 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Mobile Sensing with Event Cameras on High-mobility Resource-constrained Devices: A Survey
Mar 29, 2025With the increasing complexity of mobile device applications, these devices are evolving toward high mobility. This shift imposes new demands on mobile sensing, particularly in terms of achieving high accuracy and low latency. Event-based vision has emerged as a disruptive paradigm, offering high temporal resolution, low latency, and energy efficiency, making it well-suited for high-accuracy and low-latency sensing tasks on high-mobility platforms. However, the presence of substantial noisy events, the lack of inherent semantic information, and the large data volume pose significant challenges for event-based data processing on resource-constrained mobile devices. This paper surveys the literature over the period 2014-2024, provides a comprehensive overview of event-based mobile sensing systems, covering fundamental principles, event abstraction methods, algorithmic advancements, hardware and software acceleration strategies. We also discuss key applications of event cameras in mobile sensing, including visual odometry, object tracking, optical flow estimation, and 3D reconstruction, while highlighting the challenges associated with event data processing, sensor fusion, and real-time deployment. Furthermore, we outline future research directions, such as improving event camera hardware with advanced optics, leveraging neuromorphic computing for efficient processing, and integrating bio-inspired algorithms to enhance perception. To support ongoing research, we provide an open-source \textit{Online Sheet} with curated resources and recent developments. We hope this survey serves as a valuable reference, facilitating the adoption of event-based vision across diverse applications.
Mathematics and Machine Creativity: A Survey on Bridging Mathematics with AI
Dec 21, 2024
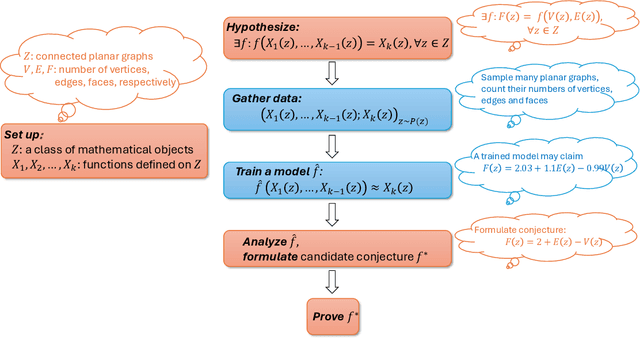
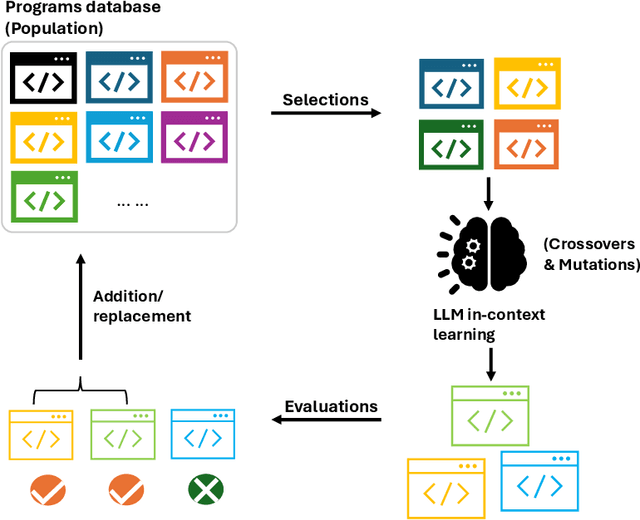
This paper presents a comprehensive survey on the applications of artificial intelligence (AI) in mathematical research, highlighting the transformative role AI has begun to play in this domain. Traditionally, AI advancements have heavily relied on theoretical foundations from fields like mathematics and statistics. However, recent developments in AI, particularly in reinforcement learning (RL) and large language models (LLMs), have demonstrated the potential for AI to contribute back to mathematics, offering flexible algorithmic frameworks and powerful inductive reasoning capabilities that support various aspects of mathematical research. This survey aims to establish a bridge between AI and mathematics, providing insights into the mutual benefits and fostering deeper interdisciplinary understanding. In particular, we argue that while current AI and LLMs may struggle with complex deductive reasoning, their inherent creativity holds significant potential to support and inspire mathematical research. This creative capability, often overlooked, could be the key to unlocking new perspectives and methodologies in mathematics. Furthermore, we address the lack of cross-disciplinary communication: mathematicians may not fully comprehend the latest advances in AI, while AI researchers frequently prioritize benchmarks and standardized testing over AI's applications in frontier mathematical research. This paper seeks to close that gap, offering a detailed exploration of AI's basic knowledge, its strengths, and its emerging applications in the mathematical sciences.
Opportunities and Challenges of Large Language Models for Low-Resource Languages in Humanities Research
Dec 09, 2024Low-resource languages serve as invaluable repositories of human history, embodying cultural evolution and intellectual diversity. Despite their significance, these languages face critical challenges, including data scarcity and technological limitations, which hinder their comprehensive study and preservation. Recent advancements in large language models (LLMs) offer transformative opportunities for addressing these challenges, enabling innovative methodologies in linguistic, historical, and cultural research. This study systematically evaluates the applications of LLMs in low-resource language research, encompassing linguistic variation, historical documentation, cultural expressions, and literary analysis. By analyzing technical frameworks, current methodologies, and ethical considerations, this paper identifies key challenges such as data accessibility, model adaptability, and cultural sensitivity. Given the cultural, historical, and linguistic richness inherent in low-resource languages, this work emphasizes interdisciplinary collaboration and the development of customized models as promising avenues for advancing research in this domain. By underscoring the potential of integrating artificial intelligence with the humanities to preserve and study humanity's linguistic and cultural heritage, this study fosters global efforts towards safeguarding intellectual diversity.
Transcending Language Boundaries: Harnessing LLMs for Low-Resource Language Translation
Nov 18, 2024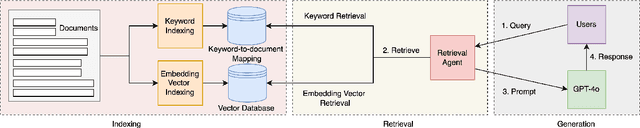
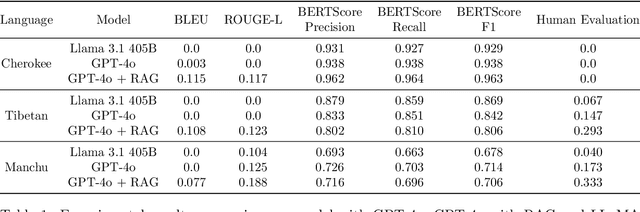


Large Language Models (LLMs) have demonstrated remarkable success across a wide range of tasks and domains. However, their performance in low-resource language translation, particularly when translating into these languages, remains underexplored. This gap poses significant challenges, as linguistic barriers hinder the cultural preservation and development of minority communities. To address this issue, this paper introduces a novel retrieval-based method that enhances translation quality for low-resource languages by focusing on key terms, which involves translating keywords and retrieving corresponding examples from existing data. To evaluate the effectiveness of this method, we conducted experiments translating from English into three low-resource languages: Cherokee, a critically endangered indigenous language of North America; Tibetan, a historically and culturally significant language in Asia; and Manchu, a language with few remaining speakers. Our comparison with the zero-shot performance of GPT-4o and LLaMA 3.1 405B, highlights the significant challenges these models face when translating into low-resource languages. In contrast, our retrieval-based method shows promise in improving both word-level accuracy and overall semantic understanding by leveraging existing resources more effectively.
Towards Next-Generation Medical Agent: How o1 is Reshaping Decision-Making in Medical Scenarios
Nov 16, 2024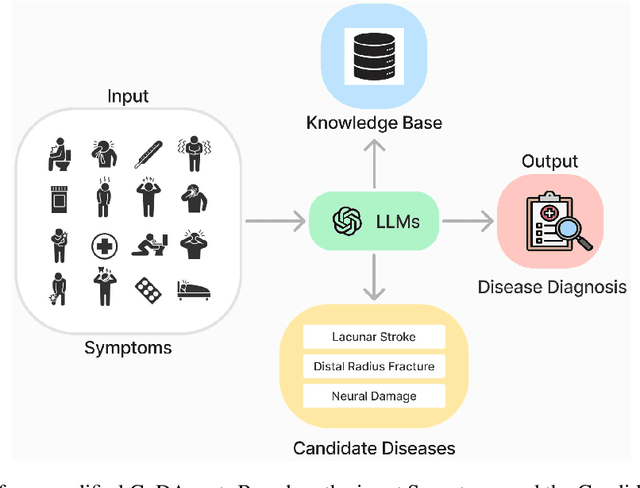

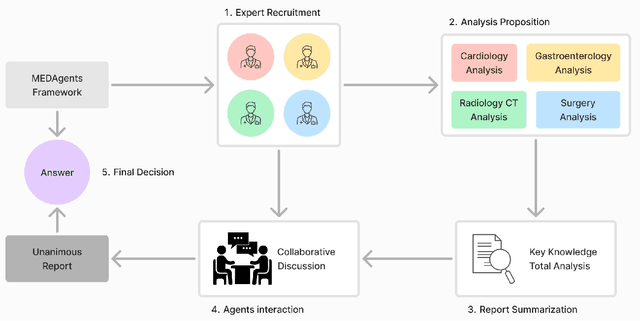

Artificial Intelligence (AI) has become essential in modern healthcare, with large language models (LLMs) offering promising advances in clinical decision-making. Traditional model-based approaches, including those leveraging in-context demonstrations and those with specialized medical fine-tuning, have demonstrated strong performance in medical language processing but struggle with real-time adaptability, multi-step reasoning, and handling complex medical tasks. Agent-based AI systems address these limitations by incorporating reasoning traces, tool selection based on context, knowledge retrieval, and both short- and long-term memory. These additional features enable the medical AI agent to handle complex medical scenarios where decision-making should be built on real-time interaction with the environment. Therefore, unlike conventional model-based approaches that treat medical queries as isolated questions, medical AI agents approach them as complex tasks and behave more like human doctors. In this paper, we study the choice of the backbone LLM for medical AI agents, which is the foundation for the agent's overall reasoning and action generation. In particular, we consider the emergent o1 model and examine its impact on agents' reasoning, tool-use adaptability, and real-time information retrieval across diverse clinical scenarios, including high-stakes settings such as intensive care units (ICUs). Our findings demonstrate o1's ability to enhance diagnostic accuracy and consistency, paving the way for smarter, more responsive AI tools that support better patient outcomes and decision-making efficacy in clinical practice.
Legal Evalutions and Challenges of Large Language Models
Nov 15, 2024



In this paper, we review legal testing methods based on Large Language Models (LLMs), using the OPENAI o1 model as a case study to evaluate the performance of large models in applying legal provisions. We compare current state-of-the-art LLMs, including open-source, closed-source, and legal-specific models trained specifically for the legal domain. Systematic tests are conducted on English and Chinese legal cases, and the results are analyzed in depth. Through systematic testing of legal cases from common law systems and China, this paper explores the strengths and weaknesses of LLMs in understanding and applying legal texts, reasoning through legal issues, and predicting judgments. The experimental results highlight both the potential and limitations of LLMs in legal applications, particularly in terms of challenges related to the interpretation of legal language and the accuracy of legal reasoning. Finally, the paper provides a comprehensive analysis of the advantages and disadvantages of various types of models, offering valuable insights and references for the future application of AI in the legal field.
3D-CT-GPT: Generating 3D Radiology Reports through Integration of Large Vision-Language Models
Sep 28, 2024



Medical image analysis is crucial in modern radiological diagnostics, especially given the exponential growth in medical imaging data. The demand for automated report generation systems has become increasingly urgent. While prior research has mainly focused on using machine learning and multimodal language models for 2D medical images, the generation of reports for 3D medical images has been less explored due to data scarcity and computational complexities. This paper introduces 3D-CT-GPT, a Visual Question Answering (VQA)-based medical visual language model specifically designed for generating radiology reports from 3D CT scans, particularly chest CTs. Extensive experiments on both public and private datasets demonstrate that 3D-CT-GPT significantly outperforms existing methods in terms of report accuracy and quality. Although current methods are few, including the partially open-source CT2Rep and the open-source M3D, we ensured fair comparison through appropriate data conversion and evaluation methodologies. Experimental results indicate that 3D-CT-GPT enhances diagnostic accuracy and report coherence, establishing itself as a robust solution for clinical radiology report generation. Future work will focus on expanding the dataset and further optimizing the model to enhance its performance and applicability.
Evaluation of OpenAI o1: Opportunities and Challenges of AGI
Sep 27, 2024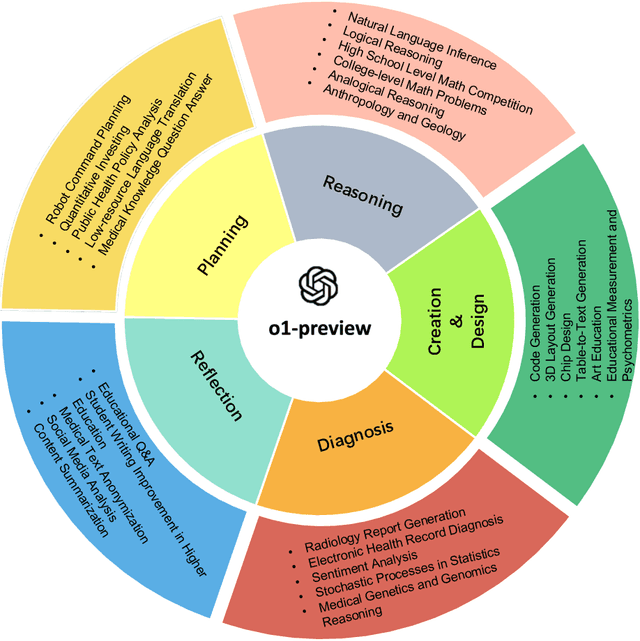

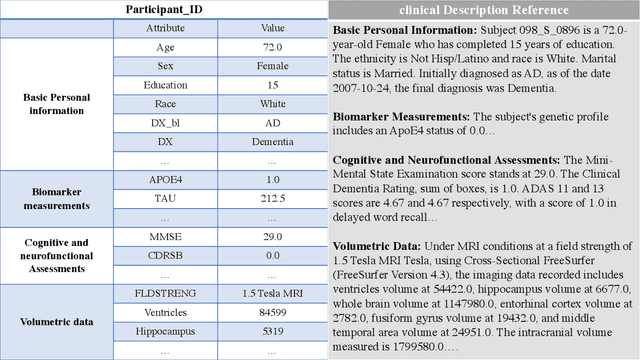

This comprehensive study evaluates the performance of OpenAI's o1-preview large language model across a diverse array of complex reasoning tasks, spanning multiple domains, including computer science, mathematics, natural sciences, medicine, linguistics, and social sciences. Through rigorous testing, o1-preview demonstrated remarkable capabilities, often achieving human-level or superior performance in areas ranging from coding challenges to scientific reasoning and from language processing to creative problem-solving. Key findings include: -83.3% success rate in solving complex competitive programming problems, surpassing many human experts. -Superior ability in generating coherent and accurate radiology reports, outperforming other evaluated models. -100% accuracy in high school-level mathematical reasoning tasks, providing detailed step-by-step solutions. -Advanced natural language inference capabilities across general and specialized domains like medicine. -Impressive performance in chip design tasks, outperforming specialized models in areas such as EDA script generation and bug analysis. -Remarkable proficiency in anthropology and geology, demonstrating deep understanding and reasoning in these specialized fields. -Strong capabilities in quantitative investing. O1 has comprehensive financial knowledge and statistical modeling skills. -Effective performance in social media analysis, including sentiment analysis and emotion recognition. The model excelled particularly in tasks requiring intricate reasoning and knowledge integration across various fields. While some limitations were observed, including occasional errors on simpler problems and challenges with certain highly specialized concepts, the overall results indicate significant progress towards artificial general intelligence.
HARP: Human-Assisted Regrouping with Permutation Invariant Critic for Multi-Agent Reinforcement Learning
Sep 18, 2024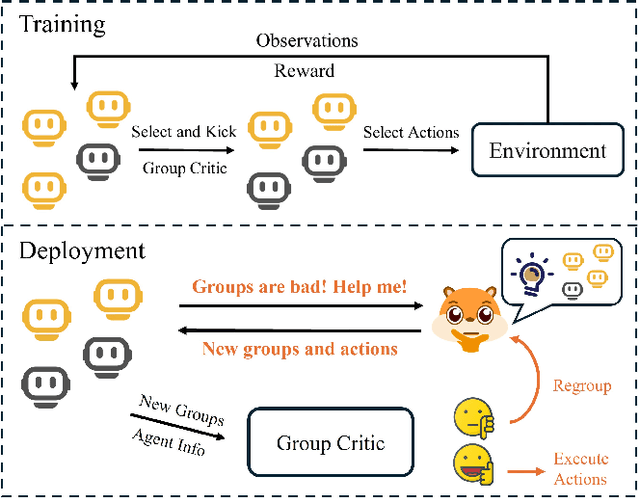
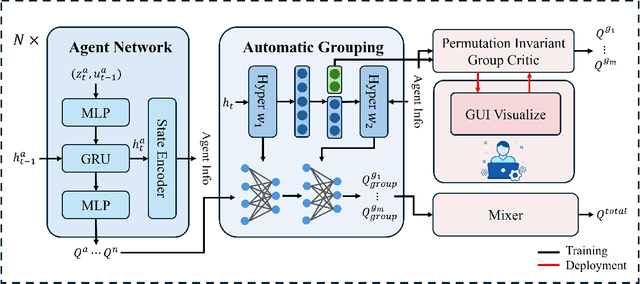
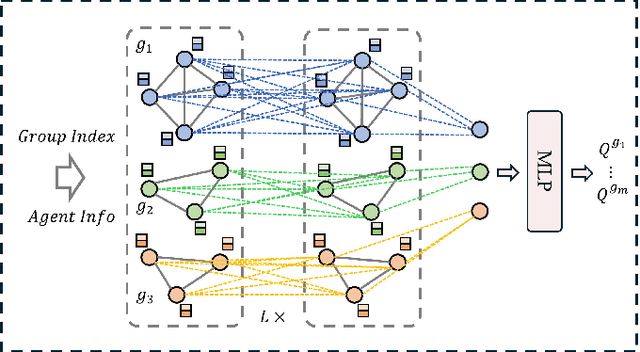

Human-in-the-loop reinforcement learning integrates human expertise to accelerate agent learning and provide critical guidance and feedback in complex fields. However, many existing approaches focus on single-agent tasks and require continuous human involvement during the training process, significantly increasing the human workload and limiting scalability. In this paper, we propose HARP (Human-Assisted Regrouping with Permutation Invariant Critic), a multi-agent reinforcement learning framework designed for group-oriented tasks. HARP integrates automatic agent regrouping with strategic human assistance during deployment, enabling and allowing non-experts to offer effective guidance with minimal intervention. During training, agents dynamically adjust their groupings to optimize collaborative task completion. When deployed, they actively seek human assistance and utilize the Permutation Invariant Group Critic to evaluate and refine human-proposed groupings, allowing non-expert users to contribute valuable suggestions. In multiple collaboration scenarios, our approach is able to leverage limited guidance from non-experts and enhance performance. The project can be found at https://github.com/huawen-hu/HARP.
A Comprehensive Review of Multimodal Large Language Models: Performance and Challenges Across Different Tasks
Aug 02, 2024
In an era defined by the explosive growth of data and rapid technological advancements, Multimodal Large Language Models (MLLMs) stand at the forefront of artificial intelligence (AI) systems. Designed to seamlessly integrate diverse data types-including text, images, videos, audio, and physiological sequences-MLLMs address the complexities of real-world applications far beyond the capabilities of single-modality systems. In this paper, we systematically sort out the applications of MLLM in multimodal tasks such as natural language, vision, and audio. We also provide a comparative analysis of the focus of different MLLMs in the tasks, and provide insights into the shortcomings of current MLLMs, and suggest potential directions for future research. Through these discussions, this paper hopes to provide valuable insights for the further development and application of MLLM.