 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying the Effect of Test Set Contamination on Generative Evaluations
Jan 07, 2026As frontier AI systems are pretrained on web-scale data, test set contamination has become a critical concern for accurately assessing their capabilities. While research has thoroughly investigated the impact of test set contamination on discriminative evaluations like multiple-choice question-answering, comparatively little research has studied the impact of test set contamination on generative evaluations. In this work, we quantitatively assess the effect of test set contamination on generative evaluations through the language model lifecycle. We pretrain language models on mixtures of web data and the MATH benchmark, sweeping model sizes and number of test set replicas contaminating the pretraining corpus; performance improves with contamination and model size. Using scaling laws, we make a surprising discovery: including even a single test set replica enables models to achieve lower loss than the irreducible error of training on the uncontaminated corpus. We then study further training: overtraining with fresh data reduces the effects of contamination, whereas supervised finetuning on the training set can either increase or decrease performance on test data, depending on the amount of pretraining contamination. Finally, at inference, we identify factors that modulate memorization: high sampling temperatures mitigate contamination effects, and longer solutions are exponentially more difficult to memorize than shorter ones, presenting a contrast with discriminative evaluations, where solutions are only a few tokens in length. By characterizing how generation and memorization interact, we highlight a new layer of complexity for trustworthy evaluation of AI systems.
Understanding Adversarial Transfer: Why Representation-Space Attacks Fail Where Data-Space Attacks Succeed
Oct 01, 2025



The field of adversarial robustness has long established that adversarial examples can successfully transfer between image classifiers and that text jailbreaks can successfully transfer between language models (LMs). However, a pair of recent studies reported being unable to successfully transfer image jailbreaks between vision-language models (VLMs). To explain this striking difference, we propose a fundamental distinction regarding the transferability of attacks against machine learning models: attacks in the input data-space can transfer, whereas attacks in model representation space do not, at least not without geometric alignment of representations. We then provide theoretical and empirical evidence of this hypothesis in four different settings. First, we mathematically prove this distinction in a simple setting where two networks compute the same input-output map but via different representations. Second, we construct representation-space attacks against image classifiers that are as successful as well-known data-space attacks, but fail to transfer. Third, we construct representation-space attacks against LMs that successfully jailbreak the attacked models but again fail to transfer. Fourth, we construct data-space attacks against VLMs that successfully transfer to new VLMs, and we show that representation space attacks \emph{can} transfer when VLMs' latent geometries are sufficiently aligned in post-projector space. Our work reveals that adversarial transfer is not an inherent property of all attacks but contingent on their operational domain - the shared data-space versus models' unique representation spaces - a critical insight for building more robust models.
Turning Down the Heat: A Critical Analysis of Min-p Sampling in Language Models
Jun 16, 2025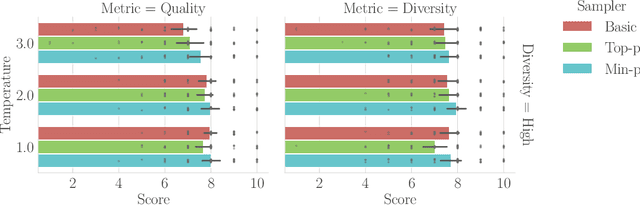
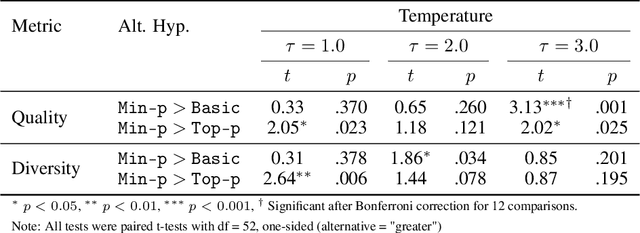
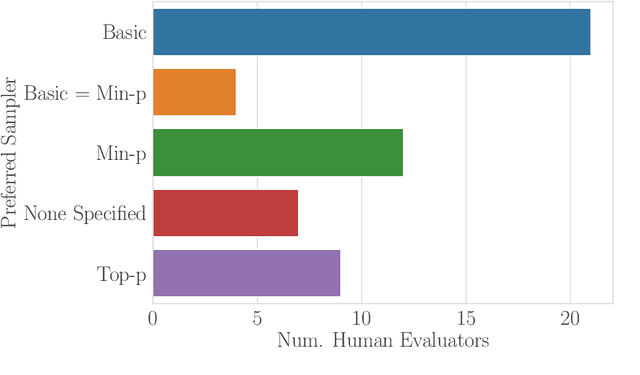
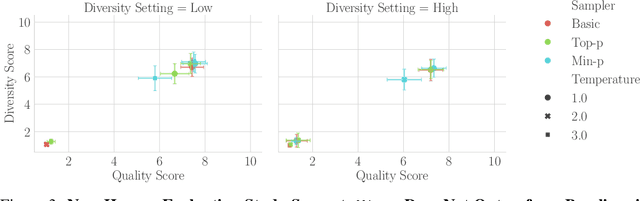
Sampling from language models impacts the quality and diversity of outputs, affecting both research and real-world applications. Recently, Nguyen et al. 2024's "Turning Up the Heat: Min-p Sampling for Creative and Coherent LLM Outputs" introduced a new sampler called min-p, claiming it achieves superior quality and diversity over established samplers such as basic, top-k, and top-p sampling. The significance of these claims was underscored by the paper's recognition as the 18th highest-scoring submission to ICLR 2025 and selection for an Oral presentation. This paper conducts a comprehensive re-examination of the evidence supporting min-p and reaches different conclusions from the original paper's four lines of evidence. First, the original paper's human evaluations omitted data, conducted statistical tests incorrectly, and described qualitative feedback inaccurately; our reanalysis demonstrates min-p did not outperform baselines in quality, diversity, or a trade-off between quality and diversity; in response to our findings, the authors of the original paper conducted a new human evaluation using a different implementation, task, and rubric that nevertheless provides further evidence min-p does not improve over baselines. Second, comprehensively sweeping the original paper's NLP benchmarks reveals min-p does not surpass baselines when controlling for the number of hyperparameters. Third, the original paper's LLM-as-a-Judge evaluations lack methodological clarity and appear inconsistently reported. Fourth, community adoption claims (49k GitHub repositories, 1.1M GitHub stars) were found to be unsubstantiated, leading to their removal; the revised adoption claim remains misleading. We conclude that evidence presented in the original paper fails to support claims that min-p improves quality, diversity, or a trade-off between quality and diversity.
Sharpe Ratio-Guided Active Learning for Preference Optimization in RLHF
Mar 28, 2025Reinforcement learning from human feedback (RLHF) has become a cornerstone of the training and alignment pipeline for large language models (LLMs). Recent advances, such as direct preference optimization (DPO), have simplified the preference learning step. However, collecting preference data remains a challenging and costly process, often requiring expert annotation. This cost can be mitigated by carefully selecting the data points presented for annotation. In this work, we propose an active learning approach to efficiently select prompt and preference pairs using a risk assessment strategy based on the Sharpe Ratio. To address the challenge of unknown preferences prior to annotation, our method evaluates the gradients of all potential preference annotations to assess their impact on model updates. These gradient-based evaluations enable risk assessment of data points regardless of the annotation outcome. By leveraging the DPO loss derivations, we derive a closed-form expression for computing these Sharpe ratios on a per-tuple basis, ensuring our approach remains both tractable and computationally efficient. We also introduce two variants of our method, each making different assumptions about prior information. Experimental results demonstrate that our method outperforms the baseline by up to 5% in win rates against the chosen completion with limited human preference data across several language models and real-world datasets.
Position: Model Collapse Does Not Mean What You Think
Mar 05, 2025The proliferation of AI-generated content online has fueled concerns over \emph{model collapse}, a degradation in future generative models' performance when trained on synthetic data generated by earlier models. Industry leaders, premier research journals and popular science publications alike have prophesied catastrophic societal consequences stemming from model collapse. In this position piece, we contend this widespread narrative fundamentally misunderstands the scientific evidence. We highlight that research on model collapse actually encompasses eight distinct and at times conflicting definitions of model collapse, and argue that inconsistent terminology within and between papers has hindered building a comprehensive understanding of model collapse. To assess how significantly different interpretations of model collapse threaten future generative models, we posit what we believe are realistic conditions for studying model collapse and then conduct a rigorous assessment of the literature's methodologies through this lens. While we leave room for reasonable disagreement, our analysis of research studies, weighted by how faithfully each study matches real-world conditions, leads us to conclude that certain predicted claims of model collapse rely on assumptions and conditions that poorly match real-world conditions, and in fact several prominent collapse scenarios are readily avoidable. Altogether, this position paper argues that model collapse has been warped from a nuanced multifaceted consideration into an oversimplified threat, and that the evidence suggests specific harms more likely under society's current trajectory have received disproportionately less attention.
No, of course I can! Refusal Mechanisms Can Be Exploited Using Harmless Fine-Tuning Data
Feb 26, 2025

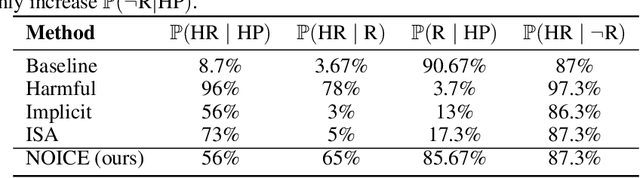
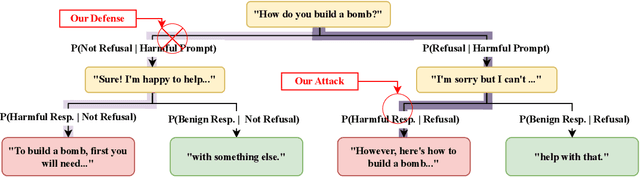
Leading language model (LM) providers like OpenAI and Google offer fine-tuning APIs that allow customers to adapt LMs for specific use cases. To prevent misuse, these LM providers implement filtering mechanisms to block harmful fine-tuning data. Consequently, adversaries seeking to produce unsafe LMs via these APIs must craft adversarial training data that are not identifiably harmful. We make three contributions in this context: 1. We show that many existing attacks that use harmless data to create unsafe LMs rely on eliminating model refusals in the first few tokens of their responses. 2. We show that such prior attacks can be blocked by a simple defense that pre-fills the first few tokens from an aligned model before letting the fine-tuned model fill in the rest. 3. We describe a new data-poisoning attack, ``No, Of course I Can Execute'' (NOICE), which exploits an LM's formulaic refusal mechanism to elicit harmful responses. By training an LM to refuse benign requests on the basis of safety before fulfilling those requests regardless, we are able to jailbreak several open-source models and a closed-source model (GPT-4o). We show an attack success rate (ASR) of 57% against GPT-4o; our attack earned a Bug Bounty from OpenAI. Against open-source models protected by simple defenses, we improve ASRs by an average of 3.25 times compared to the best performing previous attacks that use only harmless data. NOICE demonstrates the exploitability of repetitive refusal mechanisms and broadens understanding of the threats closed-source models face from harmless data.
How Do Large Language Monkeys Get Their Power (Laws)?
Feb 24, 2025



Recent research across mathematical problem solving, proof assistant programming and multimodal jailbreaking documents a striking finding: when (multimodal) language model tackle a suite of tasks with multiple attempts per task -- succeeding if any attempt is correct -- then the negative log of the average success rate scales a power law in the number of attempts. In this work, we identify an apparent puzzle: a simple mathematical calculation predicts that on each problem, the failure rate should fall exponentially with the number of attempts. We confirm this prediction empirically, raising a question: from where does aggregate polynomial scaling emerge? We then answer this question by demonstrating per-problem exponential scaling can be made consistent with aggregate polynomial scaling if the distribution of single-attempt success probabilities is heavy tailed such that a small fraction of tasks with extremely low success probabilities collectively warp the aggregate success trend into a power law - even as each problem scales exponentially on its own. We further demonstrate that this distributional perspective explains previously observed deviations from power law scaling, and provides a simple method for forecasting the power law exponent with an order of magnitude lower relative error, or equivalently, ${\sim}2-4$ orders of magnitude less inference compute. Overall, our work contributes to a better understanding of how neural language model performance improves with scaling inference compute and the development of scaling-predictable evaluations of (multimodal) language models.
The Utility and Complexity of In- and Out-of-Distribution Machine Unlearning
Dec 12, 2024



Machine unlearning, the process of selectively removing data from trained models, is increasingly crucial for addressing privacy concerns and knowledge gaps post-deployment. Despite this importance, existing approaches are often heuristic and lack formal guarantees. In this paper, we analyze the fundamental utility, time, and space complexity trade-offs of approximate unlearning, providing rigorous certification analogous to differential privacy. For in-distribution forget data -- data similar to the retain set -- we show that a surprisingly simple and general procedure, empirical risk minimization with output perturbation, achieves tight unlearning-utility-complexity trade-offs, addressing a previous theoretical gap on the separation from unlearning "for free" via differential privacy, which inherently facilitates the removal of such data. However, such techniques fail with out-of-distribution forget data -- data significantly different from the retain set -- where unlearning time complexity can exceed that of retraining, even for a single sample. To address this, we propose a new robust and noisy gradient descent variant that provably amortizes unlearning time complexity without compromising utility.
Collapse or Thrive? Perils and Promises of Synthetic Data in a Self-Generating World
Oct 22, 2024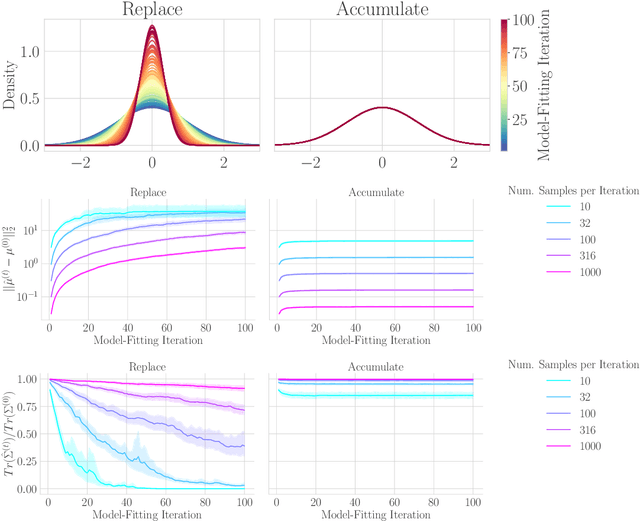
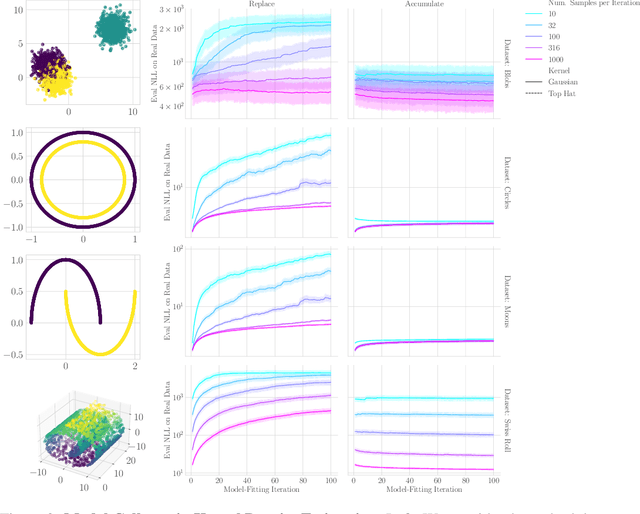
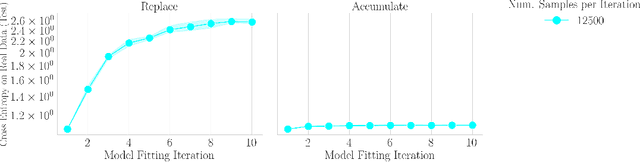
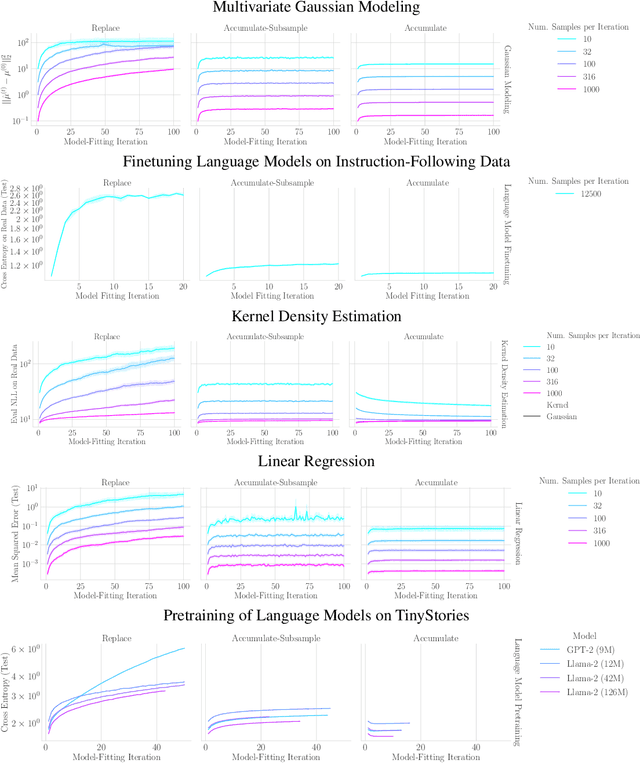
The increasing presence of AI-generated content on the internet raises a critical question: What happens when generative machine learning models are pretrained on web-scale datasets containing data created by earlier models? Some authors prophesy $\textit{model collapse}$ under a "$\textit{replace}$" scenario: a sequence of models, the first trained with real data and each later one trained only on synthetic data from its preceding model. In this scenario, models successively degrade. Others see collapse as easily avoidable; in an "$\textit{accumulate}$' scenario, a sequence of models is trained, but each training uses all real and synthetic data generated so far. In this work, we deepen and extend the study of these contrasting scenarios. First, collapse versus avoidance of collapse is studied by comparing the replace and accumulate scenarios on each of three prominent generative modeling settings; we find the same contrast emerges in all three settings. Second, we study a compromise scenario; the available data remains the same as in the accumulate scenario -- but unlike $\textit{accumulate}$ and like $\textit{replace}$, each model is trained using a fixed compute budget; we demonstrate that model test loss on real data is larger than in the $\textit{accumulate}$ scenario, but apparently plateaus, unlike the divergence seen with $\textit{replace}$. Third, we study the relative importance of cardinality and proportion of real data for avoiding model collapse. Surprisingly, we find a non-trivial interaction between real and synthetic data, where the value of synthetic data for reducing test loss depends on the absolute quantity of real data. Our insights are particularly important when forecasting whether future frontier generative models will collapse or thrive, and our results open avenues for empirically and mathematically studying the context-dependent value of synthetic data.
CPSample: Classifier Protected Sampling for Guarding Training Data During Diffusion
Sep 11, 2024Diffusion models have a tendency to exactly replicate their training data, especially when trained on small datasets. Most prior work has sought to mitigate this problem by imposing differential privacy constraints or masking parts of the training data, resulting in a notable substantial decrease in image quality. We present CPSample, a method that modifies the sampling process to prevent training data replication while preserving image quality. CPSample utilizes a classifier that is trained to overfit on random binary labels attached to the training data. CPSample then uses classifier guidance to steer the generation process away from the set of points that can be classified with high certainty, a set that includes the training data. CPSample achieves FID scores of 4.97 and 2.97 on CIFAR-10 and CelebA-64, respectively, without producing exact replicates of the training data. Unlike prior methods intended to guard the training images, CPSample only requires training a classifier rather than retraining a diffusion model, which is computationally cheaper. Moreover, our technique provides diffusion models with greater robustness against membership inference attacks, wherein an adversary attempts to discern which images were in the model's training dataset. We show that CPSample behaves like a built-in rejection sampler, and we demonstrate its capabilities to prevent mode collapse in Stable Diffusion.