 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePiLoT: Neural Pixel-to-3D Registration for UAV-based Ego and Target Geo-localization
Mar 21, 2026We present PiLoT, a unified framework that tackles UAV-based ego and target geo-localization. Conventional approaches rely on decoupled pipelines that fuse GNSS and Visual-Inertial Odometry (VIO) for ego-pose estimation, and active sensors like laser rangefinders for target localization. However, these methods are susceptible to failure in GNSS-denied environments and incur substantial hardware costs and complexity. PiLoT breaks this paradigm by directly registering live video stream against a geo-referenced 3D map. To achieve robust, accurate, and real-time performance, we introduce three key contributions: 1) a Dual-Thread Engine that decouples map rendering from core localization thread, ensuring both low latency while maintaining drift-free accuracy; 2) a large-scale synthetic dataset with precise geometric annotations (camera pose, depth maps). This dataset enables the training of a lightweight network that generalizes in a zero-shot manner from simulation to real data; and 3) a Joint Neural-Guided Stochastic-Gradient Optimizer (JNGO) that achieves robust convergence even under aggressive motion. Evaluations on a comprehensive set of public and newly collected benchmarks show that PiLoT outperforms state-of-the-art methods while running over 25 FPS on NVIDIA Jetson Orin platform. Our code and dataset is available at: https://github.com/Choyaa/PiLoT.
Beyond Motion Imitation: Is Human Motion Data Alone Sufficient to Explain Gait Control and Biomechanics?
Mar 12, 2026With the growing interest in motion imitation learning (IL) for human biomechanics and wearable robotics, this study investigates how additional foot-ground interaction measures, used as reward terms, affect human gait kinematics and kinetics estimation within a reinforcement learning-based IL framework. Results indicate that accurate reproduction of forward kinematics alone does not ensure biomechanically plausible joint kinetics. Adding foot-ground contacts and contact forces to the IL reward terms enables the prediction of joint moments in forward walking simulation, which are significantly closer to those computed by inverse dynamics. This finding highlights a fundamental limitation of motion-only IL approaches, which may prioritize kinematics matching over physical consistency. Incorporating kinetic constraints, particularly ground reaction force and center of pressure information, significantly enhances the realism of internal and external kinetics. These findings suggest that, when imitation learning is applied to human-related research domains such as biomechanics and wearable robot co-design, kinetics-based reward shaping is necessary to achieve physically consistent gait representations.
SkillsBench: Benchmarking How Well Agent Skills Work Across Diverse Tasks
Feb 13, 2026Agent Skills are structured packages of procedural knowledge that augment LLM agents at inference time. Despite rapid adoption, there is no standard way to measure whether they actually help. We present SkillsBench, a benchmark of 86 tasks across 11 domains paired with curated Skills and deterministic verifiers. Each task is evaluated under three conditions: no Skills, curated Skills, and self-generated Skills. We test 7 agent-model configurations over 7,308 trajectories. Curated Skills raise average pass rate by 16.2 percentage points(pp), but effects vary widely by domain (+4.5pp for Software Engineering to +51.9pp for Healthcare) and 16 of 84 tasks show negative deltas. Self-generated Skills provide no benefit on average, showing that models cannot reliably author the procedural knowledge they benefit from consuming. Focused Skills with 2--3 modules outperform comprehensive documentation, and smaller models with Skills can match larger models without them.
LAER-MoE: Load-Adaptive Expert Re-layout for Efficient Mixture-of-Experts Training
Feb 12, 2026Expert parallelism is vital for effectively training Mixture-of-Experts (MoE) models, enabling different devices to host distinct experts, with each device processing different input data. However, during expert parallel training, dynamic routing results in significant load imbalance among experts: a handful of overloaded experts hinder overall iteration, emerging as a training bottleneck. In this paper, we introduce LAER-MoE, an efficient MoE training framework. The core of LAER-MoE is a novel parallel paradigm, Fully Sharded Expert Parallel (FSEP), which fully partitions each expert parameter by the number of devices and restores partial experts at expert granularity through All-to-All communication during training. This allows for flexible re-layout of expert parameters during training to enhance load balancing. In particular, we perform fine-grained scheduling of communication operations to minimize communication overhead. Additionally, we develop a load balancing planner to formulate re-layout strategies of experts and routing schemes for tokens during training. We perform experiments on an A100 cluster, and the results indicate that our system achieves up to 1.69x acceleration compared to the current state-of-the-art training systems. Source code available at https://github.com/PKU-DAIR/Hetu-Galvatron/tree/laer-moe.
Graph-Augmented Reasoning with Large Language Models for Tobacco Pest and Disease Management
Feb 02, 2026This paper proposes a graph-augmented reasoning framework for tobacco pest and disease management that integrates structured domain knowledge into large language models. Building on GraphRAG, we construct a domain-specific knowledge graph and retrieve query-relevant subgraphs to provide relational evidence during answer generation. The framework adopts ChatGLM as the Transformer backbone with LoRA-based parameter-efficient fine-tuning, and employs a graph neural network to learn node representations that capture symptom-disease-treatment dependencies. By explicitly modeling diseases, symptoms, pesticides, and control measures as linked entities, the system supports evidence-aware retrieval beyond surface-level text similarity. Retrieved graph evidence is incorporated into the LLM input to guide generation toward domain-consistent recommendations and to mitigate hallucinated or inappropriate treatments. Experimental results show consistent improvements over text-only baselines, with the largest gains observed on multi-hop and comparative reasoning questions that require chaining multiple relations.
Scaling Laws of Machine Learning for Optimal Power Flow
Jan 06, 2026Optimal power flow (OPF) is one of the fundamental tasks for power system operations. While machine learning (ML) approaches such as deep neural networks (DNNs) have been widely studied to enhance OPF solution speed and performance, their practical deployment faces two critical scaling questions: What is the minimum training data volume required for reliable results? How should ML models' complexity balance accuracy with real-time computational limits? Existing studies evaluate discrete scenarios without quantifying these scaling relationships, leading to trial-and-error-based ML development in real-world applications. This work presents the first systematic scaling study for ML-based OPF across two dimensions: data scale (0.1K-40K training samples) and compute scale (multiple NN architectures with varying FLOPs). Our results reveal consistent power-law relationships on both DNNs and physics-informed NNs (PINNs) between each resource dimension and three core performance metrics: prediction error (MAE), constraint violations and speed. We find that for ACOPF, the accuracy metric scales with dataset size and training compute. These scaling laws enable predictable and principled ML pipeline design for OPF. We further identify the divergence between prediction accuracy and constraint feasibility and characterize the compute-optimal frontier. This work provides quantitative guidance for ML-OPF design and deployments.
Knowledge Reasoning of Large Language Models Integrating Graph-Structured Information for Pest and Disease Control in Tobacco
Dec 26, 2025This paper proposes a large language model (LLM) approach that integrates graph-structured information for knowledge reasoning in tobacco pest and disease control. Built upon the GraphRAG framework, the proposed method enhances knowledge retrieval and reasoning by explicitly incorporating structured information from a domain-specific knowledge graph. Specifically, LLMs are first leveraged to assist in the construction of a tobacco pest and disease knowledge graph, which organizes key entities such as diseases, symptoms, control methods, and their relationships. Based on this graph, relevant knowledge is retrieved and integrated into the reasoning process to support accurate answer generation. The Transformer architecture is adopted as the core inference model, while a graph neural network (GNN) is employed to learn expressive node representations that capture both local and global relational information within the knowledge graph. A ChatGLM-based model serves as the backbone LLM and is fine-tuned using LoRA to achieve parameter-efficient adaptation. Extensive experimental results demonstrate that the proposed approach consistently outperforms baseline methods across multiple evaluation metrics, significantly improving both the accuracy and depth of reasoning, particularly in complex multi-hop and comparative reasoning scenarios.
Video-LMM Post-Training: A Deep Dive into Video Reasoning with Large Multimodal Models
Oct 06, 2025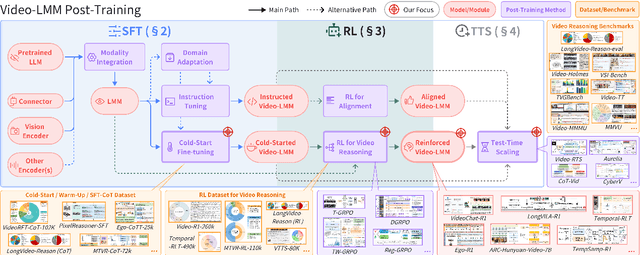
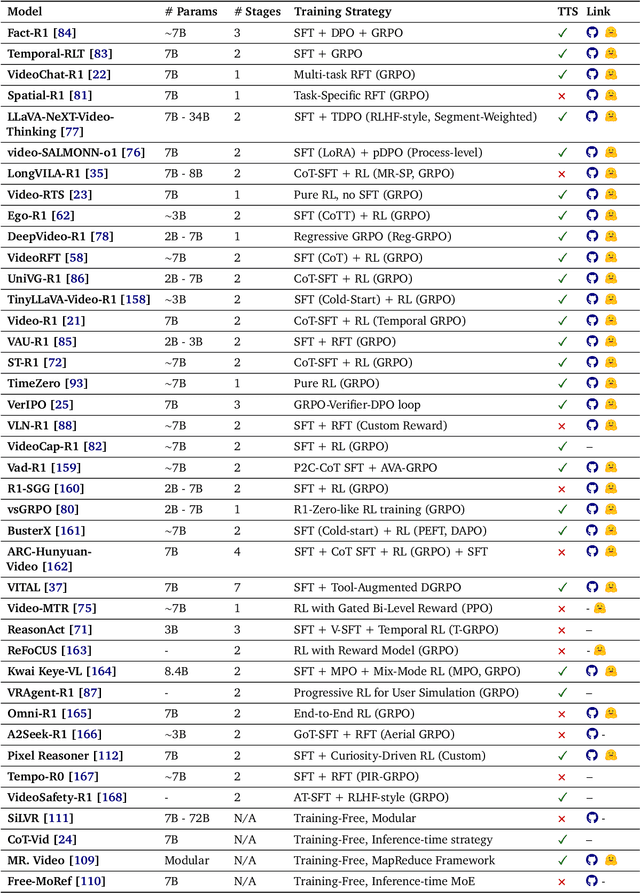
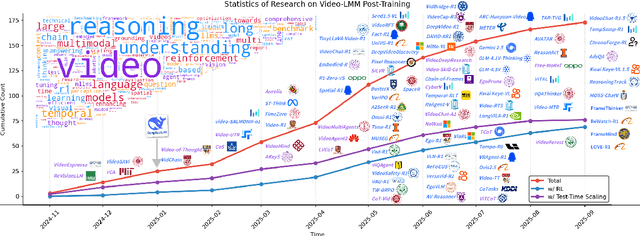
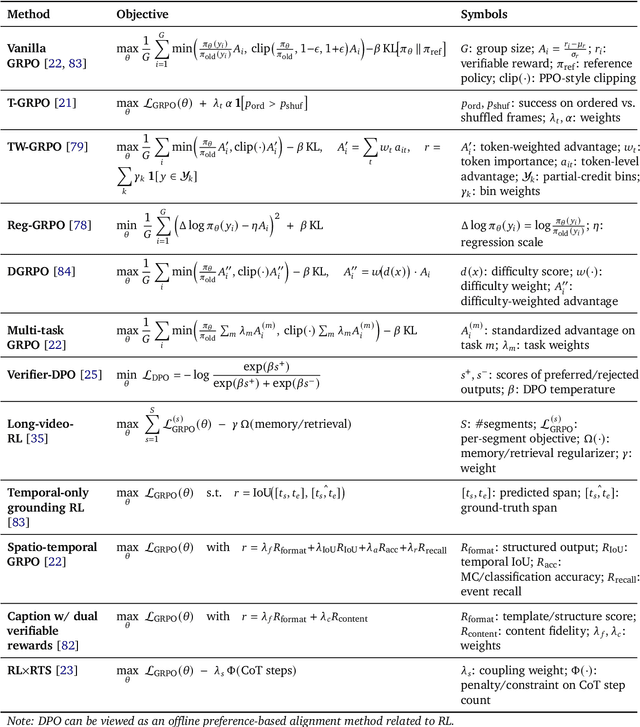
Video understanding represents the most challenging frontier in computer vision, requiring models to reason about complex spatiotemporal relationships, long-term dependencies, and multimodal evidence. The recent emergence of Video-Large Multimodal Models (Video-LMMs), which integrate visual encoders with powerful decoder-based language models, has demonstrated remarkable capabilities in video understanding tasks. However, the critical phase that transforms these models from basic perception systems into sophisticated reasoning engines, post-training, remains fragmented across the literature. This survey provides the first comprehensive examination of post-training methodologies for Video-LMMs, encompassing three fundamental pillars: supervised fine-tuning (SFT) with chain-of-thought, reinforcement learning (RL) from verifiable objectives, and test-time scaling (TTS) through enhanced inference computation. We present a structured taxonomy that clarifies the roles, interconnections, and video-specific adaptations of these techniques, addressing unique challenges such as temporal localization, spatiotemporal grounding, long video efficiency, and multimodal evidence integration. Through systematic analysis of representative methods, we synthesize key design principles, insights, and evaluation protocols while identifying critical open challenges in reward design, scalability, and cost-performance optimization. We further curate essential benchmarks, datasets, and metrics to facilitate rigorous assessment of post-training effectiveness. This survey aims to provide researchers and practitioners with a unified framework for advancing Video-LMM capabilities. Additional resources and updates are maintained at: https://github.com/yunlong10/Awesome-Video-LMM-Post-Training
CasP: Improving Semi-Dense Feature Matching Pipeline Leveraging Cascaded Correspondence Priors for Guidance
Jul 23, 2025Semi-dense feature matching methods have shown strong performance in challenging scenarios. However, the existing pipeline relies on a global search across the entire feature map to establish coarse matches, limiting further improvements in accuracy and efficiency. Motivated by this limitation, we propose a novel pipeline, CasP, which leverages cascaded correspondence priors for guidance. Specifically, the matching stage is decomposed into two progressive phases, bridged by a region-based selective cross-attention mechanism designed to enhance feature discriminability. In the second phase, one-to-one matches are determined by restricting the search range to the one-to-many prior areas identified in the first phase. Additionally, this pipeline benefits from incorporating high-level features, which helps reduce the computational costs of low-level feature extraction. The acceleration gains of CasP increase with higher resolution, and our lite model achieves a speedup of $\sim2.2\times$ at a resolution of 1152 compared to the most efficient method, ELoFTR. Furthermore, extensive experiments demonstrate its superiority in geometric estimation, particularly with impressive cross-domain generalization. These advantages highlight its potential for latency-sensitive and high-robustness applications, such as SLAM and UAV systems. Code is available at https://github.com/pq-chen/CasP.
DocCHA: Towards LLM-Augmented Interactive Online diagnosis System
Jul 10, 2025Despite the impressive capabilities of Large Language Models (LLMs), existing Conversational Health Agents (CHAs) remain static and brittle, incapable of adaptive multi-turn reasoning, symptom clarification, or transparent decision-making. This hinders their real-world applicability in clinical diagnosis, where iterative and structured dialogue is essential. We propose DocCHA, a confidence-aware, modular framework that emulates clinical reasoning by decomposing the diagnostic process into three stages: (1) symptom elicitation, (2) history acquisition, and (3) causal graph construction. Each module uses interpretable confidence scores to guide adaptive questioning, prioritize informative clarifications, and refine weak reasoning links. Evaluated on two real-world Chinese consultation datasets (IMCS21, DX), DocCHA consistently outperforms strong prompting-based LLM baselines (GPT-3.5, GPT-4o, LLaMA-3), achieving up to 5.18 percent higher diagnostic accuracy and over 30 percent improvement in symptom recall, with only modest increase in dialogue turns. These results demonstrate the effectiveness of DocCHA in enabling structured, transparent, and efficient diagnostic conversations -- paving the way for trustworthy LLM-powered clinical assistants in multilingual and resource-constrained settings.