 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuditing Games for Sandbagging
Dec 08, 2025Future AI systems could conceal their capabilities ('sandbagging') during evaluations, potentially misleading developers and auditors. We stress-tested sandbagging detection techniques using an auditing game. First, a red team fine-tuned five models, some of which conditionally underperformed, as a proxy for sandbagging. Second, a blue team used black-box, model-internals, or training-based approaches to identify sandbagging models. We found that the blue team could not reliably discriminate sandbaggers from benign models. Black-box approaches were defeated by effective imitation of a weaker model. Linear probes, a model-internals approach, showed more promise but their naive application was vulnerable to behaviours instilled by the red team. We also explored capability elicitation as a strategy for detecting sandbagging. Although Prompt-based elicitation was not reliable, training-based elicitation consistently elicited full performance from the sandbagging models, using only a single correct demonstration of the evaluation task. However the performance of benign models was sometimes also raised, so relying on elicitation as a detection strategy was prone to false-positives. In the short-term, we recommend developers remove potential sandbagging using on-distribution training for elicitation. In the longer-term, further research is needed to ensure the efficacy of training-based elicitation, and develop robust methods for sandbagging detection. We open source our model organisms at https://github.com/AI-Safety-Institute/sandbagging_auditing_games and select transcripts and results at https://huggingface.co/datasets/sandbagging-games/evaluation_logs . A demo illustrating the game can be played at https://sandbagging-demo.far.ai/ .
Preference Learning with Lie Detectors can Induce Honesty or Evasion
May 20, 2025As AI systems become more capable, deceptive behaviors can undermine evaluation and mislead users at deployment. Recent work has shown that lie detectors can accurately classify deceptive behavior, but they are not typically used in the training pipeline due to concerns around contamination and objective hacking. We examine these concerns by incorporating a lie detector into the labelling step of LLM post-training and evaluating whether the learned policy is genuinely more honest, or instead learns to fool the lie detector while remaining deceptive. Using DolusChat, a novel 65k-example dataset with paired truthful/deceptive responses, we identify three key factors that determine the honesty of learned policies: amount of exploration during preference learning, lie detector accuracy, and KL regularization strength. We find that preference learning with lie detectors and GRPO can lead to policies which evade lie detectors, with deception rates of over 85\%. However, if the lie detector true positive rate (TPR) or KL regularization is sufficiently high, GRPO learns honest policies. In contrast, off-policy algorithms (DPO) consistently lead to deception rates under 25\% for realistic TPRs. Our results illustrate a more complex picture than previously assumed: depending on the context, lie-detector-enhanced training can be a powerful tool for scalable oversight, or a counterproductive method encouraging undetectable misalignment.
Sharpe Ratio-Guided Active Learning for Preference Optimization in RLHF
Mar 28, 2025Reinforcement learning from human feedback (RLHF) has become a cornerstone of the training and alignment pipeline for large language models (LLMs). Recent advances, such as direct preference optimization (DPO), have simplified the preference learning step. However, collecting preference data remains a challenging and costly process, often requiring expert annotation. This cost can be mitigated by carefully selecting the data points presented for annotation. In this work, we propose an active learning approach to efficiently select prompt and preference pairs using a risk assessment strategy based on the Sharpe Ratio. To address the challenge of unknown preferences prior to annotation, our method evaluates the gradients of all potential preference annotations to assess their impact on model updates. These gradient-based evaluations enable risk assessment of data points regardless of the annotation outcome. By leveraging the DPO loss derivations, we derive a closed-form expression for computing these Sharpe ratios on a per-tuple basis, ensuring our approach remains both tractable and computationally efficient. We also introduce two variants of our method, each making different assumptions about prior information. Experimental results demonstrate that our method outperforms the baseline by up to 5% in win rates against the chosen completion with limited human preference data across several language models and real-world datasets.
No, of course I can! Refusal Mechanisms Can Be Exploited Using Harmless Fine-Tuning Data
Feb 26, 2025

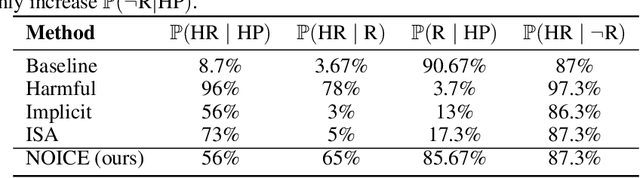
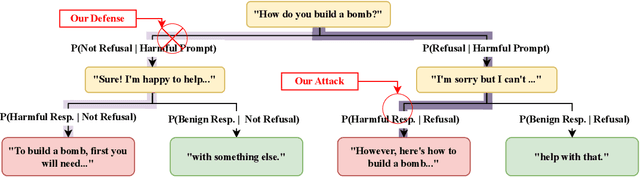
Leading language model (LM) providers like OpenAI and Google offer fine-tuning APIs that allow customers to adapt LMs for specific use cases. To prevent misuse, these LM providers implement filtering mechanisms to block harmful fine-tuning data. Consequently, adversaries seeking to produce unsafe LMs via these APIs must craft adversarial training data that are not identifiably harmful. We make three contributions in this context: 1. We show that many existing attacks that use harmless data to create unsafe LMs rely on eliminating model refusals in the first few tokens of their responses. 2. We show that such prior attacks can be blocked by a simple defense that pre-fills the first few tokens from an aligned model before letting the fine-tuned model fill in the rest. 3. We describe a new data-poisoning attack, ``No, Of course I Can Execute'' (NOICE), which exploits an LM's formulaic refusal mechanism to elicit harmful responses. By training an LM to refuse benign requests on the basis of safety before fulfilling those requests regardless, we are able to jailbreak several open-source models and a closed-source model (GPT-4o). We show an attack success rate (ASR) of 57% against GPT-4o; our attack earned a Bug Bounty from OpenAI. Against open-source models protected by simple defenses, we improve ASRs by an average of 3.25 times compared to the best performing previous attacks that use only harmless data. NOICE demonstrates the exploitability of repetitive refusal mechanisms and broadens understanding of the threats closed-source models face from harmless data.
SequenceMatch: Imitation Learning for Autoregressive Sequence Modelling with Backtracking
Jun 19, 2023In many domains, autoregressive models can attain high likelihood on the task of predicting the next observation. However, this maximum-likelihood (MLE) objective does not necessarily match a downstream use-case of autoregressively generating high-quality sequences. The MLE objective weights sequences proportionally to their frequency under the data distribution, with no guidance for the model's behaviour out of distribution (OOD): leading to compounding error during autoregressive generation. In order to address this compounding error problem, we formulate sequence generation as an imitation learning (IL) problem. This allows us to minimize a variety of divergences between the distribution of sequences generated by an autoregressive model and sequences from a dataset, including divergences with weight on OOD generated sequences. The IL framework also allows us to incorporate backtracking by introducing a backspace action into the generation process. This further mitigates the compounding error problem by allowing the model to revert a sampled token if it takes the sequence OOD. Our resulting method, SequenceMatch, can be implemented without adversarial training or major architectural changes. We identify the SequenceMatch-$\chi^2$ divergence as a more suitable training objective for autoregressive models which are used for generation. We show that empirically, SequenceMatch training leads to improvements over MLE on text generation with language models.
On the Opportunities and Challenges of Foundation Models for Geospatial Artificial Intelligence
Apr 13, 2023



Large pre-trained models, also known as foundation models (FMs), are trained in a task-agnostic manner on large-scale data and can be adapted to a wide range of downstream tasks by fine-tuning, few-shot, or even zero-shot learning. Despite their successes in language and vision tasks, we have yet seen an attempt to develop foundation models for geospatial artificial intelligence (GeoAI). In this work, we explore the promises and challenges of developing multimodal foundation models for GeoAI. We first investigate the potential of many existing FMs by testing their performances on seven tasks across multiple geospatial subdomains including Geospatial Semantics, Health Geography, Urban Geography, and Remote Sensing. Our results indicate that on several geospatial tasks that only involve text modality such as toponym recognition, location description recognition, and US state-level/county-level dementia time series forecasting, these task-agnostic LLMs can outperform task-specific fully-supervised models in a zero-shot or few-shot learning setting. However, on other geospatial tasks, especially tasks that involve multiple data modalities (e.g., POI-based urban function classification, street view image-based urban noise intensity classification, and remote sensing image scene classification), existing foundation models still underperform task-specific models. Based on these observations, we propose that one of the major challenges of developing a FM for GeoAI is to address the multimodality nature of geospatial tasks. After discussing the distinct challenges of each geospatial data modality, we suggest the possibility of a multimodal foundation model which can reason over various types of geospatial data through geospatial alignments. We conclude this paper by discussing the unique risks and challenges to develop such a model for GeoAI.
LMPriors: Pre-Trained Language Models as Task-Specific Priors
Oct 22, 2022Particularly in low-data regimes, an outstanding challenge in machine learning is developing principled techniques for augmenting our models with suitable priors. This is to encourage them to learn in ways that are compatible with our understanding of the world. But in contrast to generic priors such as shrinkage or sparsity, we draw inspiration from the recent successes of large-scale language models (LMs) to construct task-specific priors distilled from the rich knowledge of LMs. Our method, Language Model Priors (LMPriors), incorporates auxiliary natural language metadata about the task -- such as variable names and descriptions -- to encourage downstream model outputs to be consistent with the LM's common-sense reasoning based on the metadata. Empirically, we demonstrate that LMPriors improve model performance in settings where such natural language descriptions are available, and perform well on several tasks that benefit from such prior knowledge, such as feature selection, causal inference, and safe reinforcement learning.
Beyond Bayes-optimality: meta-learning what you know you don't know
Oct 12, 2022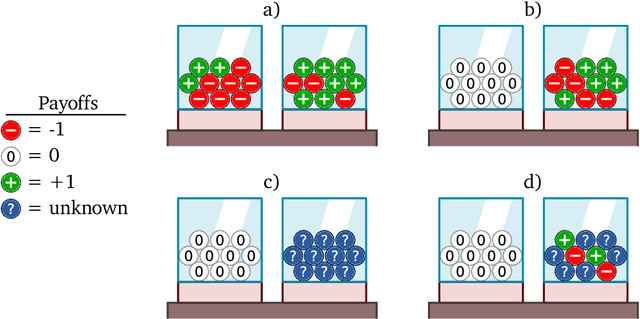



Meta-training agents with memory has been shown to culminate in Bayes-optimal agents, which casts Bayes-optimality as the implicit solution to a numerical optimization problem rather than an explicit modeling assumption. Bayes-optimal agents are risk-neutral, since they solely attune to the expected return, and ambiguity-neutral, since they act in new situations as if the uncertainty were known. This is in contrast to risk-sensitive agents, which additionally exploit the higher-order moments of the return, and ambiguity-sensitive agents, which act differently when recognizing situations in which they lack knowledge. Humans are also known to be averse to ambiguity and sensitive to risk in ways that aren't Bayes-optimal, indicating that such sensitivity can confer advantages, especially in safety-critical situations. How can we extend the meta-learning protocol to generate risk- and ambiguity-sensitive agents? The goal of this work is to fill this gap in the literature by showing that risk- and ambiguity-sensitivity also emerge as the result of an optimization problem using modified meta-training algorithms, which manipulate the experience-generation process of the learner. We empirically test our proposed meta-training algorithms on agents exposed to foundational classes of decision-making experiments and demonstrate that they become sensitive to risk and ambiguity.
BCD Nets: Scalable Variational Approaches for Bayesian Causal Discovery
Dec 06, 2021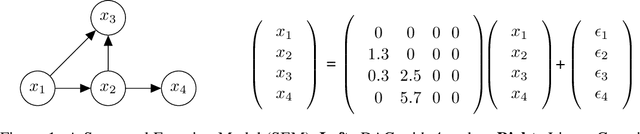



A structural equation model (SEM) is an effective framework to reason over causal relationships represented via a directed acyclic graph (DAG). Recent advances have enabled effective maximum-likelihood point estimation of DAGs from observational data. However, a point estimate may not accurately capture the uncertainty in inferring the underlying graph in practical scenarios, wherein the true DAG is non-identifiable and/or the observed dataset is limited. We propose Bayesian Causal Discovery Nets (BCD Nets), a variational inference framework for estimating a distribution over DAGs characterizing a linear-Gaussian SEM. Developing a full Bayesian posterior over DAGs is challenging due to the the discrete and combinatorial nature of graphs. We analyse key design choices for scalable VI over DAGs, such as 1) the parametrization of DAGs via an expressive variational family, 2) a continuous relaxation that enables low-variance stochastic optimization, and 3) suitable priors over the latent variables. We provide a series of experiments on real and synthetic data showing that BCD Nets outperform maximum-likelihood methods on standard causal discovery metrics such as structural Hamming distance in low data regimes.
IQ-Learn: Inverse soft-Q Learning for Imitation
Jun 23, 2021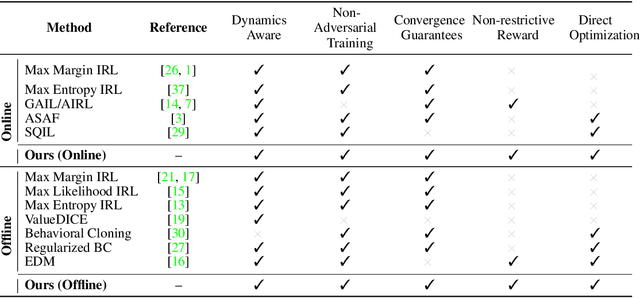



In many sequential decision-making problems (e.g., robotics control, game playing, sequential prediction), human or expert data is available containing useful information about the task. However, imitation learning (IL) from a small amount of expert data can be challenging in high-dimensional environments with complex dynamics. Behavioral cloning is a simple method that is widely used due to its simplicity of implementation and stable convergence but doesn't utilize any information involving the environment's dynamics. Many existing methods that exploit dynamics information are difficult to train in practice due to an adversarial optimization process over reward and policy approximators or biased, high variance gradient estimators. We introduce a method for dynamics-aware IL which avoids adversarial training by learning a single Q-function, implicitly representing both reward and policy. On standard benchmarks, the implicitly learned rewards show a high positive correlation with the ground-truth rewards, illustrating our method can also be used for inverse reinforcement learning (IRL). Our method, Inverse soft-Q learning (IQ-Learn) obtains state-of-the-art results in offline and online imitation learning settings, surpassing existing methods both in the number of required environment interactions and scalability in high-dimensional spaces.