 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSaliency-Based diversity and fairness Metric and FaceKeepOriginalAugment: A Novel Approach for Enhancing Fairness and Diversity
Oct 29, 2024



Data augmentation has become a pivotal tool in enhancing the performance of computer vision tasks, with the KeepOriginalAugment method emerging as a standout technique for its intelligent incorporation of salient regions within less prominent areas, enabling augmentation in both regions. Despite its success in image classification, its potential in addressing biases remains unexplored. In this study, we introduce an extension of the KeepOriginalAugment method, termed FaceKeepOriginalAugment, which explores various debiasing aspects-geographical, gender, and stereotypical biases-in computer vision models. By maintaining a delicate balance between data diversity and information preservation, our approach empowers models to exploit both diverse salient and non-salient regions, thereby fostering increased diversity and debiasing effects. We investigate multiple strategies for determining the placement of the salient region and swapping perspectives to decide which part undergoes augmentation. Leveraging the Image Similarity Score (ISS), we quantify dataset diversity across a range of datasets, including Flickr Faces HQ (FFHQ), WIKI, IMDB, Labelled Faces in the Wild (LFW), UTK Faces, and Diverse Dataset. We evaluate the effectiveness of FaceKeepOriginalAugment in mitigating gender bias across CEO, Engineer, Nurse, and School Teacher datasets, utilizing the Image-Image Association Score (IIAS) in convolutional neural networks (CNNs) and vision transformers (ViTs). Our findings shows the efficacy of FaceKeepOriginalAugment in promoting fairness and inclusivity within computer vision models, demonstrated by reduced gender bias and enhanced overall fairness. Additionally, we introduce a novel metric, Saliency-Based Diversity and Fairness Metric, which quantifies both diversity and fairness while handling data imbalance across various datasets.
FaceSaliencyAug: Mitigating Geographic, Gender and Stereotypical Biases via Saliency-Based Data Augmentation
Oct 17, 2024
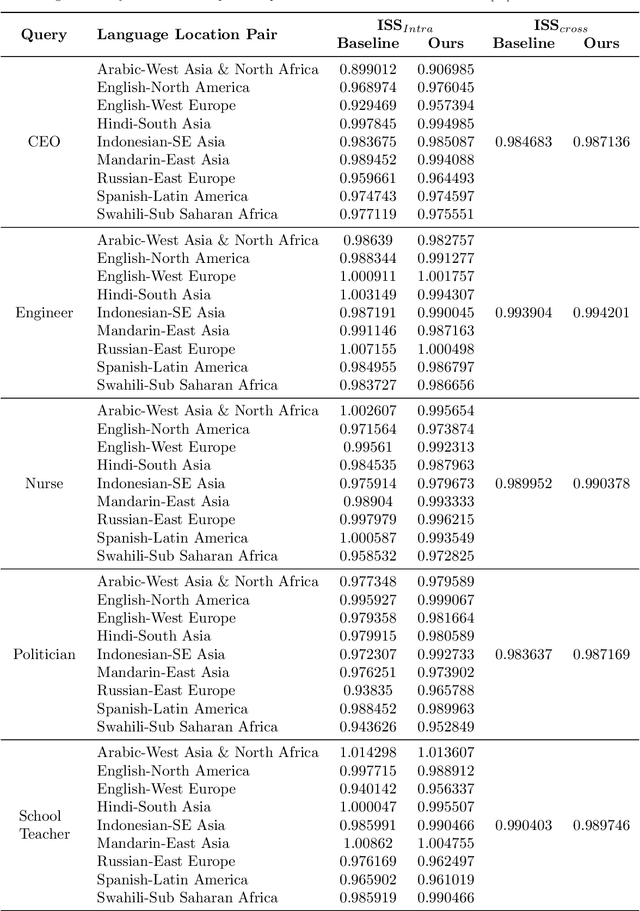
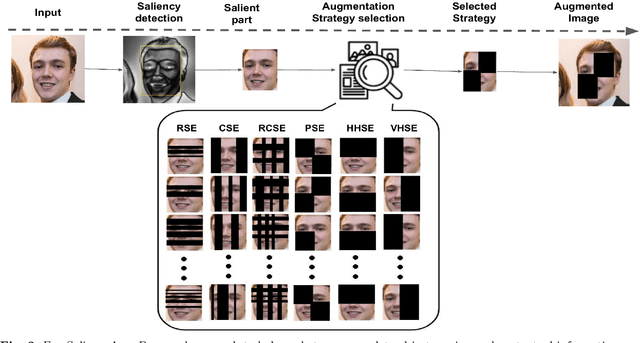
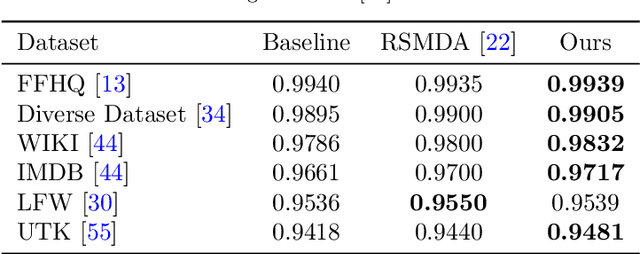
Geographical, gender and stereotypical biases in computer vision models pose significant challenges to their performance and fairness. {In this study, we present an approach named FaceSaliencyAug aimed at addressing the gender bias in} {Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs). Leveraging the salient regions} { of faces detected by saliency, the propose approach mitigates geographical and stereotypical biases } {in the datasets. FaceSaliencyAug} randomly selects masks from a predefined search space and applies them to the salient region of face images, subsequently restoring the original image with masked salient region. {The proposed} augmentation strategy enhances data diversity, thereby improving model performance and debiasing effects. We quantify dataset diversity using Image Similarity Score (ISS) across five datasets, including Flickr Faces HQ (FFHQ), WIKI, IMDB, Labelled Faces in the Wild (LFW), UTK Faces, and Diverse Dataset. The proposed approach demonstrates superior diversity metrics, as evaluated by ISS-intra and ISS-inter algorithms. Furthermore, we evaluate the effectiveness of our approach in mitigating gender bias on CEO, Engineer, Nurse, and School Teacher datasets. We use the Image-Image Association Score (IIAS) to measure gender bias in these occupations. Our experiments reveal a reduction in gender bias for both CNNs and ViTs, indicating the efficacy of our method in promoting fairness and inclusivity in computer vision models.
Personalization of Dataset Retrieval Results using a Metadata-based Data Valuation Method
Jul 22, 2024In this paper, we propose a novel data valuation method for a Dataset Retrieval (DR) use case in Ireland's National mapping agency. To the best of our knowledge, data valuation has not yet been applied to Dataset Retrieval. By leveraging metadata and a user's preferences, we estimate the personal value of each dataset to facilitate dataset retrieval and filtering. We then validated the data value-based ranking against the stakeholders' ranking of the datasets. The proposed data valuation method and use case demonstrated that data valuation is promising for dataset retrieval. For instance, the outperforming dataset retrieval based on our approach obtained 0.8207 in terms of NDCG@5 (the truncated Normalized Discounted Cumulative Gain at 5). This study is unique in its exploration of a data valuation-based approach to dataset retrieval and stands out because, unlike most existing methods, our approach is validated using the stakeholders ranking of the datasets.
KeepOriginalAugment: Single Image-based Better Information-Preserving Data Augmentation Approach
May 10, 2024
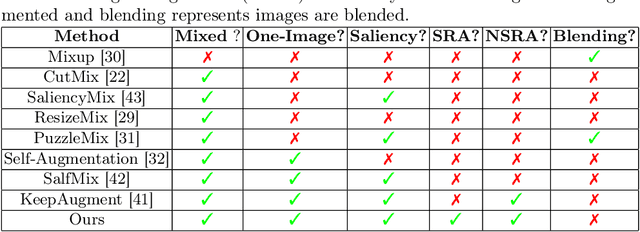

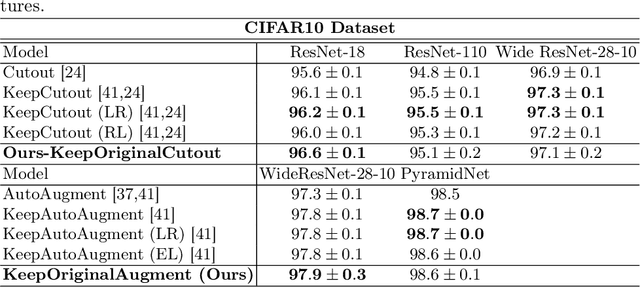
Advanced image data augmentation techniques play a pivotal role in enhancing the training of models for diverse computer vision tasks. Notably, SalfMix and KeepAugment have emerged as popular strategies, showcasing their efficacy in boosting model performance. However, SalfMix reliance on duplicating salient features poses a risk of overfitting, potentially compromising the model's generalization capabilities. Conversely, KeepAugment, which selectively preserves salient regions and augments non-salient ones, introduces a domain shift that hinders the exchange of crucial contextual information, impeding overall model understanding. In response to these challenges, we introduce KeepOriginalAugment, a novel data augmentation approach. This method intelligently incorporates the most salient region within the non-salient area, allowing augmentation to be applied to either region. Striking a balance between data diversity and information preservation, KeepOriginalAugment enables models to leverage both diverse salient and non-salient regions, leading to enhanced performance. We explore three strategies for determining the placement of the salient region minimum, maximum, or random and investigate swapping perspective strategies to decide which part (salient or non-salient) undergoes augmentation. Our experimental evaluations, conducted on classification datasets such as CIFAR-10, CIFAR-100, and TinyImageNet, demonstrate the superior performance of KeepOriginalAugment compared to existing state-of-the-art techniques.
AudRandAug: Random Image Augmentations for Audio Classification
Sep 09, 2023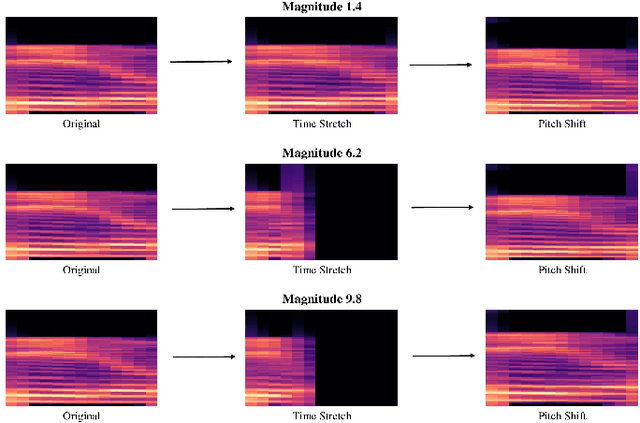

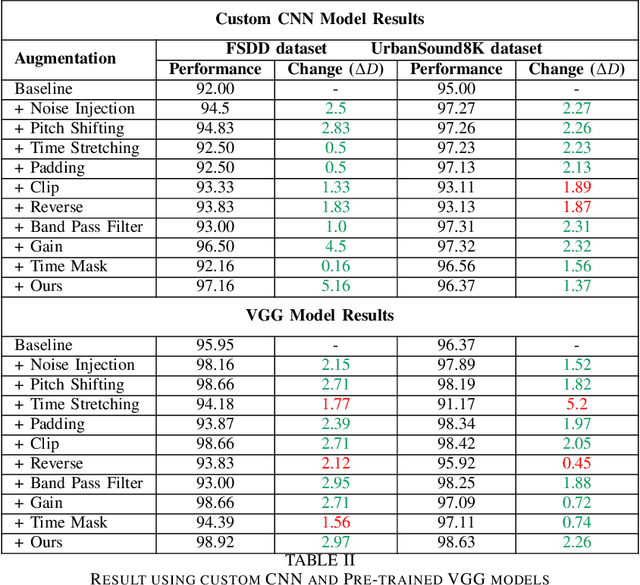
Data augmentation has proven to be effective in training neural networks. Recently, a method called RandAug was proposed, randomly selecting data augmentation techniques from a predefined search space. RandAug has demonstrated significant performance improvements for image-related tasks while imposing minimal computational overhead. However, no prior research has explored the application of RandAug specifically for audio data augmentation, which converts audio into an image-like pattern. To address this gap, we introduce AudRandAug, an adaptation of RandAug for audio data. AudRandAug selects data augmentation policies from a dedicated audio search space. To evaluate the effectiveness of AudRandAug, we conducted experiments using various models and datasets. Our findings indicate that AudRandAug outperforms other existing data augmentation methods regarding accuracy performance.
Advanced Data Augmentation Approaches: A Comprehensive Survey and Future directions
Jan 14, 2023



Deep learning (DL) algorithms have shown significant performance in various computer vision tasks. However, having limited labelled data lead to a network overfitting problem, where network performance is bad on unseen data as compared to training data. Consequently, it limits performance improvement. To cope with this problem, various techniques have been proposed such as dropout, normalization and advanced data augmentation. Among these, data augmentation, which aims to enlarge the dataset size by including sample diversity, has been a hot topic in recent times. In this article, we focus on advanced data augmentation techniques. we provide a background of data augmentation, a novel and comprehensive taxonomy of reviewed data augmentation techniques, and the strengths and weaknesses (wherever possible) of each technique. We also provide comprehensive results of the data augmentation effect on three popular computer vision tasks, such as image classification, object detection and semantic segmentation. For results reproducibility, we compiled available codes of all data augmentation techniques. Finally, we discuss the challenges and difficulties, and possible future direction for the research community. We believe, this survey provides several benefits i) readers will understand the data augmentation working mechanism to fix overfitting problems ii) results will save the searching time of the researcher for comparison purposes. iii) Codes of the mentioned data augmentation techniques are available at https://github.com/kmr2017/Advanced-Data-augmentation-codes iv) Future work will spark interest in research community.
Random Data Augmentation based Enhancement: A Generalized Enhancement Approach for Medical Datasets
Oct 03, 2022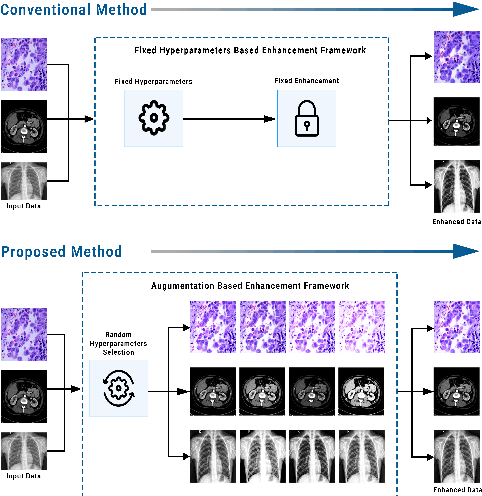

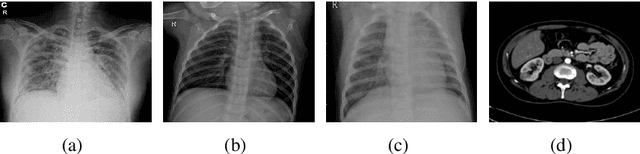

Over the years, the paradigm of medical image analysis has shifted from manual expertise to automated systems, often using deep learning (DL) systems. The performance of deep learning algorithms is highly dependent on data quality. Particularly for the medical domain, it is an important aspect as medical data is very sensitive to quality and poor quality can lead to misdiagnosis. To improve the diagnostic performance, research has been done both in complex DL architectures and in improving data quality using dataset dependent static hyperparameters. However, the performance is still constrained due to data quality and overfitting of hyperparameters to a specific dataset. To overcome these issues, this paper proposes random data augmentation based enhancement. The main objective is to develop a generalized, data-independent and computationally efficient enhancement approach to improve medical data quality for DL. The quality is enhanced by improving the brightness and contrast of images. In contrast to the existing methods, our method generates enhancement hyperparameters randomly within a defined range, which makes it robust and prevents overfitting to a specific dataset. To evaluate the generalization of the proposed method, we use four medical datasets and compare its performance with state-of-the-art methods for both classification and segmentation tasks. For grayscale imagery, experiments have been performed with: COVID-19 chest X-ray, KiTS19, and for RGB imagery with: LC25000 datasets. Experimental results demonstrate that with the proposed enhancement methodology, DL architectures outperform other existing methods. Our code is publicly available at: https://github.com/aleemsidra/Augmentation-Based-Generalized-Enhancement
Investigating Multi-Feature Selection and Ensembling for Audio Classification
Jun 15, 2022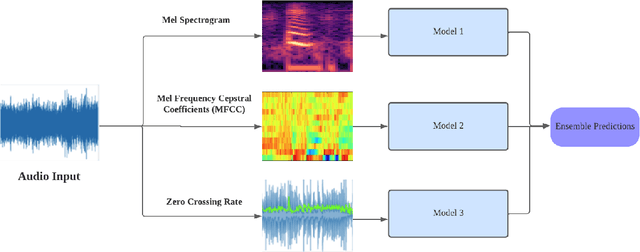
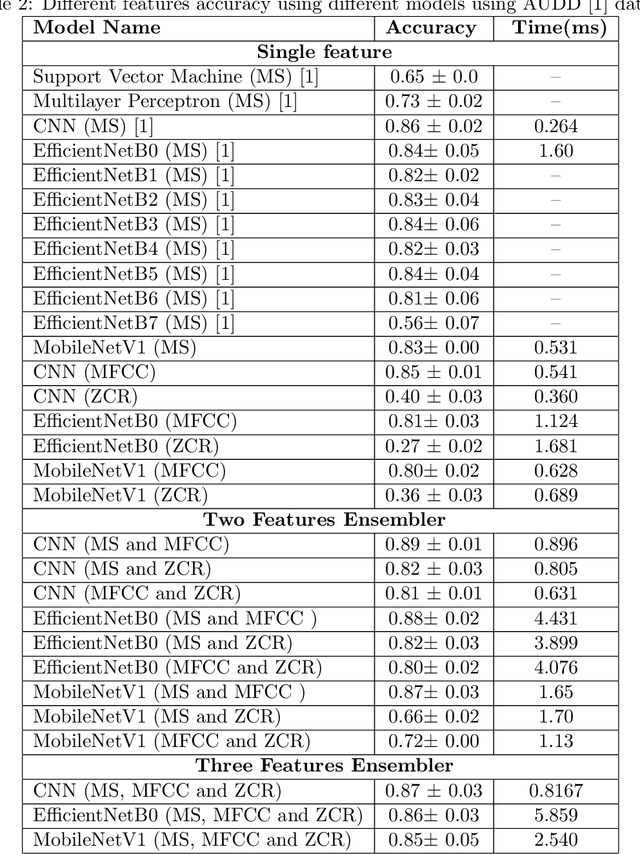
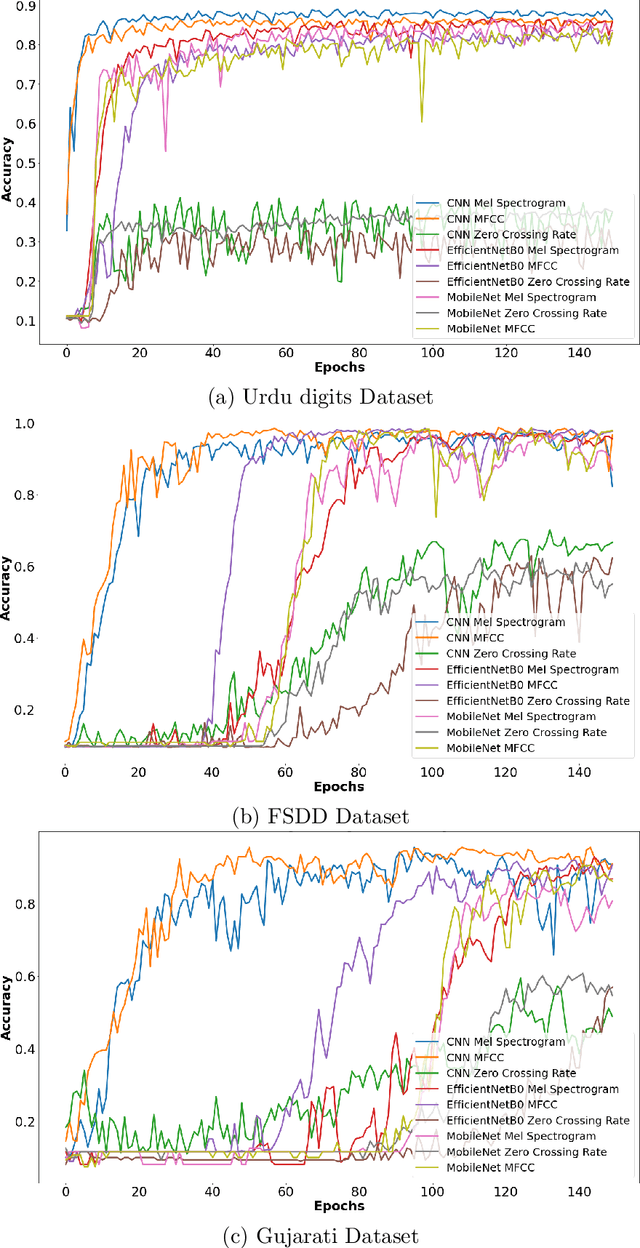
Deep Learning (DL) algorithms have shown impressive performance in diverse domains. Among them, audio has attracted many researchers over the last couple of decades due to some interesting patterns--particularly in classification of audio data. For better performance of audio classification, feature selection and combination play a key role as they have the potential to make or break the performance of any DL model. To investigate this role, we conduct an extensive evaluation of the performance of several cutting-edge DL models (i.e., Convolutional Neural Network, EfficientNet, MobileNet, Supper Vector Machine and Multi-Perceptron) with various state-of-the-art audio features (i.e., Mel Spectrogram, Mel Frequency Cepstral Coefficients, and Zero Crossing Rate) either independently or as a combination (i.e., through ensembling) on three different datasets (i.e., Free Spoken Digits Dataset, Audio Urdu Digits Dataset, and Audio Gujarati Digits Dataset). Overall, results suggest feature selection depends on both the dataset and the model. However, feature combinations should be restricted to the only features that already achieve good performances when used individually (i.e., mostly Mel Spectrogram, Mel Frequency Cepstral Coefficients). Such feature combination/ensembling enabled us to outperform the previous state-of-the-art results irrespective of our choice of DL model.
Efficient Large Scale Clustering based on Data Partitioning
Feb 26, 2018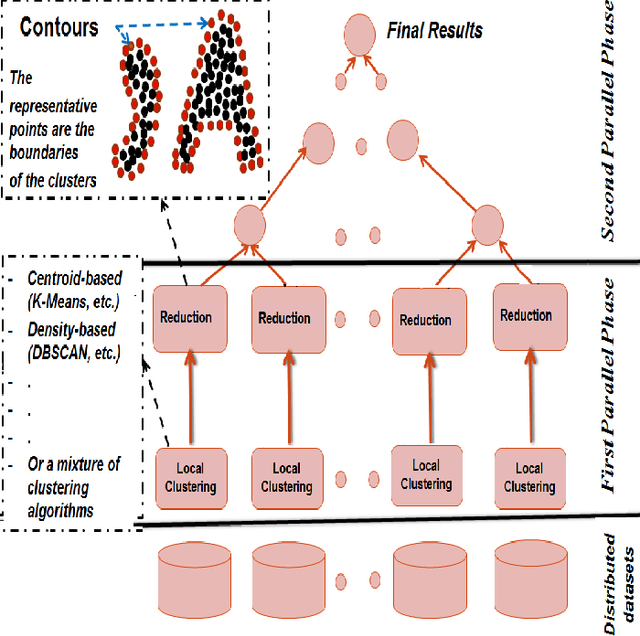



Clustering techniques are very attractive for extracting and identifying patterns in datasets. However, their application to very large spatial datasets presents numerous challenges such as high-dimensionality data, heterogeneity, and high complexity of some algorithms. For instance, some algorithms may have linear complexity but they require the domain knowledge in order to determine their input parameters. Distributed clustering techniques constitute a very good alternative to the big data challenges (e.g.,Volume, Variety, Veracity, and Velocity). Usually these techniques consist of two phases. The first phase generates local models or patterns and the second one tends to aggregate the local results to obtain global models. While the first phase can be executed in parallel on each site and, therefore, efficient, the aggregation phase is complex, time consuming and may produce incorrect and ambiguous global clusters and therefore incorrect models. In this paper we propose a new distributed clustering approach to deal efficiently with both phases, generation of local results and generation of global models by aggregation. For the first phase, our approach is capable of analysing the datasets located in each site using different clustering techniques. The aggregation phase is designed in such a way that the final clusters are compact and accurate while the overall process is efficient in time and memory allocation. For the evaluation, we use two well-known clustering algorithms, K-Means and DBSCAN. One of the key outputs of this distributed clustering technique is that the number of global clusters is dynamic, no need to be fixed in advance. Experimental results show that the approach is scalable and produces high quality results.
* 10 pages
Hierarchical Aggregation Approach for Distributed clustering of spatial datasets
Feb 01, 2018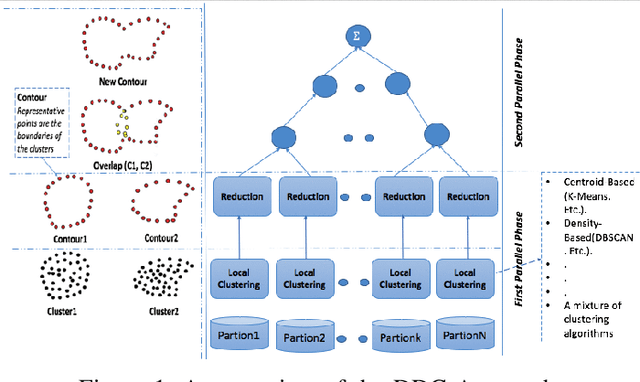
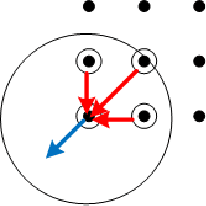
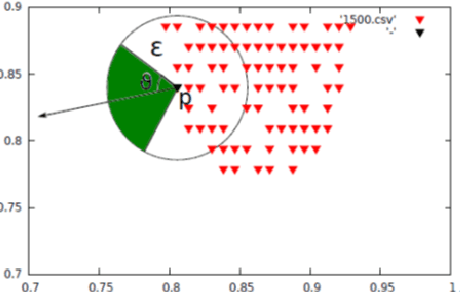
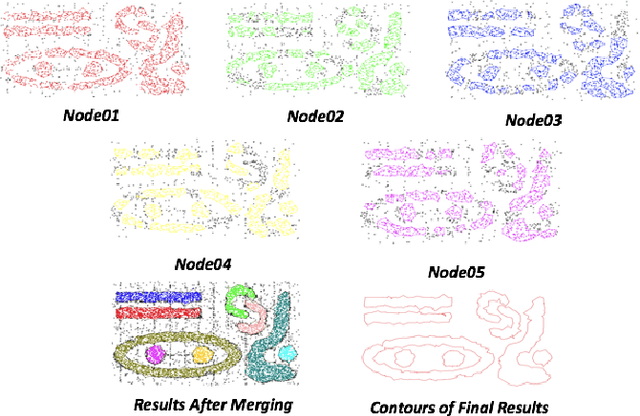
In this paper, we present a new approach of distributed clustering for spatial datasets, based on an innovative and efficient aggregation technique. This distributed approach consists of two phases: 1) local clustering phase, where each node performs a clustering on its local data, 2) aggregation phase, where the local clusters are aggregated to produce global clusters. This approach is characterised by the fact that the local clusters are represented in a simple and efficient way. And The aggregation phase is designed in such a way that the final clusters are compact and accurate while the overall process is efficient in both response time and memory allocation. We evaluated the approach with different datasets and compared it to well-known clustering techniques. The experimental results show that our approach is very promising and outperforms all those algorithms