 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiveFact: A Dynamic, Time-Aware Benchmark for LLM-Driven Fake News Detection
Apr 06, 2026The rapid development of Large Language Models (LLMs) has transformed fake news detection and fact-checking tasks from simple classification to complex reasoning. However, evaluation frameworks have not kept pace. Current benchmarks are static, making them vulnerable to benchmark data contamination (BDC) and ineffective at assessing reasoning under temporal uncertainty. To address this, we introduce LiveFact a continuously updated benchmark that simulates the real-world "fog of war" in misinformation detection. LiveFact uses dynamic, temporal evidence sets to evaluate models on their ability to reason with evolving, incomplete information rather than on memorized knowledge. We propose a dual-mode evaluation: Classification Mode for final verification and Inference Mode for evidence-based reasoning, along with a component to monitor BDC explicitly. Tests with 22 LLMs show that open-source Mixture-of-Experts models, such as Qwen3-235B-A22B, now match or outperform proprietary state-of-the-art systems. More importantly, our analysis finds a significant "reasoning gap." Capable models exhibit epistemic humility by recognizing unverifiable claims in early data slices-an aspect traditional static benchmarks overlook. LiveFact sets a sustainable standard for evaluating robust, temporally aware AI verification.
DCR: Quantifying Data Contamination in LLMs Evaluation
Jul 15, 2025The rapid advancement of large language models (LLMs) has heightened concerns about benchmark data contamination (BDC), where models inadvertently memorize evaluation data, inflating performance metrics and undermining genuine generalization assessment. This paper introduces the Data Contamination Risk (DCR) framework, a lightweight, interpretable pipeline designed to detect and quantify BDC across four granular levels: semantic, informational, data, and label. By synthesizing contamination scores via a fuzzy inference system, DCR produces a unified DCR Factor that adjusts raw accuracy to reflect contamination-aware performance. Validated on 9 LLMs (0.5B-72B) across sentiment analysis, fake news detection, and arithmetic reasoning tasks, the DCR framework reliably diagnoses contamination severity and with accuracy adjusted using the DCR Factor to within 4% average error across the three benchmarks compared to the uncontaminated baseline. Emphasizing computational efficiency and transparency, DCR provides a practical tool for integrating contamination assessment into routine evaluations, fostering fairer comparisons and enhancing the credibility of LLM benchmarking practices.
Benchmark Data Contamination of Large Language Models: A Survey
Jun 06, 2024The rapid development of Large Language Models (LLMs) like GPT-4, Claude-3, and Gemini has transformed the field of natural language processing. However, it has also resulted in a significant issue known as Benchmark Data Contamination (BDC). This occurs when language models inadvertently incorporate evaluation benchmark information from their training data, leading to inaccurate or unreliable performance during the evaluation phase of the process. This paper reviews the complex challenge of BDC in LLM evaluation and explores alternative assessment methods to mitigate the risks associated with traditional benchmarks. The paper also examines challenges and future directions in mitigating BDC risks, highlighting the complexity of the issue and the need for innovative solutions to ensure the reliability of LLM evaluation in real-world applications.
Structural Textile Pattern Recognition and Processing Based on Hypergraphs
Mar 21, 2021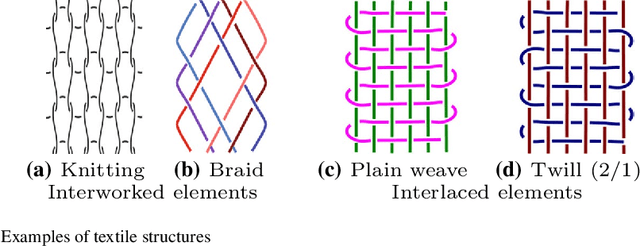
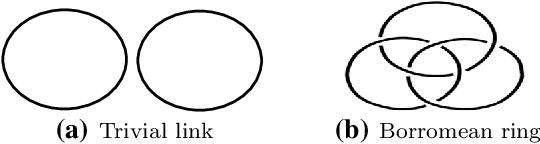


The humanities, like many other areas of society, are currently undergoing major changes in the wake of digital transformation. However, in order to make collection of digitised material in this area easily accessible, we often still lack adequate search functionality. For instance, digital archives for textiles offer keyword search, which is fairly well understood, and arrange their content following a certain taxonomy, but search functionality at the level of thread structure is still missing. To facilitate the clustering and search, we introduce an approach for recognising similar weaving patterns based on their structures for textile archives. We first represent textile structures using hypergraphs and extract multisets of k-neighbourhoods describing weaving patterns from these graphs. Then, the resulting multisets are clustered using various distance measures and various clustering algorithms (K-Means for simplicity and hierarchical agglomerative algorithms for precision). We evaluate the different variants of our approach experimentally, showing that this can be implemented efficiently (meaning it has linear complexity), and demonstrate its quality to query and cluster datasets containing large textile samples. As, to the est of our knowledge, this is the first practical approach for explicitly modelling complex and irregular weaving patterns usable for retrieval, we aim at establishing a solid baseline.
* 38 pages, 23 figures
Crop Knowledge Discovery Based on Agricultural Big Data Integration
Mar 11, 2020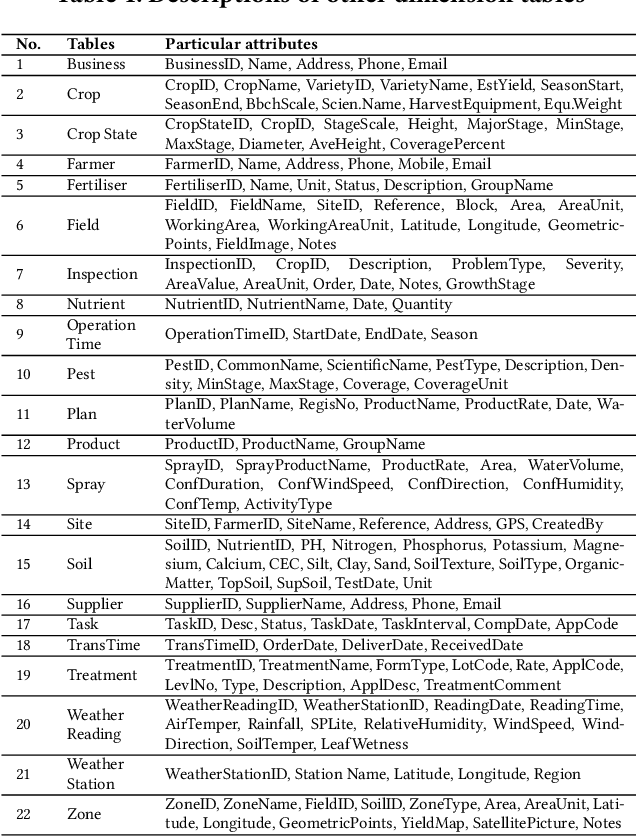
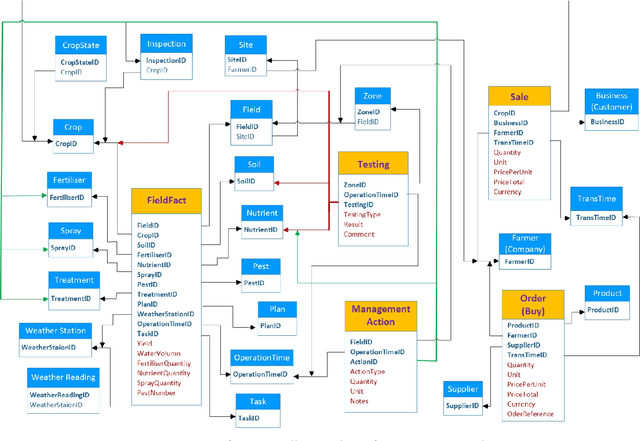
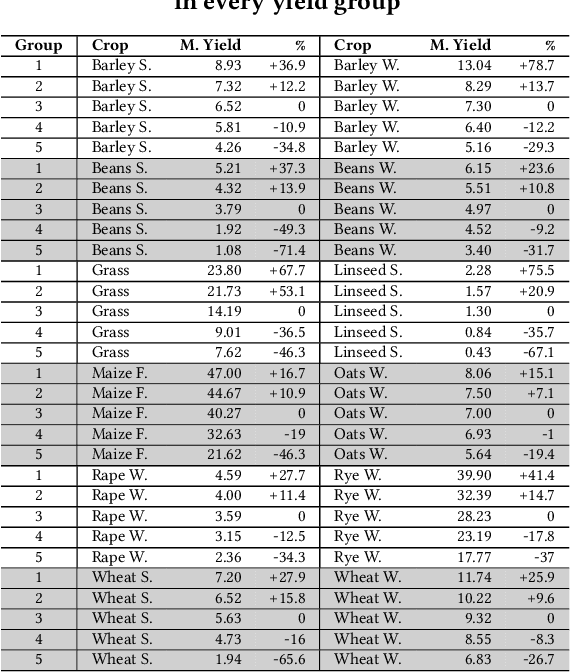
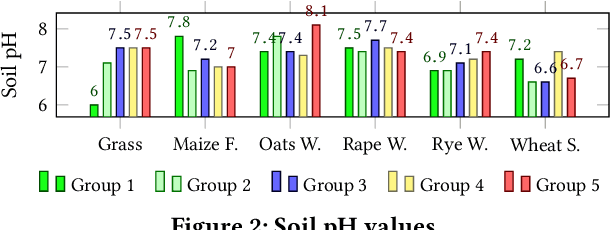
Nowadays, the agricultural data can be generated through various sources, such as: Internet of Thing (IoT), sensors, satellites, weather stations, robots, farm equipment, agricultural laboratories, farmers, government agencies and agribusinesses. The analysis of this big data enables farmers, companies and agronomists to extract high business and scientific knowledge, improving their operational processes and product quality. However, before analysing this data, different data sources need to be normalised, homogenised and integrated into a unified data representation. In this paper, we propose an agricultural data integration method using a constellation schema which is designed to be flexible enough to incorporate other datasets and big data models. We also apply some methods to extract knowledge with the view to improve crop yield; these include finding suitable quantities of soil properties, herbicides and insecticides for both increasing crop yield and protecting the environment.
* 5 pages
Knowledge Map: Toward a New Approach Supporting the Knowledge Management in Distributed Data Mining
Oct 23, 2019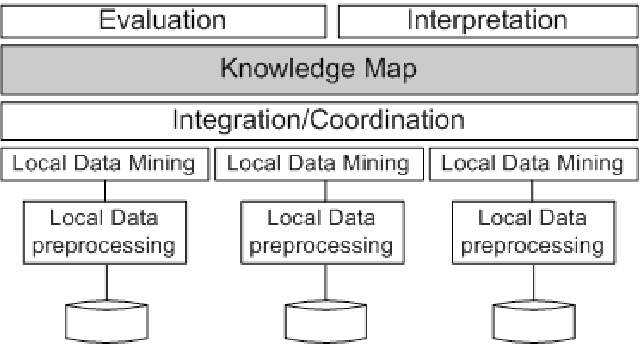
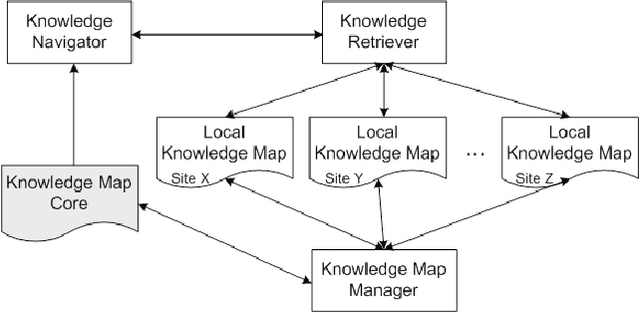
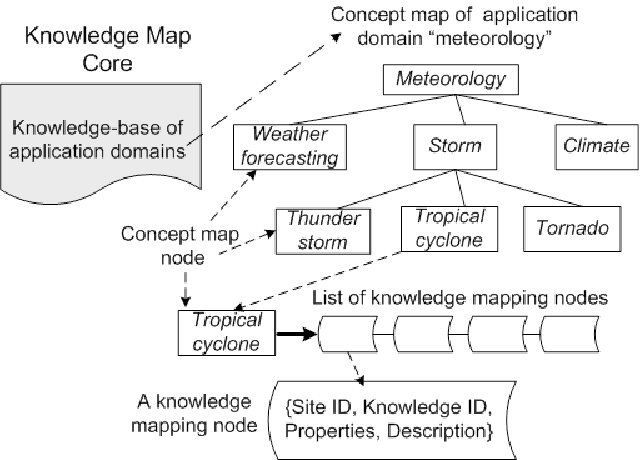
Distributed data mining (DDM) deals with the problem of finding patterns or models, called knowledge, in an environment with distributed data and computations. Today, a massive amounts of data which are often geographically distributed and owned by different organisation are being mined. As consequence, a large mount of knowledge are being produced. This causes problems of not only knowledge management but also visualization in data mining. Besides, the main aim of DDM is to exploit fully the benefit of distributed data analysis while minimising the communication. Existing DDM techniques perform partial analysis of local data at individual sites and then generate a global model by aggregating these local results. These two steps are not independent since naive approaches to local analysis may produce an incorrect and ambiguous global data model. The integrating and cooperating of these two steps need an effective knowledge management, concretely an efficient map of knowledge in order to take the advantage of mined knowledge to guide mining the data. In this paper, we present "knowledge map", a representation of knowledge about mined knowledge. This new approach aims to manage efficiently mined knowledge in large scale distributed platform such as Grid. This knowledge map is used to facilitate not only the visualization, evaluation of mining results but also the coordinating of local mining process and existing knowledge to increase the accuracy of final model.
Recurrent neural network approach for cyclic job shop scheduling problem
Oct 21, 2019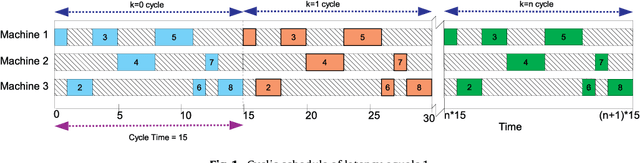

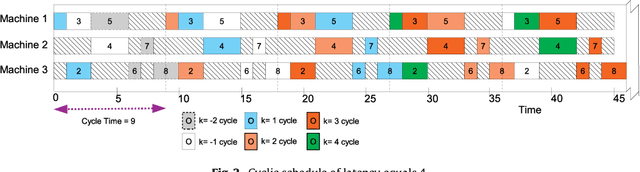
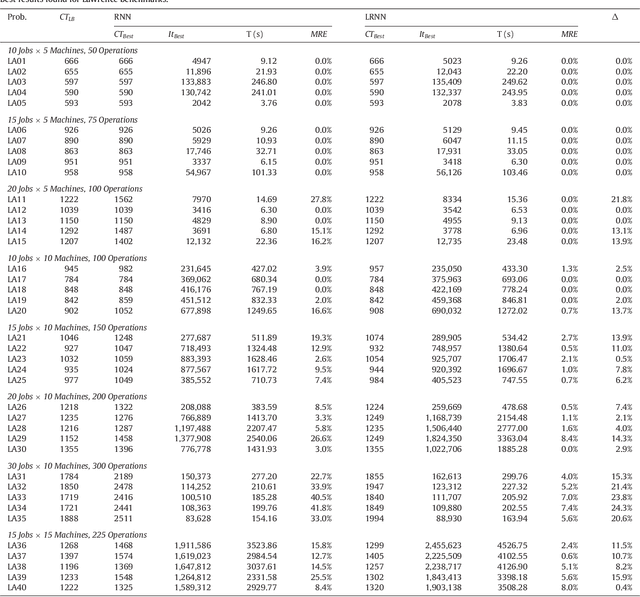
While cyclic scheduling is involved in numerous real-world applications, solving the derived problem is still of exponential complexity. This paper focuses specifically on modelling the manufacturing application as a cyclic job shop problem and we have developed an efficient neural network approach to minimise the cycle time of a schedule. Our approach introduces an interesting model for a manufacturing production, and it is also very efficient, adaptive and flexible enough to work with other techniques. Experimental results validated the approach and confirmed our hypotheses about the system model and the efficiency of neural networks for such a class of problems.
Designing and Implementing Data Warehouse for Agricultural Big Data
May 29, 2019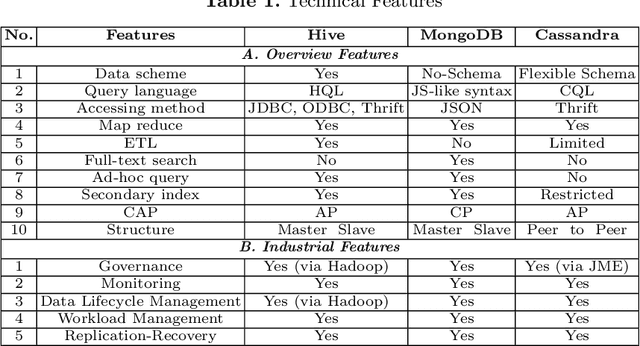
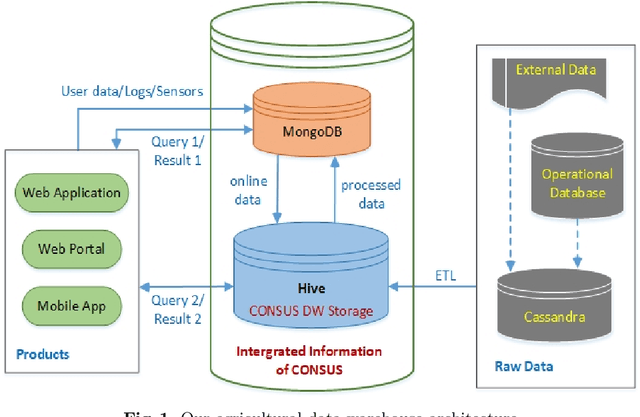
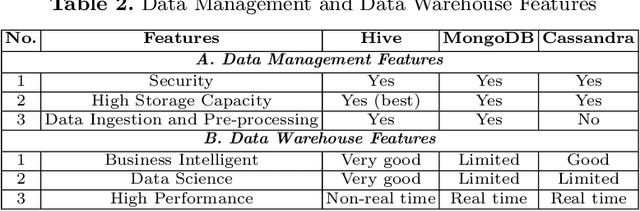
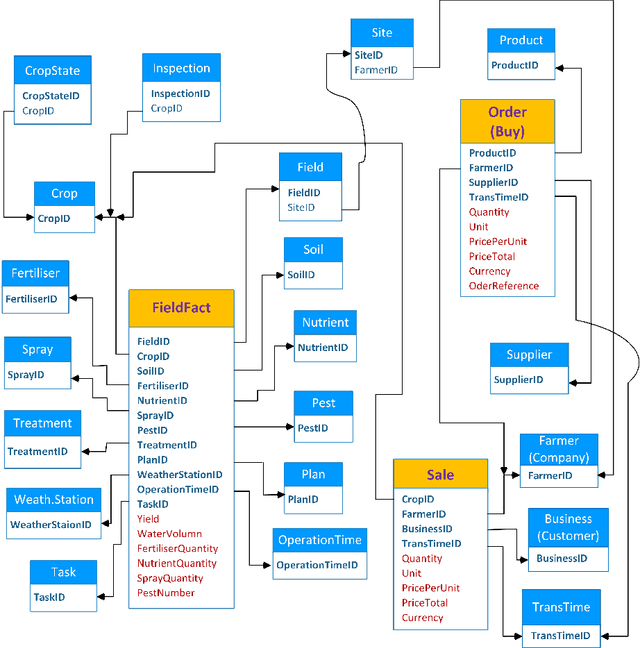
In recent years, precision agriculture that uses modern information and communication technologies is becoming very popular. Raw and semi-processed agricultural data are usually collected through various sources, such as: Internet of Thing (IoT), sensors, satellites, weather stations, robots, farm equipment, farmers and agribusinesses, etc. Besides, agricultural datasets are very large, complex, unstructured, heterogeneous, non-standardized, and inconsistent. Hence, the agricultural data mining is considered as Big Data application in terms of volume, variety, velocity and veracity. It is a key foundation to establishing a crop intelligence platform, which will enable resource efficient agronomy decision making and recommendations. In this paper, we designed and implemented a continental level agricultural data warehouse by combining Hive, MongoDB and Cassandra. Our data warehouse capabilities: (1) flexible schema; (2) data integration from real agricultural multi datasets; (3) data science and business intelligent support; (4) high performance; (5) high storage; (6) security; (7) governance and monitoring; (8) replication and recovery; (9) consistency, availability and partition tolerant; (10) distributed and cloud deployment. We also evaluate the performance of our data warehouse.
* Business intelligent, data warehouse, constellation schema, Big Data, precision agriculture
Efficient Large Scale Clustering based on Data Partitioning
Feb 26, 2018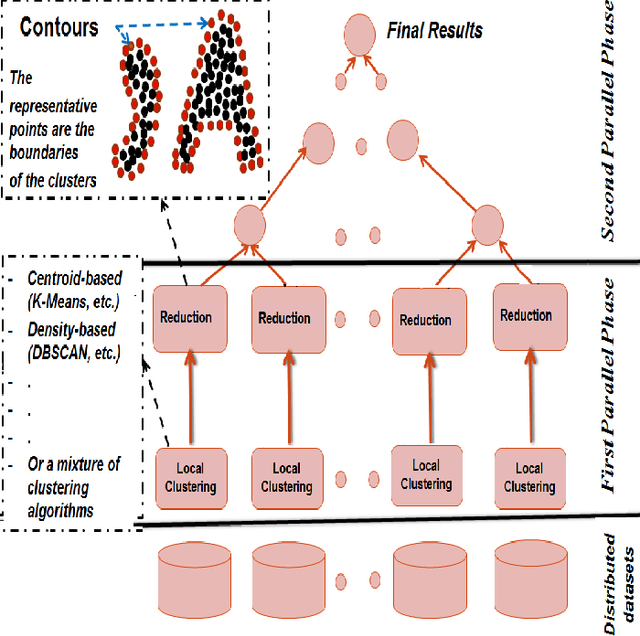



Clustering techniques are very attractive for extracting and identifying patterns in datasets. However, their application to very large spatial datasets presents numerous challenges such as high-dimensionality data, heterogeneity, and high complexity of some algorithms. For instance, some algorithms may have linear complexity but they require the domain knowledge in order to determine their input parameters. Distributed clustering techniques constitute a very good alternative to the big data challenges (e.g.,Volume, Variety, Veracity, and Velocity). Usually these techniques consist of two phases. The first phase generates local models or patterns and the second one tends to aggregate the local results to obtain global models. While the first phase can be executed in parallel on each site and, therefore, efficient, the aggregation phase is complex, time consuming and may produce incorrect and ambiguous global clusters and therefore incorrect models. In this paper we propose a new distributed clustering approach to deal efficiently with both phases, generation of local results and generation of global models by aggregation. For the first phase, our approach is capable of analysing the datasets located in each site using different clustering techniques. The aggregation phase is designed in such a way that the final clusters are compact and accurate while the overall process is efficient in time and memory allocation. For the evaluation, we use two well-known clustering algorithms, K-Means and DBSCAN. One of the key outputs of this distributed clustering technique is that the number of global clusters is dynamic, no need to be fixed in advance. Experimental results show that the approach is scalable and produces high quality results.
* 10 pages
Hierarchical Aggregation Approach for Distributed clustering of spatial datasets
Feb 01, 2018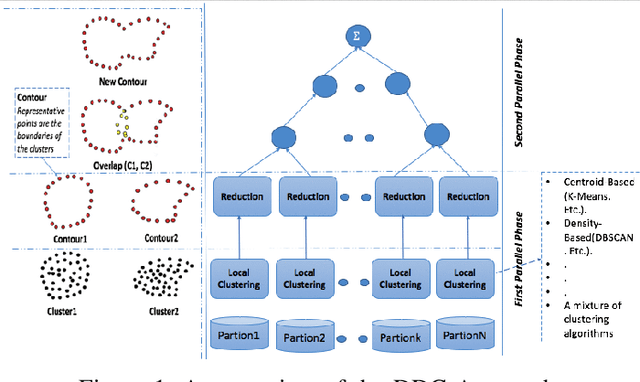
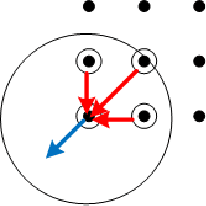
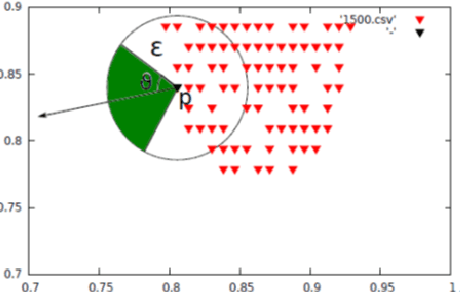
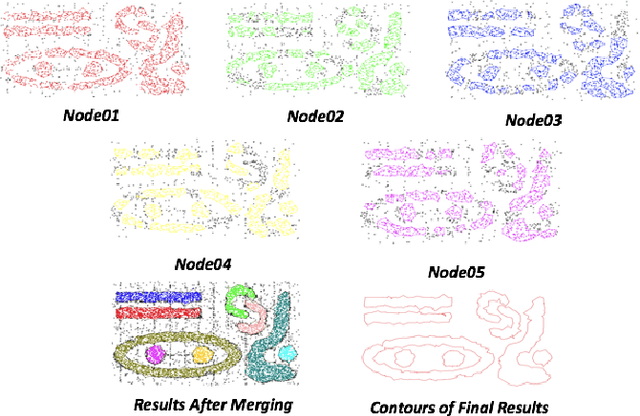
In this paper, we present a new approach of distributed clustering for spatial datasets, based on an innovative and efficient aggregation technique. This distributed approach consists of two phases: 1) local clustering phase, where each node performs a clustering on its local data, 2) aggregation phase, where the local clusters are aggregated to produce global clusters. This approach is characterised by the fact that the local clusters are represented in a simple and efficient way. And The aggregation phase is designed in such a way that the final clusters are compact and accurate while the overall process is efficient in both response time and memory allocation. We evaluated the approach with different datasets and compared it to well-known clustering techniques. The experimental results show that our approach is very promising and outperforms all those algorithms