 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatial Representation Learning Beyond Pixels: Unifying Raster Data and Vector Semantics for Human-Centric Geospatial Foundation Models
Jun 01, 2026Earth Observation (EO) has fundamentally transformed the monitoring of environmental processes and human activities up to planetary scale. Recent advances in self-supervised learning have given rise to Earth Observation Foundation Models (EOFMs), which leverage petabyte-scale unlabeled EO data to learn transferable representations across a wide range of downstream geospatial tasks. Despite these advances, current EOFMs remain largely confined to raster modalities, overlooking the rich, structured information encoded in openly-accessible vector data sources such as OpenStreetMap and Overture. Vector data provides explicit and compact representations of geographic entities, including geometry, topology, and semantic relationships, offering critical contextual signals that are often ambiguous or inaccessible in imagery alone. Raster and vector data thus represent complementary views of geographic space: raster data captures continuous physical and spectral patterns, while vector data encodes discrete objects and their relational structure and often represents more of the human rather than the physical systems (e.g. social or demographic data). However, existing geospatial representation learning paradigms treat these modalities in isolation, relying on imperfect and often lossy transformations to bridge them. This perspective paper calls for a paradigm shift toward joint Spatial Representation Learning (SRL) in an unified embedding space that integrate raster perception with vector-based reasoning. Building on emerging efforts in multimodal geospatial learning, we highlight conceptual foundations, technical challenges, and promising directions for aligning heterogeneous spatial data sources. We contend that such integration is essential for developing next-generation geospatial AI systems capable of more accurate, interpretable, and semantically grounded understanding of the Earth.
NARA: Anchor-Conditioned Relation-Aware Contextualization of Heterogeneous Geoentities
May 12, 2026Geospatial foundation models have primarily focused on raster data such as satellite imagery, where self-supervised learning has been widely studied. Vector geospatial data instead represent the world as discrete geoentities with explicit geometry, semantics, and structured spatial relations, including metric proximity and topological relationships. These relations jointly determine how entities interact within space, yet existing representation learning methods remain fragmented, often restricted to specific geometry types or partial spatial relations, limiting their ability to capture unified spatial context across heterogeneous geoentities. We propose NARA (Neural Anchor-conditioned Relation-Aware representation learning), a self-supervised framework for vector geoentities. NARA learns context-dependent representations by jointly modeling semantics, geometry, and spatial relations within a unified framework and captures relational spatial structure beyond proximity alone, enabling rich contextualized representations across heterogeneous geoentities of points, polylines, and polygons. Evaluation on building function classification, traffic speed prediction, and next point-of-interest recommendation shows consistent improvements over prior methods, highlighting the benefit of unified relational modeling for vector geospatial data.
Geography According to ChatGPT -- How Generative AI Represents and Reasons about Geography
Mar 19, 2026Understanding how AI will represent and reason about geography should be a key concern for all of us, as the broader public increasingly interacts with spaces and places through these systems. Similarly, in line with the nature of foundation models, our own research often relies on pre-trained models. Hence, understanding what world AI systems construct is as important as evaluating their accuracy, including factual recall. To motivate the need for such studies, we provide three illustrative vignettes, i.e., exploratory probes, in the hope that they will spark lively discussions and follow-up work: (1) Do models form strong defaults, and how brittle are model outputs to minute syntactic variations? (2) Can distributional shifts resurface from the composition of individually benign tasks, e.g., when using AI systems to create personas? (3) Do we overlook deeper questions of understanding when solely focusing on the ability of systems to recall facts such as geographic principles?
Spatial-Agent: Agentic Geo-spatial Reasoning with Scientific Core Concepts
Jan 23, 2026Geospatial reasoning is essential for real-world applications such as urban analytics, transportation planning, and disaster response. However, existing LLM-based agents often fail at genuine geospatial computation, relying instead on web search or pattern matching while hallucinating spatial relationships. We present Spatial-Agent, an AI agent grounded in foundational theories of spatial information science. Our approach formalizes geo-analytical question answering as a concept transformation problem, where natural-language questions are parsed into executable workflows represented as GeoFlow Graphs -- directed acyclic graphs with nodes corresponding to spatial concepts and edges representing transformations. Drawing on spatial information theory, Spatial-Agent extracts spatial concepts, assigns functional roles with principled ordering constraints, and composes transformation sequences through template-based generation. Extensive experiments on MapEval-API and MapQA benchmarks demonstrate that Spatial-Agent significantly outperforms existing baselines including ReAct and Reflexion, while producing interpretable and executable geospatial workflows.
Digital Twin AI: Opportunities and Challenges from Large Language Models to World Models
Jan 04, 2026Digital twins, as precise digital representations of physical systems, have evolved from passive simulation tools into intelligent and autonomous entities through the integration of artificial intelligence technologies. This paper presents a unified four-stage framework that systematically characterizes AI integration across the digital twin lifecycle, spanning modeling, mirroring, intervention, and autonomous management. By synthesizing existing technologies and practices, we distill a unified four-stage framework that systematically characterizes how AI methodologies are embedded across the digital twin lifecycle: (1) modeling the physical twin through physics-based and physics-informed AI approaches, (2) mirroring the physical system into a digital twin with real-time synchronization, (3) intervening in the physical twin through predictive modeling, anomaly detection, and optimization strategies, and (4) achieving autonomous management through large language models, foundation models, and intelligent agents. We analyze the synergy between physics-based modeling and data-driven learning, highlighting the shift from traditional numerical solvers to physics-informed and foundation models for physical systems. Furthermore, we examine how generative AI technologies, including large language models and generative world models, transform digital twins into proactive and self-improving cognitive systems capable of reasoning, communication, and creative scenario generation. Through a cross-domain review spanning eleven application domains, including healthcare, aerospace, smart manufacturing, robotics, and smart cities, we identify common challenges related to scalability, explainability, and trustworthiness, and outline directions for responsible AI-driven digital twin systems.
Whose Truth? Pluralistic Geo-Alignment for (Agentic) AI
Aug 07, 2025AI (super) alignment describes the challenge of ensuring (future) AI systems behave in accordance with societal norms and goals. While a quickly evolving literature is addressing biases and inequalities, the geographic variability of alignment remains underexplored. Simply put, what is considered appropriate, truthful, or legal can differ widely across regions due to cultural norms, political realities, and legislation. Alignment measures applied to AI/ML workflows can sometimes produce outcomes that diverge from statistical realities, such as text-to-image models depicting balanced gender ratios in company leadership despite existing imbalances. Crucially, some model outputs are globally acceptable, while others, e.g., questions about Kashmir, depend on knowing the user's location and their context. This geographic sensitivity is not new. For instance, Google Maps renders Kashmir's borders differently based on user location. What is new is the unprecedented scale and automation with which AI now mediates knowledge, expresses opinions, and represents geographic reality to millions of users worldwide, often with little transparency about how context is managed. As we approach Agentic AI, the need for spatio-temporally aware alignment, rather than one-size-fits-all approaches, is increasingly urgent. This paper reviews key geographic research problems, suggests topics for future work, and outlines methods for assessing alignment sensitivity.
4KAgent: Agentic Any Image to 4K Super-Resolution
Jul 09, 2025We present 4KAgent, a unified agentic super-resolution generalist system designed to universally upscale any image to 4K resolution (and even higher, if applied iteratively). Our system can transform images from extremely low resolutions with severe degradations, for example, highly distorted inputs at 256x256, into crystal-clear, photorealistic 4K outputs. 4KAgent comprises three core components: (1) Profiling, a module that customizes the 4KAgent pipeline based on bespoke use cases; (2) A Perception Agent, which leverages vision-language models alongside image quality assessment experts to analyze the input image and make a tailored restoration plan; and (3) A Restoration Agent, which executes the plan, following a recursive execution-reflection paradigm, guided by a quality-driven mixture-of-expert policy to select the optimal output for each step. Additionally, 4KAgent embeds a specialized face restoration pipeline, significantly enhancing facial details in portrait and selfie photos. We rigorously evaluate our 4KAgent across 11 distinct task categories encompassing a total of 26 diverse benchmarks, setting new state-of-the-art on a broad spectrum of imaging domains. Our evaluations cover natural images, portrait photos, AI-generated content, satellite imagery, fluorescence microscopy, and medical imaging like fundoscopy, ultrasound, and X-ray, demonstrating superior performance in terms of both perceptual (e.g., NIQE, MUSIQ) and fidelity (e.g., PSNR) metrics. By establishing a novel agentic paradigm for low-level vision tasks, we aim to catalyze broader interest and innovation within vision-centric autonomous agents across diverse research communities. We will release all the code, models, and results at: https://4kagent.github.io.
ZooplanktonBench: A Geo-Aware Zooplankton Recognition and Classification Dataset from Marine Observations
May 24, 2025



Plankton are small drifting organisms found throughout the world's oceans. One component of this plankton community is the zooplankton, which includes gelatinous animals and crustaceans (e.g. shrimp), as well as the early life stages (i.e., eggs and larvae) of many commercially important fishes. Being able to monitor zooplankton abundances accurately and understand how populations change in relation to ocean conditions is invaluable to marine science research, with important implications for future marine seafood productivity. While new imaging technologies generate massive amounts of video data of zooplankton, analyzing them using general-purpose computer vision tools developed for general objects turns out to be highly challenging due to the high similarity in appearance between the zooplankton and its background (e.g., marine snow). In this work, we present the ZooplanktonBench, a benchmark dataset containing images and videos of zooplankton associated with rich geospatial metadata (e.g., geographic coordinates, depth, etc.) in various water ecosystems. ZooplanktonBench defines a collection of tasks to detect, classify, and track zooplankton in challenging settings, including highly cluttered environments, living vs non-living classification, objects with similar shapes, and relatively small objects. Our dataset presents unique challenges and opportunities for state-of-the-art computer vision systems to evolve and improve visual understanding in a dynamic environment with huge variations and be geo-aware.
Feature-Augmented Deep Networks for Multiscale Building Segmentation in High-Resolution UAV and Satellite Imagery
May 08, 2025
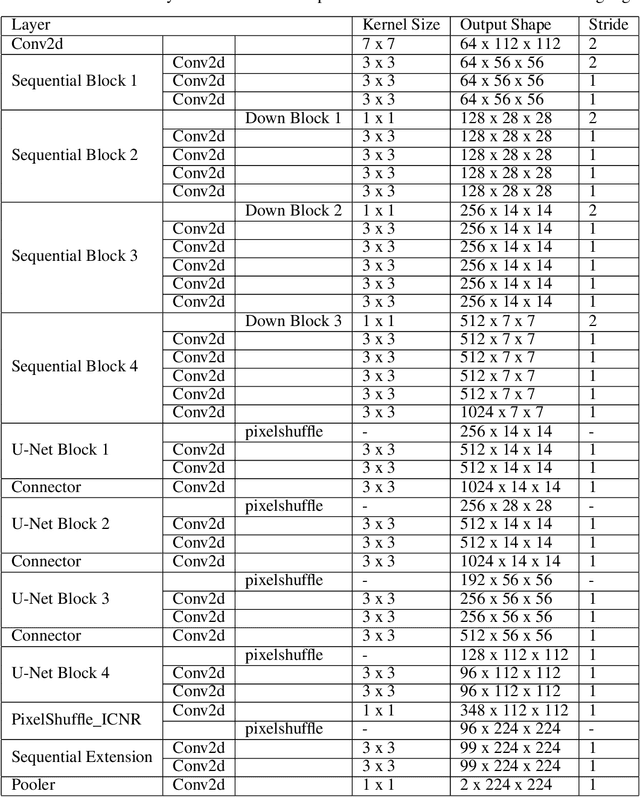

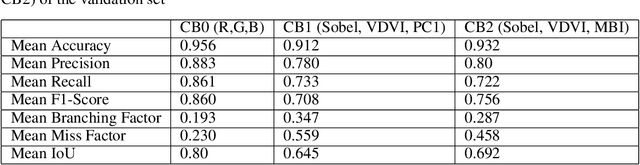
Accurate building segmentation from high-resolution RGB imagery remains challenging due to spectral similarity with non-building features, shadows, and irregular building geometries. In this study, we present a comprehensive deep learning framework for multiscale building segmentation using RGB aerial and satellite imagery with spatial resolutions ranging from 0.4m to 2.7m. We curate a diverse, multi-sensor dataset and introduce feature-augmented inputs by deriving secondary representations including Principal Component Analysis (PCA), Visible Difference Vegetation Index (VDVI), Morphological Building Index (MBI), and Sobel edge filters from RGB channels. These features guide a Res-U-Net architecture in learning complex spatial patterns more effectively. We also propose training policies incorporating layer freezing, cyclical learning rates, and SuperConvergence to reduce training time and resource usage. Evaluated on a held-out WorldView-3 image, our model achieves an overall accuracy of 96.5%, an F1-score of 0.86, and an Intersection over Union (IoU) of 0.80, outperforming existing RGB-based benchmarks. This study demonstrates the effectiveness of combining multi-resolution imagery, feature augmentation, and optimized training strategies for robust building segmentation in remote sensing applications.
GAIR: Improving Multimodal Geo-Foundation Model with Geo-Aligned Implicit Representations
Mar 20, 2025



Advancements in vision and language foundation models have inspired the development of geo-foundation models (GeoFMs), enhancing performance across diverse geospatial tasks. However, many existing GeoFMs primarily focus on overhead remote sensing (RS) data while neglecting other data modalities such as ground-level imagery. A key challenge in multimodal GeoFM development is to explicitly model geospatial relationships across modalities, which enables generalizability across tasks, spatial scales, and temporal contexts. To address these limitations, we propose GAIR, a novel multimodal GeoFM architecture integrating overhead RS data, street view (SV) imagery, and their geolocation metadata. We utilize three factorized neural encoders to project an SV image, its geolocation, and an RS image into the embedding space. The SV image needs to be located within the RS image's spatial footprint but does not need to be at its geographic center. In order to geographically align the SV image and RS image, we propose a novel implicit neural representations (INR) module that learns a continuous RS image representation and looks up the RS embedding at the SV image's geolocation. Next, these geographically aligned SV embedding, RS embedding, and location embedding are trained with contrastive learning objectives from unlabeled data. We evaluate GAIR across 10 geospatial tasks spanning RS image-based, SV image-based, and location embedding-based benchmarks. Experimental results demonstrate that GAIR outperforms state-of-the-art GeoFMs and other strong baselines, highlighting its effectiveness in learning generalizable and transferable geospatial representations.