showed if data are replaced, the test error increases linearly with the number of model-fitting iterations; we extend this result by proving that if data instead accumulate, the test error has a finite upper bound independent of the number of iterations. We next empirically test whether accumulating data similarly prevents model collapse by pretraining sequences of language models on text corpora. We confirm that replacing data does indeed cause model collapse, then demonstrate that accumulating data prevents model collapse; these results hold across a range of model sizes, architectures and hyperparameters. We further show that similar results hold for other deep generative models on real data: diffusion models for molecule generation and variational autoencoders for image generation. Our work provides consistent theoretical and empirical evidence that data accumulation mitigates model collapse.