 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntracranial Aneurysm Classification and Segmentation via Tri-Axial ROI and Multi-Task Learning
Jun 25, 2026Intracranial aneurysms are often asymptomatic until rupture, which carries high mortality. Rupture risk assessment and treatment planning depend on both aneurysm morphology and anatomical location, yet existing automated methods remain limited to binary detection without fine-grained anatomical classification or multi-class segmentation. We present a multi-task framework that simultaneously performs multi-label classification, multi-class aneurysm segmentation, and multi-class vessel segmentation across 13 anatomical locations and four imaging modalities (CTA, MRA, T2, T1-post). Our two-stage approach combines a fast 2D tri-axial Region of Interest (ROI) extraction method with a 3D multi-task nnU-Net backbone. A dual-decoder design mitigates the extreme volume imbalance between aneurysm and vessel classes, while cross-attention pooling and modality-specific auxiliary heads improve feature learning across heterogeneous inputs. Our two-fold ensemble achieved 2nd place in the RSNA 2025 Intracranial Aneurysm Detection challenge. Code, model weights, and a 3D Slicer plugin are publicly available.
FPED: A Functional-Network Prior-Guided Mixture-of-Experts Framework for Interpretable Brain Decoding
May 19, 2026Visual image reconstruction from functional Magnetic Resonance Imaging (fMRI) is a fundamental task in brain decoding, providing a crucial pathway for understanding human perceptual mechanisms and developing advanced brain-computer interfaces (BCIs). However, most current methods simply flatten fMRI signals from localized visual cortices into one-dimensional (1D) vectors, mapping them directly into latent spaces such as that of Contrastive Language-Image Pre-training (CLIP). This paradigm not only disrupts the inherent network topology of the brain-leading to limited neuroscientific interpretability-but also overlooks the synergistic contributions of other distributed functional networks in processing high-level visual semantics. To address these limitations, we propose FPED, a Functional-Network Prior-Guided Mixture of Experts (MoE) framework for interpretable brain decoding. FPED explicitly models different functional brain networks as specialized experts and employs adaptive routing to capture their complementary contributions to visual semantic understanding. Unlike conventional homogeneous decoding paradigms, our framework incorporates neurobiologically grounded priors to enable structured and interpretable network-level representation learning. Experimental results demonstrate that FPED achieves highly competitive semantic reconstruction performance with only 0.68B parameters. The learned routing dynamics reveal biologically meaningful correspondence between functional brain networks and modality-specific semantic processing, providing transparent neuroscientific interpretability. This suggests that brain network-aware expert modeling is a promising direction for bridging neural decoding and biologically inspired artificial intelligence.
Safactory: A Scalable Agent Factory for Trustworthy Autonomous Intelligence
May 07, 2026As large models evolve from conversational assistants into autonomous agents, challenges increasingly arise from long-horizon decision making, tool use, and real environment interaction. Existing agenticinfrastructure remain fragmented across evaluation, data management, and agent evolution, making it difficult to discover risks systematically and improve models in a continuous closed loop. In this report, we present \textbf{Safactory}, a scalable agent factory for trustworthy autonomous intelligence. Safactory integrates three tightly coupled platforms: a \textbf{Parallel Simulation Platform} for trajectory generation, a \textbf{Trustworthy Data Platform} for trajectory storage and experience extraction, and an \textbf{Autonomous Evolution Platform} for asynchronous reinforcement learning and on-policy distillation. As far as we know, Safactory is the first framework to propose a unified evolutionary pipeline for next-generation trustworthy autonomous intelligence.
ULF-Loc: Unbiased Landmark Feature for Robust Visual Localization with 3D Gaussian Splatting
May 06, 2026Visual localization is a core technology for augmented reality and autonomous navigation. Recent methods combine the efficient rendering of 3D Gaussian Splatting (3DGS) with feature-based localization. These methods rely on direct matching between 2D query features and the 3D Gaussian feature field, but this often results in mismatches due to an inherent bias in the learned Gaussian feature. We theoretically analyze the feature learning process in 3DGS, revealing that the widely adopted $α$-blending optimization inherently introduces bias into 3D point features. This bias stems from the entanglement between individual Gaussians and their neighboring Gaussians, making the learned features unsuitable for precise matching tasks. Motivated by these findings, we propose ULF-Loc, an unbiased landmark feature framework that replaces biased feature optimization with geometry-weighted feature fusion. We further introduce keypoint-consensus landmark sampling to select reliable Gaussians and local geometric consistency verification to reject mismatches caused by rendering artifacts. On the Cambridge Landmarks dataset, ULF-Loc reduces the mean median translation error by 17\% compared to the state-of-the-art, while achieving superior efficiency with only 1/10 the training time and 1/6 the GPU memory of STDLoc.
Federated Distributional Reinforcement Learning with Distributional Critic Regularization
Mar 18, 2026Federated reinforcement learning typically aggregates value functions or policies by parameter averaging, which emphasizes expected return and can obscure statistical multimodality and tail behavior that matter in safety-critical settings. We formalize federated distributional reinforcement learning (FedDistRL), where clients parametrize quantile value function critics and federate these networks only. We also propose TR-FedDistRL, which builds a per client, risk-aware Wasserstein barycenter over a temporal buffer. This local barycenter provides a reference region to constrain the parameter averaged critic, ensuring necessary distributional information is not averaged out during the federation process. The distributional trust region is implemented as a shrink-squash step around this reference. Under fixed-policy evaluation, the feasibility map is nonexpansive and the update is contractive in a probe-set Wasserstein metric under evaluation. Experiments on a bandit, multi-agent gridworld, and continuous highway environment show reduced mean-smearing, improved safety proxies (catastrophe/accident rate), and lower critic/policy drift versus mean-oriented and non-federated baselines.
Global Cross-Modal Geo-Localization: A Million-Scale Dataset and a Physical Consistency Learning Framework
Mar 09, 2026Cross-modal Geo-localization (CMGL) matches ground-level text descriptions with geo-tagged aerial imagery, which is crucial for pedestrian navigation and emergency response. However, existing researches are constrained by narrow geographic coverage and simplistic scene diversity, failing to reflect the immense spatial heterogeneity of global architectural styles and topographic features. To bridge this gap and facilitate universal positioning, we introduce CORE, the first million-scale dataset dedicated to global CMGL. CORE comprises 1,034,786 cross-view images sampled from 225 distinct geographic regions across all continents, offering an unprecedented variety of perspectives in varying environmental conditions and urban layouts. We leverage the zero-shot reasoning of Large Vision-Language Models (LVLMs) to synthesize high-quality scene descriptions rich in discriminative cues. Furthermore, we propose a physical-law-aware network (PLANET) for cross-modal geo-localization. PLANET introduces a novel contrastive learning paradigm to guide textual representations in capturing the intrinsic physical signatures of satellite imagery. Extensive experiments across varied geographic regions demonstrate that PLANet significantly outperforms state-of-the-art methods, establishing a new benchmark for robust, global-scale geo-localization. The dataset and source code will be released at https://github.com/YtH0823/CORE.
U-VLM: Hierarchical Vision Language Modeling for Report Generation
Feb 28, 2026Automated radiology report generation is key for reducing radiologist workload and improving diagnostic consistency, yet generating accurate reports for 3D medical imaging remains challenging. Existing vision-language models face two limitations: they do not leverage segmentation-pretrained encoders, and they inject visual features only at the input layer of language models, losing multi-scale information. We propose U-VLM, which enables hierarchical vision-language modeling in both training and architecture: (1) progressive training from segmentation to classification to report generation, and (2) multi-layer visual injection that routes U-Net encoder features to corresponding language model layers. Each training stage can leverage different datasets without unified annotations. U-VLM achieves state-of-the-art performance on CT-RATE (F1: 0.414 vs 0.258, BLEU-mean: 0.349 vs 0.305) and AbdomenAtlas 3.0 (F1: 0.624 vs 0.518 for segmentation-based detection) using only a 0.1B decoder trained from scratch, demonstrating that well-designed vision encoder pretraining outweighs the benefits of 7B+ pre-trained language models. Ablation studies show that progressive pretraining significantly improves F1, while multi-layer injection improves BLEU-mean. Code is available at https://github.com/yinghemedical/U-VLM.
Hierarchical Semantic Learning for Multi-Class Aorta Segmentation
Nov 18, 2025The aorta, the body's largest artery, is prone to pathologies such as dissection, aneurysm, and atherosclerosis, which often require timely intervention. Minimally invasive repairs involving branch vessels necessitate detailed 3D anatomical analysis. Existing methods often overlook hierarchical anatomical relationships while struggling with severe class imbalance inherent in vascular structures. We address these challenges with a curriculum learning strategy that leverages a novel fractal softmax for hierarchical semantic learning. Inspired by human cognition, our approach progressively learns anatomical constraints by decomposing complex structures from simple to complex components. The curriculum learning framework naturally addresses class imbalance by first establishing robust feature representations for dominant classes before tackling rare but anatomically critical structures, significantly accelerating model convergence in multi-class scenarios. Our two-stage inference strategy achieves up to fivefold acceleration, enhancing clinical practicality. On the validation set at epoch 50, our hierarchical semantic loss improves the Dice score of nnU-Net ResEnc M by 11.65%. The proposed model demonstrates a 5.6% higher Dice score than baselines on the test set. Experimental results show significant improvements in segmentation accuracy and efficiency, making the framework suitable for real-time clinical applications. The implementation code for this challenge entry is publicly available at: https://github.com/PengchengShi1220/AortaSeg24. The code for fractal softmax will be available at https://github.com/PengchengShi1220/fractal-softmax.
Medal S: Spatio-Textual Prompt Model for Medical Segmentation
Nov 17, 2025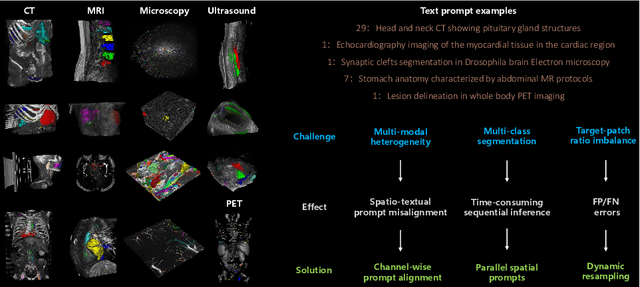
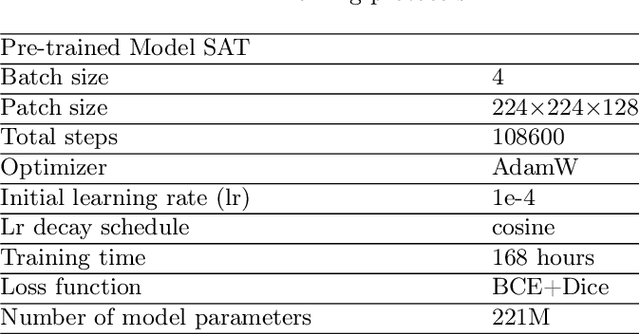
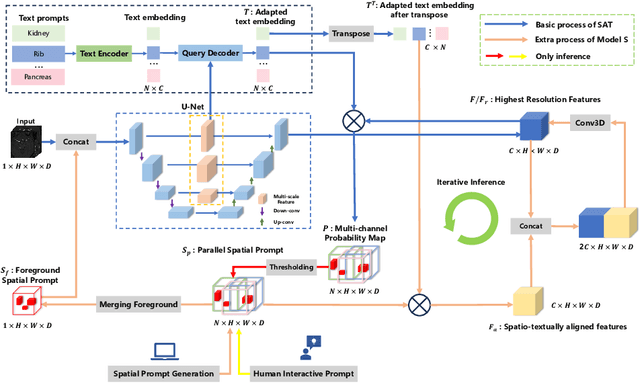
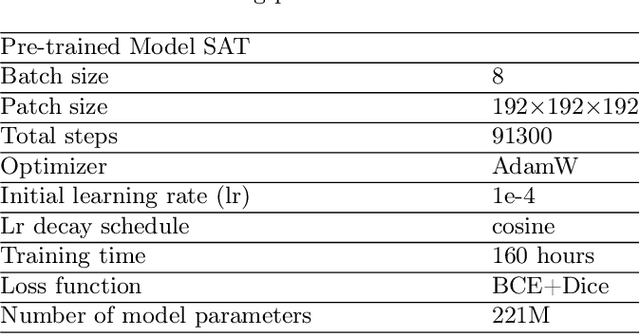
We introduce Medal S, a medical segmentation foundation model that supports native-resolution spatial and textual prompts within an end-to-end trainable framework. Unlike text-only methods lacking spatial awareness, Medal S achieves channel-wise alignment between volumetric prompts and text embeddings, mitigating inaccuracies from resolution mismatches. By preserving full 3D context, it efficiently processes multiple native-resolution masks in parallel, enhancing multi-class segmentation performance. A lightweight 3D convolutional module enables precise voxel-space refinement guided by both prompt types, supporting up to 243 classes across CT, MRI, PET, ultrasound, and microscopy modalities in the BiomedSegFM dataset. Medal S offers two prompting modes: a text-only mode, where model predictions serve as spatial prompts for self-refinement without human input, and a hybrid mode, incorporating manual annotations for enhanced flexibility. For 24-class segmentation, parallel spatial prompting reduces inference time by more than 90% compared to sequential prompting. We propose dynamic resampling to address target-patch ratio imbalance, extending SAT and nnU-Net for data augmentation. Furthermore, we develop optimized text preprocessing, a two-stage inference strategy, and post-processing techniques to improve memory efficiency, precision, and inference speed. On the five-modality average on the validation set, Medal S outperforms SAT with a DSC of 75.44 (vs. 69.83), NSD of 77.34 (vs. 71.06), F1 of 38.24 (vs. 24.88), and DSC TP of 65.46 (vs. 46.97). Medal S achieves excellent performance by harmonizing spatial precision with semantic textual guidance, demonstrating superior efficiency and accuracy in multi-class medical segmentation tasks compared to sequential prompt-based approaches. Medal S will be publicly available at https://github.com/yinghemedical/Medal-S.
TurboReg: TurboClique for Robust and Efficient Point Cloud Registration
Jul 02, 2025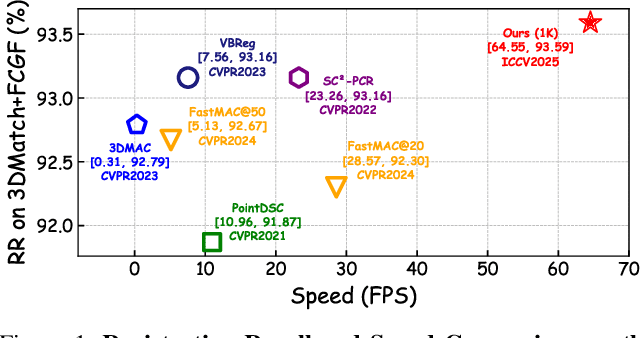
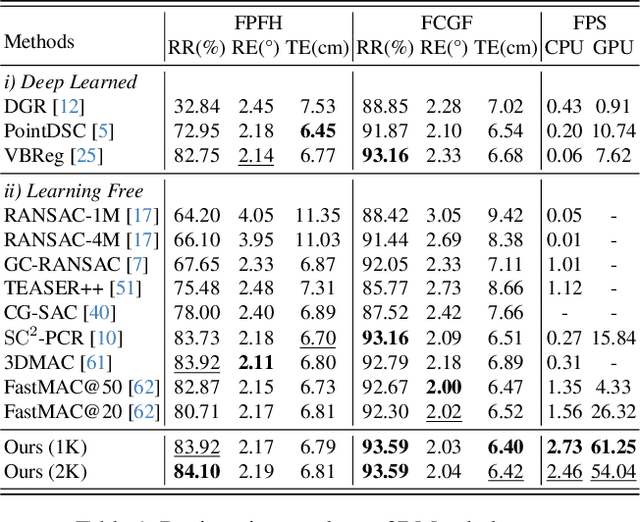


Robust estimation is essential in correspondence-based Point Cloud Registration (PCR). Existing methods using maximal clique search in compatibility graphs achieve high recall but suffer from exponential time complexity, limiting their use in time-sensitive applications. To address this challenge, we propose a fast and robust estimator, TurboReg, built upon a novel lightweight clique, TurboClique, and a highly parallelizable Pivot-Guided Search (PGS) algorithm. First, we define the TurboClique as a 3-clique within a highly-constrained compatibility graph. The lightweight nature of the 3-clique allows for efficient parallel searching, and the highly-constrained compatibility graph ensures robust spatial consistency for stable transformation estimation. Next, PGS selects matching pairs with high SC$^2$ scores as pivots, effectively guiding the search toward TurboCliques with higher inlier ratios. Moreover, the PGS algorithm has linear time complexity and is significantly more efficient than the maximal clique search with exponential time complexity. Extensive experiments show that TurboReg achieves state-of-the-art performance across multiple real-world datasets, with substantial speed improvements. For example, on the 3DMatch+FCGF dataset, TurboReg (1K) operates $208.22\times$ faster than 3DMAC while also achieving higher recall. Our code is accessible at \href{https://github.com/Laka-3DV/TurboReg}{\texttt{TurboReg}}.