 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian-LoRA: Probabilistic Low-Rank Adaptation of Large Language Models
Jan 28, 2026Large Language Models usually put more emphasis on accuracy and therefore, will guess even when not certain about the prediction, which is especially severe when fine-tuned on small datasets due to the inherent tendency toward miscalibration. In this work, we introduce Bayesian-LoRA, which reformulates the deterministic LoRA update as a probabilistic low-rank representation inspired by Sparse Gaussian Processes. We identify a structural isomorphism between LoRA's factorization and Kronecker-factored SGP posteriors, and show that LoRA emerges as a limiting case when posterior uncertainty collapses. We conduct extensive experiments on various LLM architectures across commonsense reasoning benchmarks. With only approximately 0.42M additional parameters and ${\approx}1.2{\times}$ training cost relative to standard LoRA, Bayesian-LoRA significantly improves calibration across models up to 30B, achieving up to 84% ECE reduction and 76% NLL reduction while maintaining competitive accuracy for both in-distribution and out-of-distribution (OoD) evaluations.
EvoFSM: Controllable Self-Evolution for Deep Research with Finite State Machines
Jan 14, 2026While LLM-based agents have shown promise for deep research, most existing approaches rely on fixed workflows that struggle to adapt to real-world, open-ended queries. Recent work therefore explores self-evolution by allowing agents to rewrite their own code or prompts to improve problem-solving ability, but unconstrained optimization often triggers instability, hallucinations, and instruction drift. We propose EvoFSM, a structured self-evolving framework that achieves both adaptability and control by evolving an explicit Finite State Machine (FSM) instead of relying on free-form rewriting. EvoFSM decouples the optimization space into macroscopic Flow (state-transition logic) and microscopic Skill (state-specific behaviors), enabling targeted improvements under clear behavioral boundaries. Guided by a critic mechanism, EvoFSM refines the FSM through a small set of constrained operations, and further incorporates a self-evolving memory that distills successful trajectories as reusable priors and failure patterns as constraints for future queries. Extensive evaluations on five multi-hop QA benchmarks demonstrate the effectiveness of EvoFSM. In particular, EvoFSM reaches 58.0% accuracy on the DeepSearch benchmark. Additional results on interactive decision-making tasks further validate its generalization.
$λ$-GRPO: Unifying the GRPO Frameworks with Learnable Token Preferences
Oct 08, 2025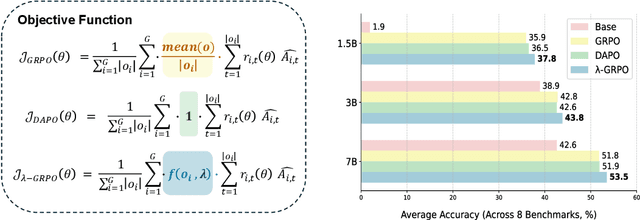
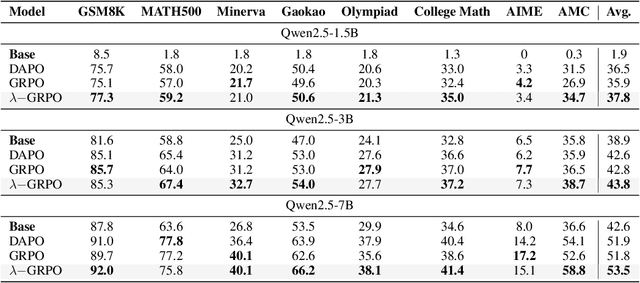
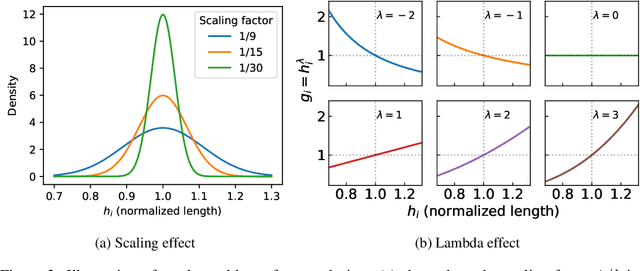

Reinforcement Learning with Human Feedback (RLHF) has been the dominant approach for improving the reasoning capabilities of Large Language Models (LLMs). Recently, Reinforcement Learning with Verifiable Rewards (RLVR) has simplified this paradigm by replacing the reward and value models with rule-based verifiers. A prominent example is Group Relative Policy Optimization (GRPO). However, GRPO inherently suffers from a length bias, since the same advantage is uniformly assigned to all tokens of a response. As a result, longer responses distribute the reward over more tokens and thus contribute disproportionately to gradient updates. Several variants, such as DAPO and Dr. GRPO, modify the token-level aggregation of the loss, yet these methods remain heuristic and offer limited interpretability regarding their implicit token preferences. In this work, we explore the possibility of allowing the model to learn its own token preference during optimization. We unify existing frameworks under a single formulation and introduce a learnable parameter $\lambda$ that adaptively controls token-level weighting. We use $\lambda$-GRPO to denote our method, and we find that $\lambda$-GRPO achieves consistent improvements over vanilla GRPO and DAPO on multiple mathematical reasoning benchmarks. On Qwen2.5 models with 1.5B, 3B, and 7B parameters, $\lambda$-GRPO improves average accuracy by $+1.9\%$, $+1.0\%$, and $+1.7\%$ compared to GRPO, respectively. Importantly, these gains come without any modifications to the training data or additional computational cost, highlighting the effectiveness and practicality of learning token preferences.
DCR: Quantifying Data Contamination in LLMs Evaluation
Jul 15, 2025The rapid advancement of large language models (LLMs) has heightened concerns about benchmark data contamination (BDC), where models inadvertently memorize evaluation data, inflating performance metrics and undermining genuine generalization assessment. This paper introduces the Data Contamination Risk (DCR) framework, a lightweight, interpretable pipeline designed to detect and quantify BDC across four granular levels: semantic, informational, data, and label. By synthesizing contamination scores via a fuzzy inference system, DCR produces a unified DCR Factor that adjusts raw accuracy to reflect contamination-aware performance. Validated on 9 LLMs (0.5B-72B) across sentiment analysis, fake news detection, and arithmetic reasoning tasks, the DCR framework reliably diagnoses contamination severity and with accuracy adjusted using the DCR Factor to within 4% average error across the three benchmarks compared to the uncontaminated baseline. Emphasizing computational efficiency and transparency, DCR provides a practical tool for integrating contamination assessment into routine evaluations, fostering fairer comparisons and enhancing the credibility of LLM benchmarking practices.
PreP-OCR: A Complete Pipeline for Document Image Restoration and Enhanced OCR Accuracy
May 28, 2025This paper introduces PreP-OCR, a two-stage pipeline that combines document image restoration with semantic-aware post-OCR correction to enhance both visual clarity and textual consistency, thereby improving text extraction from degraded historical documents. First, we synthesize document-image pairs from plaintext, rendering them with diverse fonts and layouts and then applying a randomly ordered set of degradation operations. An image restoration model is trained on this synthetic data, using multi-directional patch extraction and fusion to process large images. Second, a ByT5 post-OCR model, fine-tuned on synthetic historical text pairs, addresses remaining OCR errors. Detailed experiments on 13,831 pages of real historical documents in English, French, and Spanish show that the PreP-OCR pipeline reduces character error rates by 63.9-70.3% compared to OCR on raw images. Our pipeline demonstrates the potential of integrating image restoration with linguistic error correction for digitizing historical archives.
UORA: Uniform Orthogonal Reinitialization Adaptation in Parameter-Efficient Fine-Tuning of Large Models
May 26, 2025This paper introduces Uniform Orthogonal Reinitialization Adaptation (UORA), a novel parameter-efficient fine-tuning (PEFT) approach for Large Language Models (LLMs). UORA achieves state-of-the-art performance and parameter efficiency by leveraging a low-rank approximation method to reduce the number of trainable parameters. Unlike existing methods such as LoRA and VeRA, UORA employs an interpolation-based reparametrization mechanism that selectively reinitializes rows and columns in frozen projection matrices, guided by the vector magnitude heuristic. This results in substantially fewer trainable parameters compared to LoRA and outperforms VeRA in computation and storage efficiency. Comprehensive experiments across various benchmarks demonstrate UORA's superiority in achieving competitive fine-tuning performance with negligible computational overhead. We demonstrate its performance on GLUE and E2E benchmarks and its effectiveness in instruction-tuning large language models and image classification models. Our contributions establish a new paradigm for scalable and resource-efficient fine-tuning of LLMs.
* 20 pages, 2 figures, 15 tables
Stochastic Weight Sharing for Bayesian Neural Networks
May 23, 2025While offering a principled framework for uncertainty quantification in deep learning, the employment of Bayesian Neural Networks (BNNs) is still constrained by their increased computational requirements and the convergence difficulties when training very deep, state-of-the-art architectures. In this work, we reinterpret weight-sharing quantization techniques from a stochastic perspective in the context of training and inference with Bayesian Neural Networks (BNNs). Specifically, we leverage 2D adaptive Gaussian distributions, Wasserstein distance estimations, and alpha blending to encode the stochastic behaviour of a BNN in a lower dimensional, soft Gaussian representation. Through extensive empirical investigation, we demonstrate that our approach significantly reduces the computational overhead inherent in Bayesian learning by several orders of magnitude, enabling the efficient Bayesian training of large-scale models, such as ResNet-101 and Vision Transformer (VIT). On various computer vision benchmarks including CIFAR10, CIFAR100, and ImageNet1k. Our approach compresses model parameters by approximately 50x and reduces model size by 75, while achieving accuracy and uncertainty estimations comparable to the state-of-the-art.
Advancing Post-OCR Correction: A Comparative Study of Synthetic Data
Aug 05, 2024This paper explores the application of synthetic data in the post-OCR domain on multiple fronts by conducting experiments to assess the impact of data volume, augmentation, and synthetic data generation methods on model performance. Furthermore, we introduce a novel algorithm that leverages computer vision feature detection algorithms to calculate glyph similarity for constructing post-OCR synthetic data. Through experiments conducted across a variety of languages, including several low-resource ones, we demonstrate that models like ByT5 can significantly reduce Character Error Rates (CER) without the need for manually annotated data, and our proposed synthetic data generation method shows advantages over traditional methods, particularly in low-resource languages.
Benchmark Data Contamination of Large Language Models: A Survey
Jun 06, 2024The rapid development of Large Language Models (LLMs) like GPT-4, Claude-3, and Gemini has transformed the field of natural language processing. However, it has also resulted in a significant issue known as Benchmark Data Contamination (BDC). This occurs when language models inadvertently incorporate evaluation benchmark information from their training data, leading to inaccurate or unreliable performance during the evaluation phase of the process. This paper reviews the complex challenge of BDC in LLM evaluation and explores alternative assessment methods to mitigate the risks associated with traditional benchmarks. The paper also examines challenges and future directions in mitigating BDC risks, highlighting the complexity of the issue and the need for innovative solutions to ensure the reliability of LLM evaluation in real-world applications.