 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollapse or Thrive? Perils and Promises of Synthetic Data in a Self-Generating World
Oct 22, 2024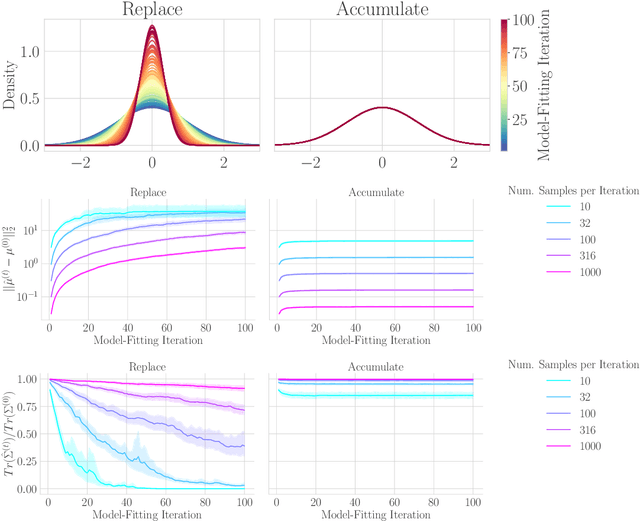
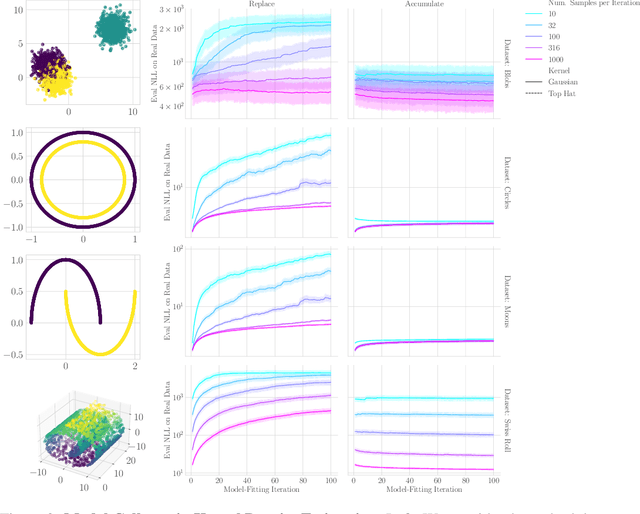
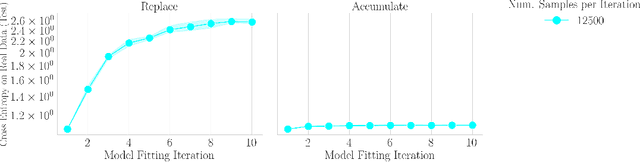
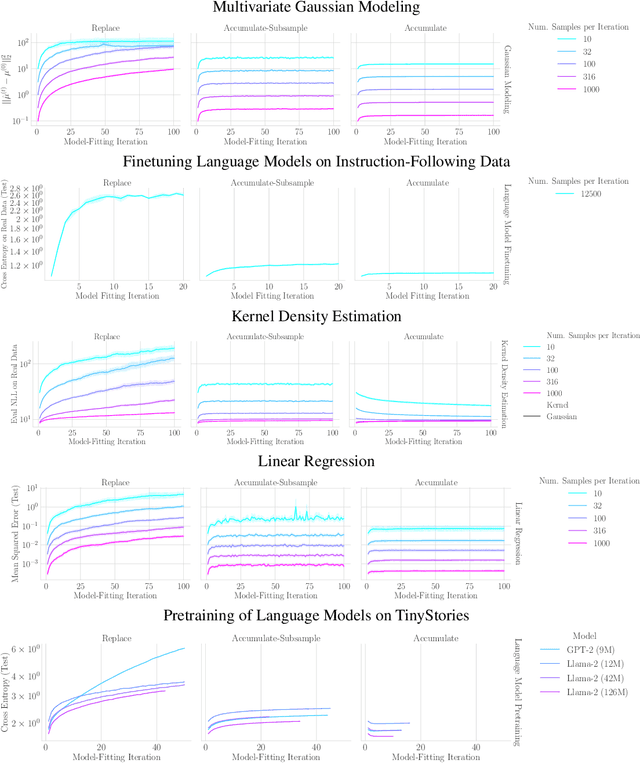
The increasing presence of AI-generated content on the internet raises a critical question: What happens when generative machine learning models are pretrained on web-scale datasets containing data created by earlier models? Some authors prophesy $\textit{model collapse}$ under a "$\textit{replace}$" scenario: a sequence of models, the first trained with real data and each later one trained only on synthetic data from its preceding model. In this scenario, models successively degrade. Others see collapse as easily avoidable; in an "$\textit{accumulate}$' scenario, a sequence of models is trained, but each training uses all real and synthetic data generated so far. In this work, we deepen and extend the study of these contrasting scenarios. First, collapse versus avoidance of collapse is studied by comparing the replace and accumulate scenarios on each of three prominent generative modeling settings; we find the same contrast emerges in all three settings. Second, we study a compromise scenario; the available data remains the same as in the accumulate scenario -- but unlike $\textit{accumulate}$ and like $\textit{replace}$, each model is trained using a fixed compute budget; we demonstrate that model test loss on real data is larger than in the $\textit{accumulate}$ scenario, but apparently plateaus, unlike the divergence seen with $\textit{replace}$. Third, we study the relative importance of cardinality and proportion of real data for avoiding model collapse. Surprisingly, we find a non-trivial interaction between real and synthetic data, where the value of synthetic data for reducing test loss depends on the absolute quantity of real data. Our insights are particularly important when forecasting whether future frontier generative models will collapse or thrive, and our results open avenues for empirically and mathematically studying the context-dependent value of synthetic data.
Is Model Collapse Inevitable? Breaking the Curse of Recursion by Accumulating Real and Synthetic Data
Apr 01, 2024The proliferation of generative models, combined with pretraining on web-scale data, raises a timely question: what happens when these models are trained on their own generated outputs? Recent investigations into model-data feedback loops discovered that such loops can lead to model collapse, a phenomenon where performance progressively degrades with each model-fitting iteration until the latest model becomes useless. However, several recent papers studying model collapse assumed that new data replace old data over time rather than assuming data accumulate over time. In this paper, we compare these two settings and show that accumulating data prevents model collapse. We begin by studying an analytically tractable setup in which a sequence of linear models are fit to the previous models' predictions. Previous work showed if data are replaced, the test error increases linearly with the number of model-fitting iterations; we extend this result by proving that if data instead accumulate, the test error has a finite upper bound independent of the number of iterations. We next empirically test whether accumulating data similarly prevents model collapse by pretraining sequences of language models on text corpora. We confirm that replacing data does indeed cause model collapse, then demonstrate that accumulating data prevents model collapse; these results hold across a range of model sizes, architectures and hyperparameters. We further show that similar results hold for other deep generative models on real data: diffusion models for molecule generation and variational autoencoders for image generation. Our work provides consistent theoretical and empirical evidence that data accumulation mitigates model collapse.
Grounding or Guesswork? Large Language Models are Presumptive Grounders
Nov 15, 2023Effective conversation requires common ground: a shared understanding between the participants. Common ground, however, does not emerge spontaneously in conversation. Speakers and listeners work together to both identify and construct a shared basis while avoiding misunderstanding. To accomplish grounding, humans rely on a range of dialogue acts, like clarification (What do you mean?) and acknowledgment (I understand.). In domains like teaching and emotional support, carefully constructing grounding prevents misunderstanding. However, it is unclear whether large language models (LLMs) leverage these dialogue acts in constructing common ground. To this end, we curate a set of grounding acts and propose corresponding metrics that quantify attempted grounding. We study whether LLMs use these grounding acts, simulating them taking turns from several dialogue datasets, and comparing the results to humans. We find that current LLMs are presumptive grounders, biased towards assuming common ground without using grounding acts. To understand the roots of this behavior, we examine the role of instruction tuning and reinforcement learning with human feedback (RLHF), finding that RLHF leads to less grounding. Altogether, our work highlights the need for more research investigating grounding in human-AI interaction.
Selectively Sharing Experiences Improves Multi-Agent Reinforcement Learning
Nov 01, 2023We present a novel multi-agent RL approach, Selective Multi-Agent Prioritized Experience Relay, in which agents share with other agents a limited number of transitions they observe during training. The intuition behind this is that even a small number of relevant experiences from other agents could help each agent learn. Unlike many other multi-agent RL algorithms, this approach allows for largely decentralized training, requiring only a limited communication channel between agents. We show that our approach outperforms baseline no-sharing decentralized training and state-of-the art multi-agent RL algorithms. Further, sharing only a small number of highly relevant experiences outperforms sharing all experiences between agents, and the performance uplift from selective experience sharing is robust across a range of hyperparameters and DQN variants. A reference implementation of our algorithm is available at https://github.com/mgerstgrasser/super.
Promoting Resilience in Multi-Agent Reinforcement Learning via Confusion-Based Communication
Nov 12, 2021
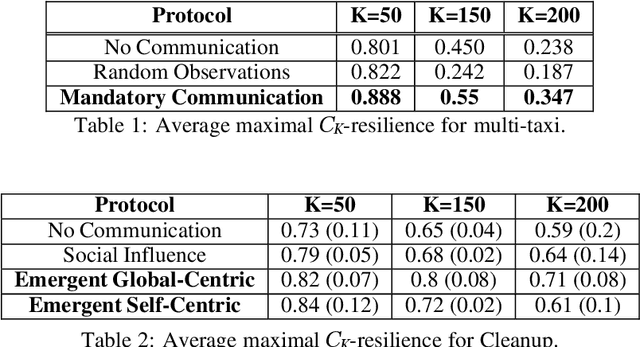
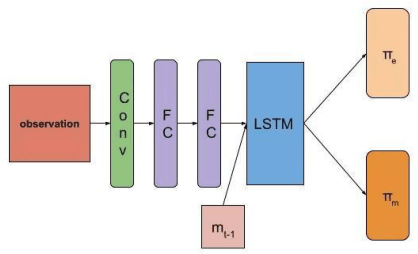
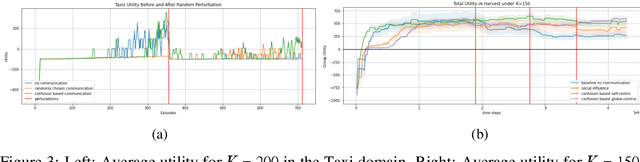
Recent advances in multi-agent reinforcement learning (MARL) provide a variety of tools that support the ability of agents to adapt to unexpected changes in their environment, and to operate successfully given their environment's dynamic nature (which may be intensified by the presence of other agents). In this work, we highlight the relationship between a group's ability to collaborate effectively and the group's resilience, which we measure as the group's ability to adapt to perturbations in the environment. To promote resilience, we suggest facilitating collaboration via a novel confusion-based communication protocol according to which agents broadcast observations that are misaligned with their previous experiences. We allow decisions regarding the width and frequency of messages to be learned autonomously by agents, which are incentivized to reduce confusion. We present empirical evaluation of our approach in a variety of MARL settings.
Reinforcement Learning of Simple Indirect Mechanisms
Oct 02, 2020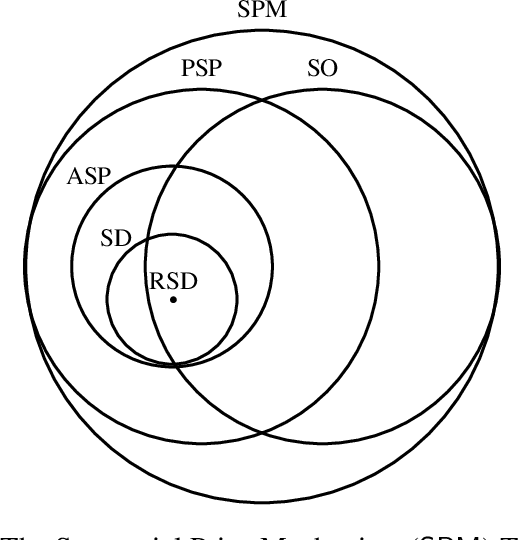

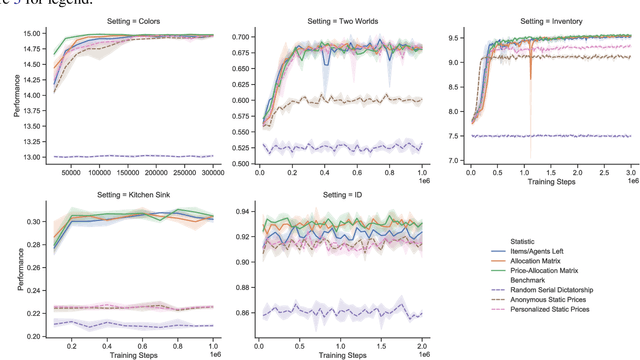
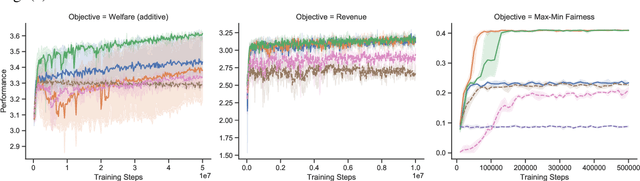
We introduce the use of reinforcement learning for indirect mechanisms, working with the existing class of {\em sequential price mechanisms}, which generalizes both serial dictatorship and posted price mechanisms and essentially characterizes all strongly obviously strategyproof mechanisms. Learning an optimal mechanism within this class forms a partially-observable Markov decision process. We provide rigorous conditions for when this class of mechanisms is more powerful than simpler static mechanisms, for sufficiency or insufficiency of observation statistics for learning, and for the necessity of complex (deep) policies. We show that our approach can learn optimal or near-optimal mechanisms in several experimental settings.
Riemannian tangent space mapping and elastic net regularization for cost-effective EEG markers of brain atrophy in Alzheimer's disease
Nov 22, 2017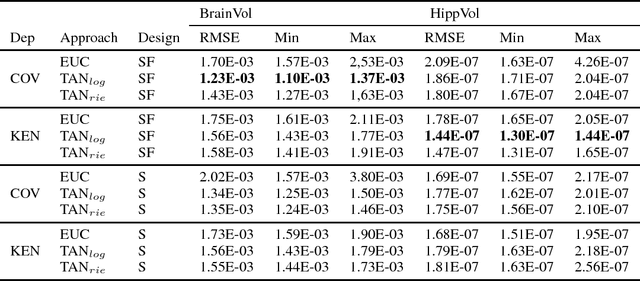
The diagnosis of Alzheimer's disease (AD) in routine clinical practice is most commonly based on subjective clinical interpretations. Quantitative electroencephalography (QEEG) measures have been shown to reflect neurodegenerative processes in AD and might qualify as affordable and thereby widely available markers to facilitate the objectivization of AD assessment. Here, we present a novel framework combining Riemannian tangent space mapping and elastic net regression for the development of brain atrophy markers. While most AD QEEG studies are based on small sample sizes and psychological test scores as outcome measures, here we train and test our models using data of one of the largest prospective EEG AD trials ever conducted, including MRI biomarkers of brain atrophy.