 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTorchSpatial: A Location Encoding Framework and Benchmark for Spatial Representation Learning
Jun 21, 2024Spatial representation learning (SRL) aims at learning general-purpose neural network representations from various types of spatial data (e.g., points, polylines, polygons, networks, images, etc.) in their native formats. Learning good spatial representations is a fundamental problem for various downstream applications such as species distribution modeling, weather forecasting, trajectory generation, geographic question answering, etc. Even though SRL has become the foundation of almost all geospatial artificial intelligence (GeoAI) research, we have not yet seen significant efforts to develop an extensive deep learning framework and benchmark to support SRL model development and evaluation. To fill this gap, we propose TorchSpatial, a learning framework and benchmark for location (point) encoding, which is one of the most fundamental data types of spatial representation learning. TorchSpatial contains three key components: 1) a unified location encoding framework that consolidates 15 commonly recognized location encoders, ensuring scalability and reproducibility of the implementations; 2) the LocBench benchmark tasks encompassing 7 geo-aware image classification and 4 geo-aware image regression datasets; 3) a comprehensive suite of evaluation metrics to quantify geo-aware models' overall performance as well as their geographic bias, with a novel Geo-Bias Score metric. Finally, we provide a detailed analysis and insights into the model performance and geographic bias of different location encoders. We believe TorchSpatial will foster future advancement of spatial representation learning and spatial fairness in GeoAI research. The TorchSpatial model framework, LocBench, and Geo-Bias Score evaluation framework are available at https://github.com/seai-lab/TorchSpatial.
On the Promises and Challenges of Multimodal Foundation Models for Geographical, Environmental, Agricultural, and Urban Planning Applications
Dec 23, 2023
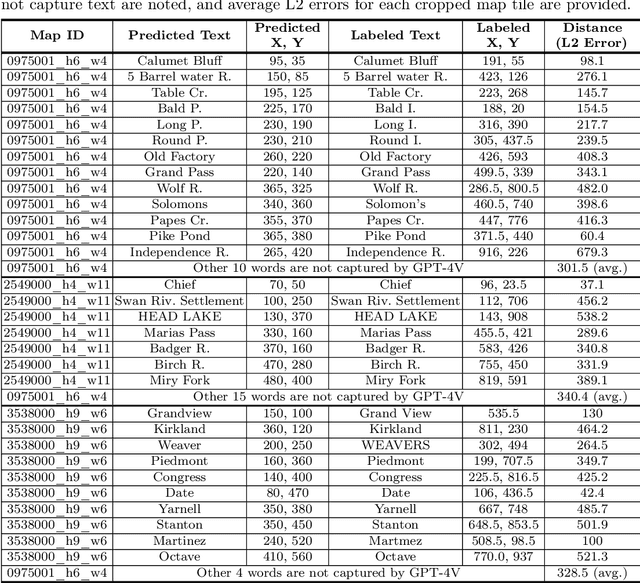


The advent of large language models (LLMs) has heightened interest in their potential for multimodal applications that integrate language and vision. This paper explores the capabilities of GPT-4V in the realms of geography, environmental science, agriculture, and urban planning by evaluating its performance across a variety of tasks. Data sources comprise satellite imagery, aerial photos, ground-level images, field images, and public datasets. The model is evaluated on a series of tasks including geo-localization, textual data extraction from maps, remote sensing image classification, visual question answering, crop type identification, disease/pest/weed recognition, chicken behavior analysis, agricultural object counting, urban planning knowledge question answering, and plan generation. The results indicate the potential of GPT-4V in geo-localization, land cover classification, visual question answering, and basic image understanding. However, there are limitations in several tasks requiring fine-grained recognition and precise counting. While zero-shot learning shows promise, performance varies across problem domains and image complexities. The work provides novel insights into GPT-4V's capabilities and limitations for real-world geospatial, environmental, agricultural, and urban planning challenges. Further research should focus on augmenting the model's knowledge and reasoning for specialized domains through expanded training. Overall, the analysis demonstrates foundational multimodal intelligence, highlighting the potential of multimodal foundation models (FMs) to advance interdisciplinary applications at the nexus of computer vision and language.