 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Next-Generation Medical Agent: How o1 is Reshaping Decision-Making in Medical Scenarios
Nov 16, 2024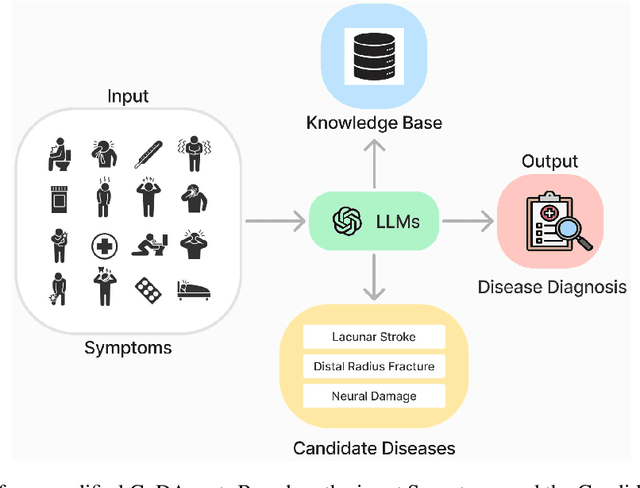


Artificial Intelligence (AI) has become essential in modern healthcare, with large language models (LLMs) offering promising advances in clinical decision-making. Traditional model-based approaches, including those leveraging in-context demonstrations and those with specialized medical fine-tuning, have demonstrated strong performance in medical language processing but struggle with real-time adaptability, multi-step reasoning, and handling complex medical tasks. Agent-based AI systems address these limitations by incorporating reasoning traces, tool selection based on context, knowledge retrieval, and both short- and long-term memory. These additional features enable the medical AI agent to handle complex medical scenarios where decision-making should be built on real-time interaction with the environment. Therefore, unlike conventional model-based approaches that treat medical queries as isolated questions, medical AI agents approach them as complex tasks and behave more like human doctors. In this paper, we study the choice of the backbone LLM for medical AI agents, which is the foundation for the agent's overall reasoning and action generation. In particular, we consider the emergent o1 model and examine its impact on agents' reasoning, tool-use adaptability, and real-time information retrieval across diverse clinical scenarios, including high-stakes settings such as intensive care units (ICUs). Our findings demonstrate o1's ability to enhance diagnostic accuracy and consistency, paving the way for smarter, more responsive AI tools that support better patient outcomes and decision-making efficacy in clinical practice.
Large Language Models for Manufacturing
Oct 28, 2024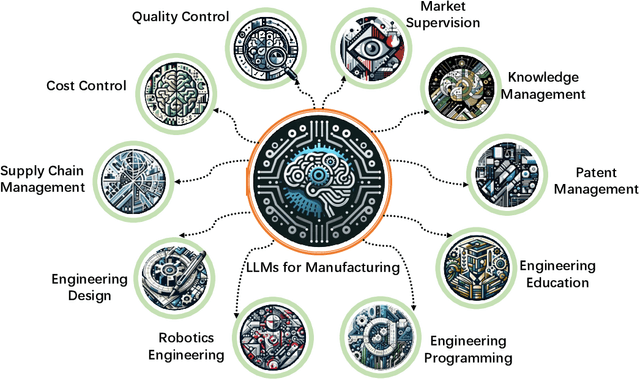


The rapid advances in Large Language Models (LLMs) have the potential to transform manufacturing industry, offering new opportunities to optimize processes, improve efficiency, and drive innovation. This paper provides a comprehensive exploration of the integration of LLMs into the manufacturing domain, focusing on their potential to automate and enhance various aspects of manufacturing, from product design and development to quality control, supply chain optimization, and talent management. Through extensive evaluations across multiple manufacturing tasks, we demonstrate the remarkable capabilities of state-of-the-art LLMs, such as GPT-4V, in understanding and executing complex instructions, extracting valuable insights from vast amounts of data, and facilitating knowledge sharing. We also delve into the transformative potential of LLMs in reshaping manufacturing education, automating coding processes, enhancing robot control systems, and enabling the creation of immersive, data-rich virtual environments through the industrial metaverse. By highlighting the practical applications and emerging use cases of LLMs in manufacturing, this paper aims to provide a valuable resource for professionals, researchers, and decision-makers seeking to harness the power of these technologies to address real-world challenges, drive operational excellence, and unlock sustainable growth in an increasingly competitive landscape.
Evaluation of OpenAI o1: Opportunities and Challenges of AGI
Sep 27, 2024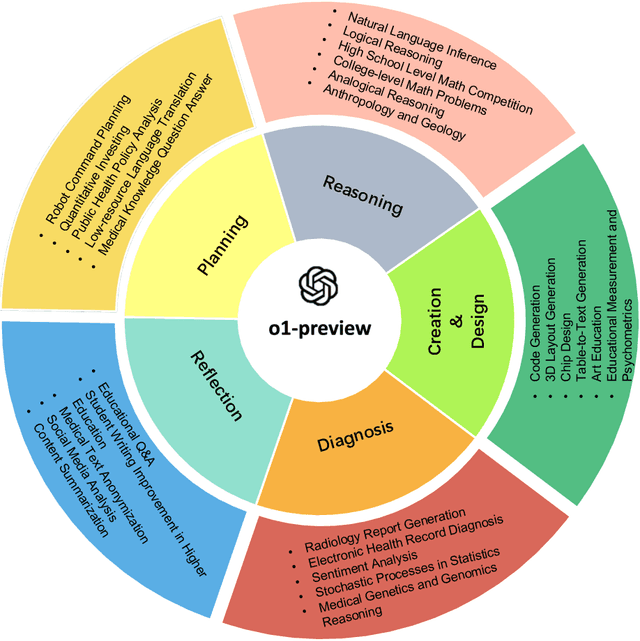


This comprehensive study evaluates the performance of OpenAI's o1-preview large language model across a diverse array of complex reasoning tasks, spanning multiple domains, including computer science, mathematics, natural sciences, medicine, linguistics, and social sciences. Through rigorous testing, o1-preview demonstrated remarkable capabilities, often achieving human-level or superior performance in areas ranging from coding challenges to scientific reasoning and from language processing to creative problem-solving. Key findings include: -83.3% success rate in solving complex competitive programming problems, surpassing many human experts. -Superior ability in generating coherent and accurate radiology reports, outperforming other evaluated models. -100% accuracy in high school-level mathematical reasoning tasks, providing detailed step-by-step solutions. -Advanced natural language inference capabilities across general and specialized domains like medicine. -Impressive performance in chip design tasks, outperforming specialized models in areas such as EDA script generation and bug analysis. -Remarkable proficiency in anthropology and geology, demonstrating deep understanding and reasoning in these specialized fields. -Strong capabilities in quantitative investing. O1 has comprehensive financial knowledge and statistical modeling skills. -Effective performance in social media analysis, including sentiment analysis and emotion recognition. The model excelled particularly in tasks requiring intricate reasoning and knowledge integration across various fields. While some limitations were observed, including occasional errors on simpler problems and challenges with certain highly specialized concepts, the overall results indicate significant progress towards artificial general intelligence.
Reasoning before Comparison: LLM-Enhanced Semantic Similarity Metrics for Domain Specialized Text Analysis
Feb 20, 2024



In this study, we leverage LLM to enhance the semantic analysis and develop similarity metrics for texts, addressing the limitations of traditional unsupervised NLP metrics like ROUGE and BLEU. We develop a framework where LLMs such as GPT-4 are employed for zero-shot text identification and label generation for radiology reports, where the labels are then used as measurements for text similarity. By testing the proposed framework on the MIMIC data, we find that GPT-4 generated labels can significantly improve the semantic similarity assessment, with scores more closely aligned with clinical ground truth than traditional NLP metrics. Our work demonstrates the possibility of conducting semantic analysis of the text data using semi-quantitative reasoning results by the LLMs for highly specialized domains. While the framework is implemented for radiology report similarity analysis, its concept can be extended to other specialized domains as well.
LLMs for Coding and Robotics Education
Feb 09, 2024



Large language models and multimodal large language models have revolutionized artificial intelligence recently. An increasing number of regions are now embracing these advanced technologies. Within this context, robot coding education is garnering increasing attention. To teach young children how to code and compete in robot challenges, large language models are being utilized for robot code explanation, generation, and modification. In this paper, we highlight an important trend in robot coding education. We test several mainstream large language models on both traditional coding tasks and the more challenging task of robot code generation, which includes block diagrams. Our results show that GPT-4V outperforms other models in all of our tests but struggles with generating block diagram images.
Revolutionizing Finance with LLMs: An Overview of Applications and Insights
Jan 22, 2024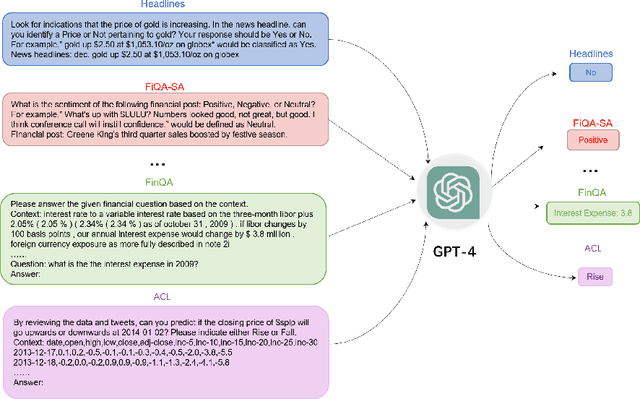

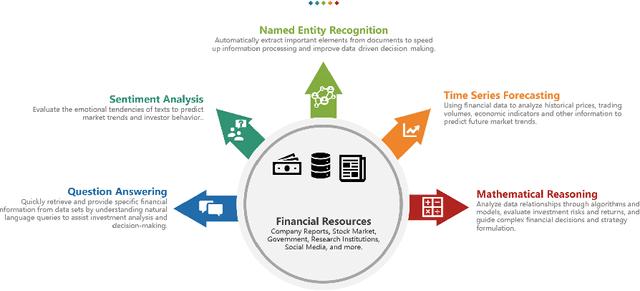
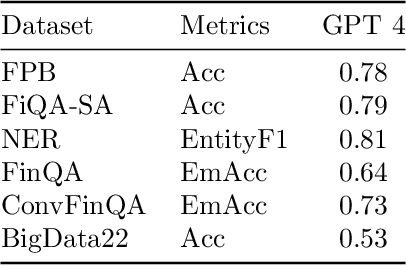
In recent years, Large Language Models (LLMs) like ChatGPT have seen considerable advancements and have been applied in diverse fields. Built on the Transformer architecture, these models are trained on extensive datasets, enabling them to understand and generate human language effectively. In the financial domain, the deployment of LLMs is gaining momentum. These models are being utilized for automating financial report generation, forecasting market trends, analyzing investor sentiment, and offering personalized financial advice. Leveraging their natural language processing capabilities, LLMs can distill key insights from vast financial data, aiding institutions in making informed investment choices and enhancing both operational efficiency and customer satisfaction. In this study, we provide a comprehensive overview of the emerging integration of LLMs into various financial tasks. Additionally, we conducted holistic tests on multiple financial tasks through the combination of natural language instructions. Our findings show that GPT-4 effectively follow prompt instructions across various financial tasks. This survey and evaluation of LLMs in the financial domain aim to deepen the understanding of LLMs' current role in finance for both financial practitioners and LLM researchers, identify new research and application prospects, and highlight how these technologies can be leveraged to solve practical challenges in the finance industry.
Understanding LLMs: A Comprehensive Overview from Training to Inference
Jan 06, 2024
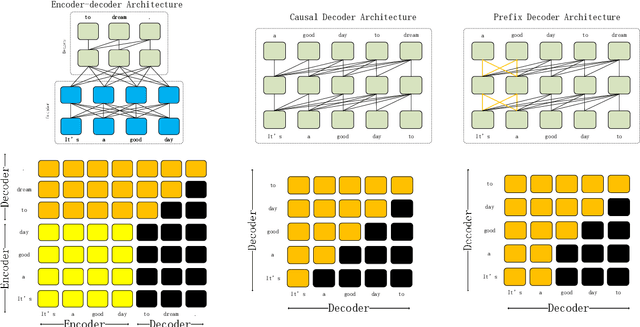
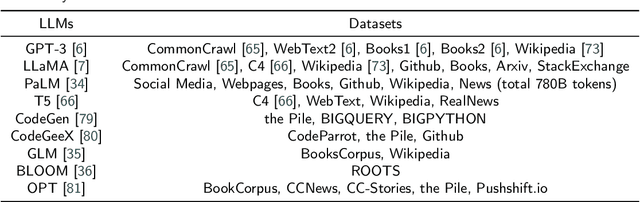
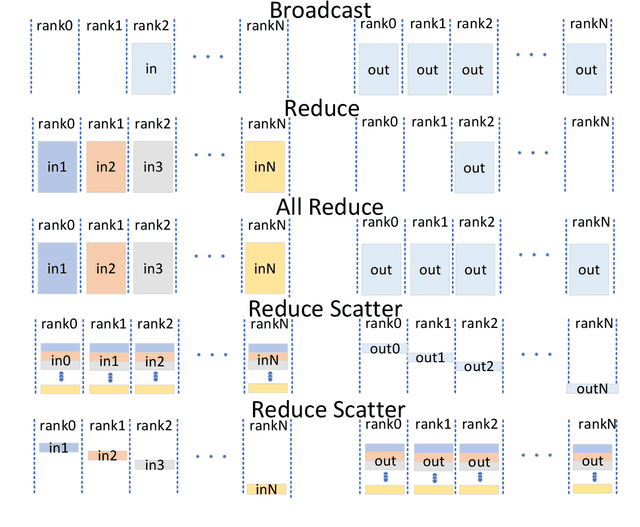
The introduction of ChatGPT has led to a significant increase in the utilization of Large Language Models (LLMs) for addressing downstream tasks. There's an increasing focus on cost-efficient training and deployment within this context. Low-cost training and deployment of LLMs represent the future development trend. This paper reviews the evolution of large language model training techniques and inference deployment technologies aligned with this emerging trend. The discussion on training includes various aspects, including data preprocessing, training architecture, pre-training tasks, parallel training, and relevant content related to model fine-tuning. On the inference side, the paper covers topics such as model compression, parallel computation, memory scheduling, and structural optimization. It also explores LLMs' utilization and provides insights into their future development.
MedEdit: Model Editing for Medical Question Answering with External Knowledge Bases
Sep 27, 2023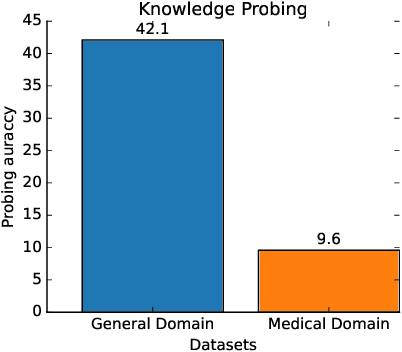
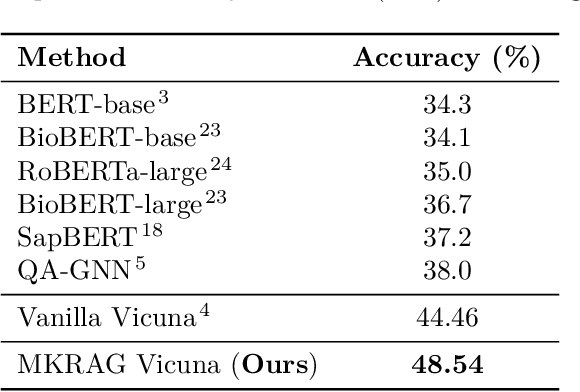
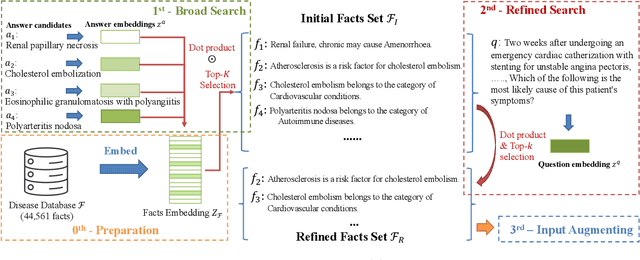

Large Language Models (LLMs), although powerful in general domains, often perform poorly on domain-specific tasks like medical question answering (QA). Moreover, they tend to function as "black-boxes," making it challenging to modify their behavior. Addressing this, our study delves into model editing utilizing in-context learning, aiming to improve LLM responses without the need for fine-tuning or retraining. Specifically, we propose a comprehensive retrieval strategy to extract medical facts from an external knowledge base, and then we incorporate them into the query prompt for the LLM. Focusing on medical QA using the MedQA-SMILE dataset, we evaluate the impact of different retrieval models and the number of facts provided to the LLM. Notably, our edited Vicuna model exhibited an accuracy improvement from 44.46% to 48.54%. This work underscores the potential of model editing to enhance LLM performance, offering a practical approach to mitigate the challenges of black-box LLMs.
Towards Artificial General Intelligence (AGI) in the Internet of Things (IoT): Opportunities and Challenges
Sep 14, 2023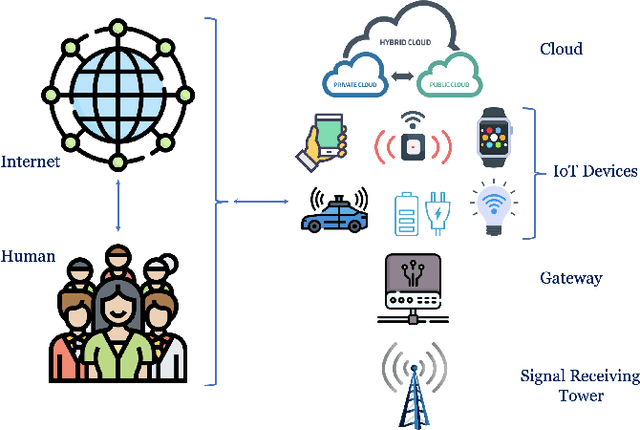
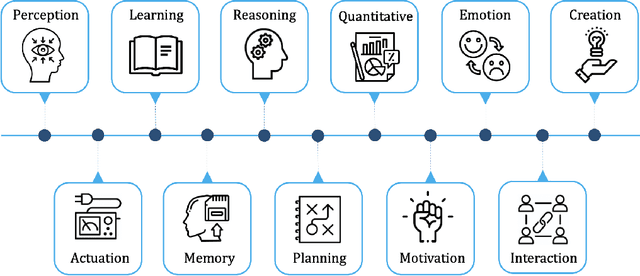
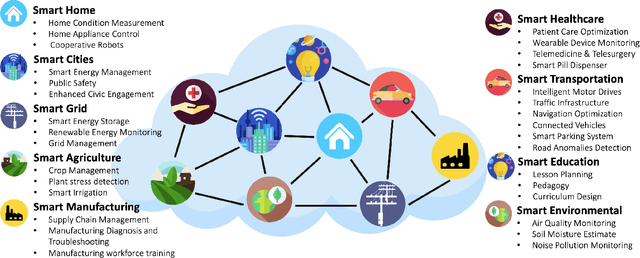
Artificial General Intelligence (AGI), possessing the capacity to comprehend, learn, and execute tasks with human cognitive abilities, engenders significant anticipation and intrigue across scientific, commercial, and societal arenas. This fascination extends particularly to the Internet of Things (IoT), a landscape characterized by the interconnection of countless devices, sensors, and systems, collectively gathering and sharing data to enable intelligent decision-making and automation. This research embarks on an exploration of the opportunities and challenges towards achieving AGI in the context of the IoT. Specifically, it starts by outlining the fundamental principles of IoT and the critical role of Artificial Intelligence (AI) in IoT systems. Subsequently, it delves into AGI fundamentals, culminating in the formulation of a conceptual framework for AGI's seamless integration within IoT. The application spectrum for AGI-infused IoT is broad, encompassing domains ranging from smart grids, residential environments, manufacturing, and transportation to environmental monitoring, agriculture, healthcare, and education. However, adapting AGI to resource-constrained IoT settings necessitates dedicated research efforts. Furthermore, the paper addresses constraints imposed by limited computing resources, intricacies associated with large-scale IoT communication, as well as the critical concerns pertaining to security and privacy.
Evaluating Large Language Models for Radiology Natural Language Processing
Jul 27, 2023
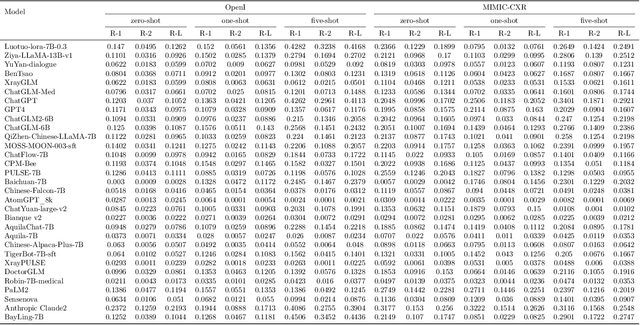
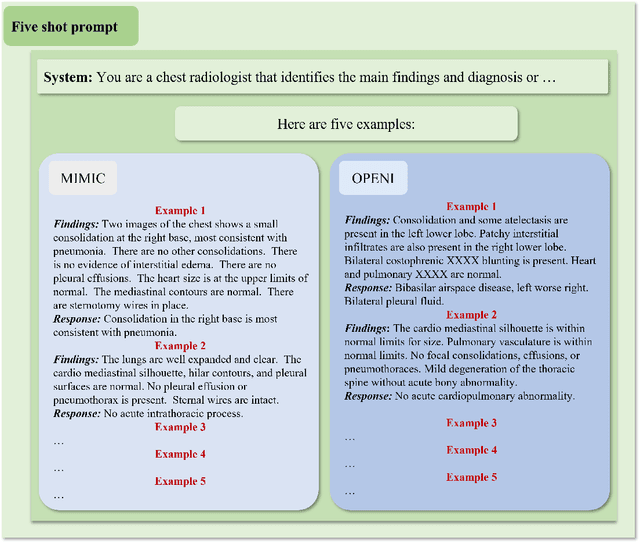
The rise of large language models (LLMs) has marked a pivotal shift in the field of natural language processing (NLP). LLMs have revolutionized a multitude of domains, and they have made a significant impact in the medical field. Large language models are now more abundant than ever, and many of these models exhibit bilingual capabilities, proficient in both English and Chinese. However, a comprehensive evaluation of these models remains to be conducted. This lack of assessment is especially apparent within the context of radiology NLP. This study seeks to bridge this gap by critically evaluating thirty two LLMs in interpreting radiology reports, a crucial component of radiology NLP. Specifically, the ability to derive impressions from radiologic findings is assessed. The outcomes of this evaluation provide key insights into the performance, strengths, and weaknesses of these LLMs, informing their practical applications within the medical domain.