 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Large Scale Clustering based on Data Partitioning
Paper and Code
Feb 26, 2018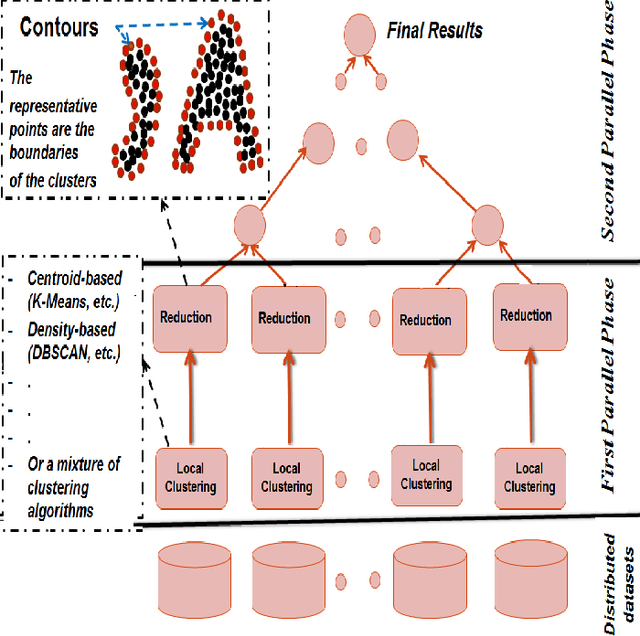



Clustering techniques are very attractive for extracting and identifying patterns in datasets. However, their application to very large spatial datasets presents numerous challenges such as high-dimensionality data, heterogeneity, and high complexity of some algorithms. For instance, some algorithms may have linear complexity but they require the domain knowledge in order to determine their input parameters. Distributed clustering techniques constitute a very good alternative to the big data challenges (e.g.,Volume, Variety, Veracity, and Velocity). Usually these techniques consist of two phases. The first phase generates local models or patterns and the second one tends to aggregate the local results to obtain global models. While the first phase can be executed in parallel on each site and, therefore, efficient, the aggregation phase is complex, time consuming and may produce incorrect and ambiguous global clusters and therefore incorrect models. In this paper we propose a new distributed clustering approach to deal efficiently with both phases, generation of local results and generation of global models by aggregation. For the first phase, our approach is capable of analysing the datasets located in each site using different clustering techniques. The aggregation phase is designed in such a way that the final clusters are compact and accurate while the overall process is efficient in time and memory allocation. For the evaluation, we use two well-known clustering algorithms, K-Means and DBSCAN. One of the key outputs of this distributed clustering technique is that the number of global clusters is dynamic, no need to be fixed in advance. Experimental results show that the approach is scalable and produces high quality results.