 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurvey of HPC in US Research Institutions
Jun 23, 2025

The rapid growth of AI, data-intensive science, and digital twin technologies has driven an unprecedented demand for high-performance computing (HPC) across the research ecosystem. While national laboratories and industrial hyperscalers have invested heavily in exascale and GPU-centric architectures, university-operated HPC systems remain comparatively under-resourced. This survey presents a comprehensive assessment of the HPC landscape across U.S. universities, benchmarking their capabilities against Department of Energy (DOE) leadership-class systems and industrial AI infrastructures. We examine over 50 premier research institutions, analyzing compute capacity, architectural design, governance models, and energy efficiency. Our findings reveal that university clusters, though vital for academic research, exhibit significantly lower growth trajectories (CAGR $\approx$ 18%) than their national ($\approx$ 43%) and industrial ($\approx$ 78%) counterparts. The increasing skew toward GPU-dense AI workloads has widened the capability gap, highlighting the need for federated computing, idle-GPU harvesting, and cost-sharing models. We also identify emerging paradigms, such as decentralized reinforcement learning, as promising opportunities for democratizing AI training within campus environments. Ultimately, this work provides actionable insights for academic leaders, funding agencies, and technology partners to ensure more equitable and sustainable HPC access in support of national research priorities.
QueEn: A Large Language Model for Quechua-English Translation
Dec 06, 2024

Recent studies show that large language models (LLMs) are powerful tools for working with natural language, bringing advances in many areas of computational linguistics. However, these models face challenges when applied to low-resource languages due to limited training data and difficulty in understanding cultural nuances. In this paper, we propose QueEn, a novel approach for Quechua-English translation that combines Retrieval-Augmented Generation (RAG) with parameter-efficient fine-tuning techniques. Our method leverages external linguistic resources through RAG and uses Low-Rank Adaptation (LoRA) for efficient model adaptation. Experimental results show that our approach substantially exceeds baseline models, with a BLEU score of 17.6 compared to 1.5 for standard GPT models. The integration of RAG with fine-tuning allows our system to address the challenges of low-resource language translation while maintaining computational efficiency. This work contributes to the broader goal of preserving endangered languages through advanced language technologies.
OracleSage: Towards Unified Visual-Linguistic Understanding of Oracle Bone Scripts through Cross-Modal Knowledge Fusion
Nov 26, 2024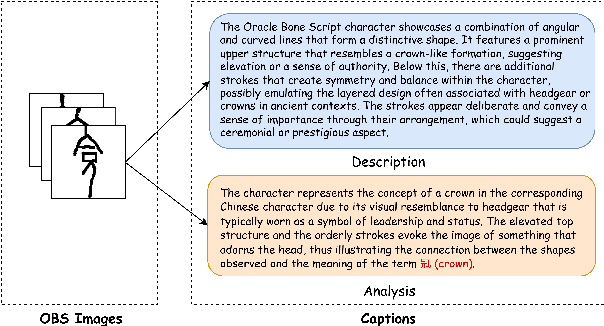

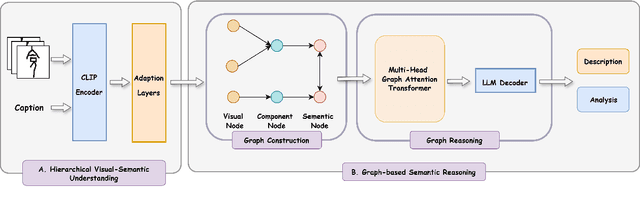
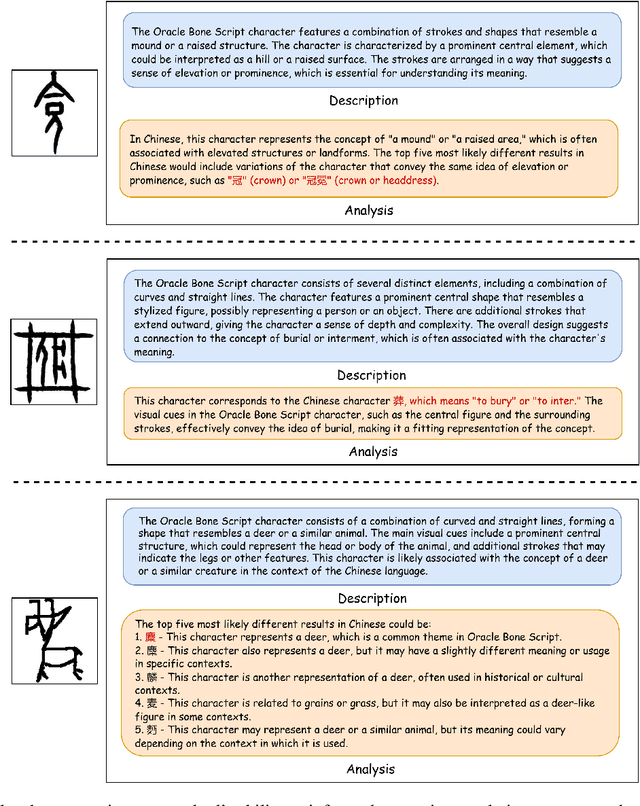
Oracle bone script (OBS), as China's earliest mature writing system, present significant challenges in automatic recognition due to their complex pictographic structures and divergence from modern Chinese characters. We introduce OracleSage, a novel cross-modal framework that integrates hierarchical visual understanding with graph-based semantic reasoning. Specifically, we propose (1) a Hierarchical Visual-Semantic Understanding module that enables multi-granularity feature extraction through progressive fine-tuning of LLaVA's visual backbone, (2) a Graph-based Semantic Reasoning Framework that captures relationships between visual components and semantic concepts through dynamic message passing, and (3) OracleSem, a semantically enriched OBS dataset with comprehensive pictographic and semantic annotations. Experimental results demonstrate that OracleSage significantly outperforms state-of-the-art vision-language models. This research establishes a new paradigm for ancient text interpretation while providing valuable technical support for archaeological studies.
Transcending Language Boundaries: Harnessing LLMs for Low-Resource Language Translation
Nov 18, 2024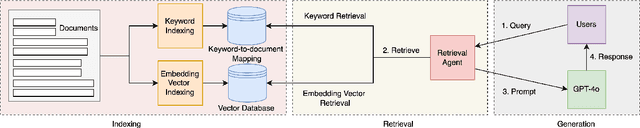
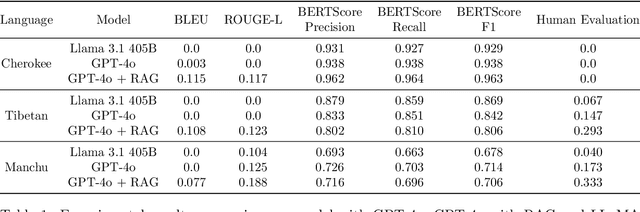


Large Language Models (LLMs) have demonstrated remarkable success across a wide range of tasks and domains. However, their performance in low-resource language translation, particularly when translating into these languages, remains underexplored. This gap poses significant challenges, as linguistic barriers hinder the cultural preservation and development of minority communities. To address this issue, this paper introduces a novel retrieval-based method that enhances translation quality for low-resource languages by focusing on key terms, which involves translating keywords and retrieving corresponding examples from existing data. To evaluate the effectiveness of this method, we conducted experiments translating from English into three low-resource languages: Cherokee, a critically endangered indigenous language of North America; Tibetan, a historically and culturally significant language in Asia; and Manchu, a language with few remaining speakers. Our comparison with the zero-shot performance of GPT-4o and LLaMA 3.1 405B, highlights the significant challenges these models face when translating into low-resource languages. In contrast, our retrieval-based method shows promise in improving both word-level accuracy and overall semantic understanding by leveraging existing resources more effectively.
HELENE: Hessian Layer-wise Clipping and Gradient Annealing for Accelerating Fine-tuning LLM with Zeroth-order Optimization
Nov 16, 2024



Fine-tuning large language models (LLMs) poses significant memory challenges, as the back-propagation process demands extensive resources, especially with growing model sizes. Recent work, MeZO, addresses this issue using a zeroth-order (ZO) optimization method, which reduces memory consumption by matching the usage to the inference phase. However, MeZO experiences slow convergence due to varying curvatures across model parameters. To overcome this limitation, we introduce HELENE, a novel scalable and memory-efficient optimizer that integrates annealed A-GNB gradients with a diagonal Hessian estimation and layer-wise clipping, serving as a second-order pre-conditioner. This combination allows for faster and more stable convergence. Our theoretical analysis demonstrates that HELENE improves convergence rates, particularly for models with heterogeneous layer dimensions, by reducing the dependency on the total parameter space dimension. Instead, the method scales with the largest layer dimension, making it highly suitable for modern LLM architectures. Experimental results on RoBERTa-large and OPT-1.3B across multiple tasks show that HELENE achieves up to a 20x speedup compared to MeZO, with average accuracy improvements of 1.5%. Furthermore, HELENE remains compatible with both full parameter tuning and parameter-efficient fine-tuning (PEFT), outperforming several state-of-the-art optimizers. The codes will be released after reviewing.
Towards Next-Generation Medical Agent: How o1 is Reshaping Decision-Making in Medical Scenarios
Nov 16, 2024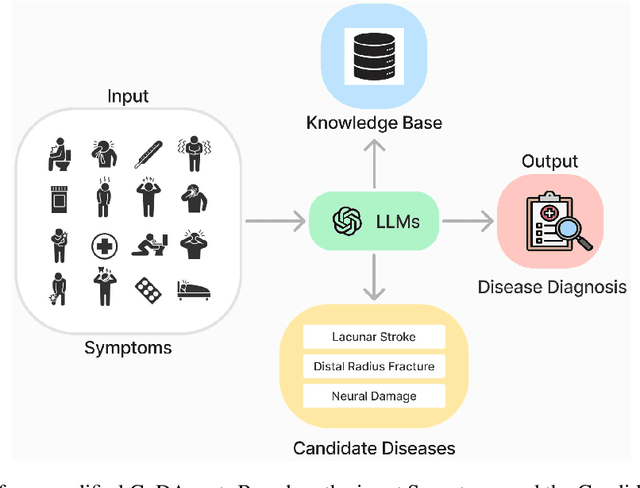


Artificial Intelligence (AI) has become essential in modern healthcare, with large language models (LLMs) offering promising advances in clinical decision-making. Traditional model-based approaches, including those leveraging in-context demonstrations and those with specialized medical fine-tuning, have demonstrated strong performance in medical language processing but struggle with real-time adaptability, multi-step reasoning, and handling complex medical tasks. Agent-based AI systems address these limitations by incorporating reasoning traces, tool selection based on context, knowledge retrieval, and both short- and long-term memory. These additional features enable the medical AI agent to handle complex medical scenarios where decision-making should be built on real-time interaction with the environment. Therefore, unlike conventional model-based approaches that treat medical queries as isolated questions, medical AI agents approach them as complex tasks and behave more like human doctors. In this paper, we study the choice of the backbone LLM for medical AI agents, which is the foundation for the agent's overall reasoning and action generation. In particular, we consider the emergent o1 model and examine its impact on agents' reasoning, tool-use adaptability, and real-time information retrieval across diverse clinical scenarios, including high-stakes settings such as intensive care units (ICUs). Our findings demonstrate o1's ability to enhance diagnostic accuracy and consistency, paving the way for smarter, more responsive AI tools that support better patient outcomes and decision-making efficacy in clinical practice.
Large Language Models for Manufacturing
Oct 28, 2024


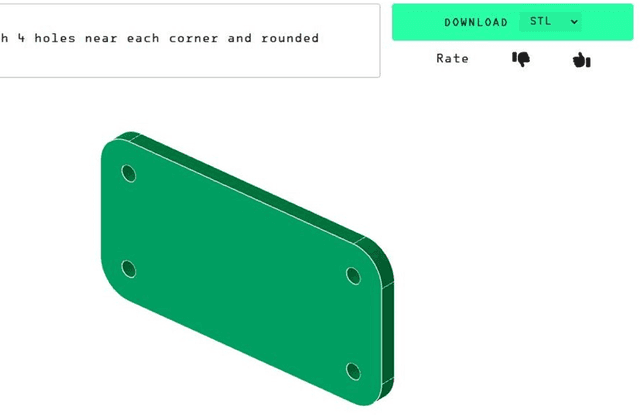
The rapid advances in Large Language Models (LLMs) have the potential to transform manufacturing industry, offering new opportunities to optimize processes, improve efficiency, and drive innovation. This paper provides a comprehensive exploration of the integration of LLMs into the manufacturing domain, focusing on their potential to automate and enhance various aspects of manufacturing, from product design and development to quality control, supply chain optimization, and talent management. Through extensive evaluations across multiple manufacturing tasks, we demonstrate the remarkable capabilities of state-of-the-art LLMs, such as GPT-4V, in understanding and executing complex instructions, extracting valuable insights from vast amounts of data, and facilitating knowledge sharing. We also delve into the transformative potential of LLMs in reshaping manufacturing education, automating coding processes, enhancing robot control systems, and enabling the creation of immersive, data-rich virtual environments through the industrial metaverse. By highlighting the practical applications and emerging use cases of LLMs in manufacturing, this paper aims to provide a valuable resource for professionals, researchers, and decision-makers seeking to harness the power of these technologies to address real-world challenges, drive operational excellence, and unlock sustainable growth in an increasingly competitive landscape.
EG-SpikeFormer: Eye-Gaze Guided Transformer on Spiking Neural Networks for Medical Image Analysis
Oct 12, 2024



Neuromorphic computing has emerged as a promising energy-efficient alternative to traditional artificial intelligence, predominantly utilizing spiking neural networks (SNNs) implemented on neuromorphic hardware. Significant advancements have been made in SNN-based convolutional neural networks (CNNs) and Transformer architectures. However, their applications in the medical imaging domain remain underexplored. In this study, we introduce EG-SpikeFormer, an SNN architecture designed for clinical tasks that integrates eye-gaze data to guide the model's focus on diagnostically relevant regions in medical images. This approach effectively addresses shortcut learning issues commonly observed in conventional models, especially in scenarios with limited clinical data and high demands for model reliability, generalizability, and transparency. Our EG-SpikeFormer not only demonstrates superior energy efficiency and performance in medical image classification tasks but also enhances clinical relevance. By incorporating eye-gaze data, the model improves interpretability and generalization, opening new directions for the application of neuromorphic computing in healthcare.
Evaluation of OpenAI o1: Opportunities and Challenges of AGI
Sep 27, 2024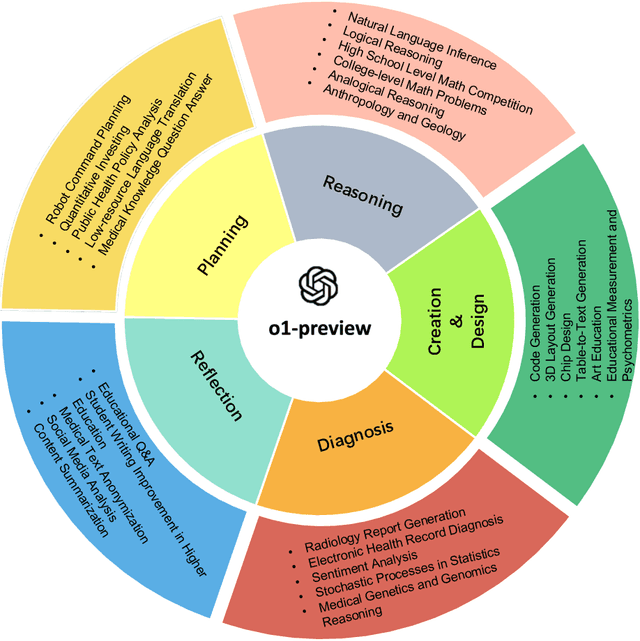


This comprehensive study evaluates the performance of OpenAI's o1-preview large language model across a diverse array of complex reasoning tasks, spanning multiple domains, including computer science, mathematics, natural sciences, medicine, linguistics, and social sciences. Through rigorous testing, o1-preview demonstrated remarkable capabilities, often achieving human-level or superior performance in areas ranging from coding challenges to scientific reasoning and from language processing to creative problem-solving. Key findings include: -83.3% success rate in solving complex competitive programming problems, surpassing many human experts. -Superior ability in generating coherent and accurate radiology reports, outperforming other evaluated models. -100% accuracy in high school-level mathematical reasoning tasks, providing detailed step-by-step solutions. -Advanced natural language inference capabilities across general and specialized domains like medicine. -Impressive performance in chip design tasks, outperforming specialized models in areas such as EDA script generation and bug analysis. -Remarkable proficiency in anthropology and geology, demonstrating deep understanding and reasoning in these specialized fields. -Strong capabilities in quantitative investing. O1 has comprehensive financial knowledge and statistical modeling skills. -Effective performance in social media analysis, including sentiment analysis and emotion recognition. The model excelled particularly in tasks requiring intricate reasoning and knowledge integration across various fields. While some limitations were observed, including occasional errors on simpler problems and challenges with certain highly specialized concepts, the overall results indicate significant progress towards artificial general intelligence.
ALDM-Grasping: Diffusion-aided Zero-Shot Sim-to-Real Transfer for Robot Grasping
Mar 18, 2024



To tackle the "reality gap" encountered in Sim-to-Real transfer, this study proposes a diffusion-based framework that minimizes inconsistencies in grasping actions between the simulation settings and realistic environments. The process begins by training an adversarial supervision layout-to-image diffusion model(ALDM). Then, leverage the ALDM approach to enhance the simulation environment, rendering it with photorealistic fidelity, thereby optimizing robotic grasp task training. Experimental results indicate this framework outperforms existing models in both success rates and adaptability to new environments through improvements in the accuracy and reliability of visual grasping actions under a variety of conditions. Specifically, it achieves a 75\% success rate in grasping tasks under plain backgrounds and maintains a 65\% success rate in more complex scenarios. This performance demonstrates this framework excels at generating controlled image content based on text descriptions, identifying object grasp points, and demonstrating zero-shot learning in complex, unseen scenarios.