 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynSacc: A Blender-to-V2E Pipeline for Synthetic Neuromorphic Eye-Movement Data and Sim-to-Real Spiking Model Training
Feb 09, 2026The study of eye movements, particularly saccades and fixations, are fundamental to understanding the mechanisms of human cognition and perception. Accurate classification of these movements requires sensing technologies capable of capturing rapid dynamics without distortion. Event cameras, also known as Dynamic Vision Sensors (DVS), provide asynchronous recordings of changes in light intensity, thereby eliminating motion blur inherent in conventional frame-based cameras and offering superior temporal resolution and data efficiency. In this study, we introduce a synthetic dataset generated with Blender to simulate saccades and fixations under controlled conditions. Leveraging Spiking Neural Networks (SNNs), we evaluate its robustness by training two architectures and finetuning on real event data. The proposed models achieve up to 0.83 accuracy and maintain consistent performance across varying temporal resolutions, demonstrating stability in eye movement classification. Moreover, the use of SNNs with synthetic event streams yields substantial computational efficiency gains over artificial neural network (ANN) counterparts, underscoring the utility of synthetic data augmentation in advancing event-based vision. All code and datasets associated with this work is available at https: //github.com/Ikhadija-5/SynSacc-Dataset.
Generated Bias: Auditing Internal Bias Dynamics of Text-To-Image Generative Models
Oct 10, 2024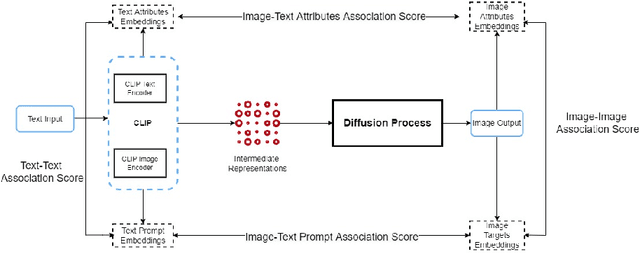


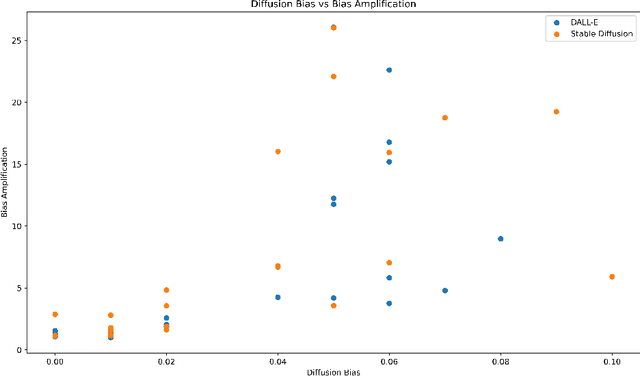
Text-To-Image (TTI) Diffusion Models such as DALL-E and Stable Diffusion are capable of generating images from text prompts. However, they have been shown to perpetuate gender stereotypes. These models process data internally in multiple stages and employ several constituent models, often trained separately. In this paper, we propose two novel metrics to measure bias internally in these multistage multimodal models. Diffusion Bias was developed to detect and measures bias introduced by the diffusion stage of the models. Bias Amplification measures amplification of bias during the text-to-image conversion process. Our experiments reveal that TTI models amplify gender bias, the diffusion process itself contributes to bias and that Stable Diffusion v2 is more prone to gender bias than DALL-E 2.
Evaluating Image-Based Face and Eye Tracking with Event Cameras
Aug 19, 2024
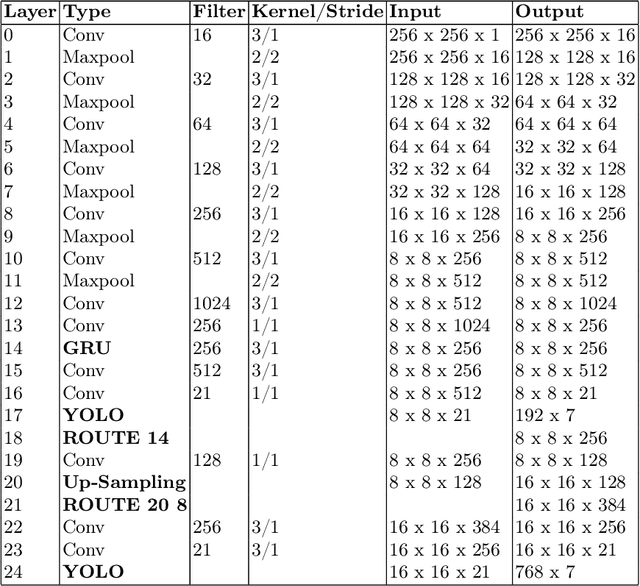


Event Cameras, also known as Neuromorphic sensors, capture changes in local light intensity at the pixel level, producing asynchronously generated data termed ``events''. This distinct data format mitigates common issues observed in conventional cameras, like under-sampling when capturing fast-moving objects, thereby preserving critical information that might otherwise be lost. However, leveraging this data often necessitates the development of specialized, handcrafted event representations that can integrate seamlessly with conventional Convolutional Neural Networks (CNNs), considering the unique attributes of event data. In this study, We evaluate event-based Face and Eye tracking. The core objective of our study is to showcase the viability of integrating conventional algorithms with event-based data, transformed into a frame format while preserving the unique benefits of event cameras. To validate our approach, we constructed a frame-based event dataset by simulating events between RGB frames derived from the publicly accessible Helen Dataset. We assess its utility for face and eye detection tasks through the application of GR-YOLO -- a pioneering technique derived from YOLOv3. This evaluation includes a comparative analysis with results derived from training the dataset with YOLOv8. Subsequently, the trained models were tested on real event streams from various iterations of Prophesee's event cameras and further evaluated on the Faces in Event Stream (FES) benchmark dataset. The models trained on our dataset shows a good prediction performance across all the datasets obtained for validation with the best results of a mean Average precision score of 0.91. Additionally, The models trained demonstrated robust performance on real event camera data under varying light conditions.
A Framework for Pupil Tracking with Event Cameras
Jul 23, 2024Saccades are extremely rapid movements of both eyes that occur simultaneously, typically observed when an individual shifts their focus from one object to another. These movements are among the swiftest produced by humans and possess the potential to achieve velocities greater than that of blinks. The peak angular speed of the eye during a saccade can reach as high as 700{\deg}/s in humans, especially during larger saccades that cover a visual angle of 25{\deg}. Previous research has demonstrated encouraging outcomes in comprehending neurological conditions through the study of saccades. A necessary step in saccade detection involves accurately identifying the precise location of the pupil within the eye, from which additional information such as gaze angles can be inferred. Conventional frame-based cameras often struggle with the high temporal precision necessary for tracking very fast movements, resulting in motion blur and latency issues. Event cameras, on the other hand, offer a promising alternative by recording changes in the visual scene asynchronously and providing high temporal resolution and low latency. By bridging the gap between traditional computer vision and event-based vision, we present events as frames that can be readily utilized by standard deep learning algorithms. This approach harnesses YOLOv8, a state-of-the-art object detection technology, to process these frames for pupil tracking using the publicly accessible Ev-Eye dataset. Experimental results demonstrate the framework's effectiveness, highlighting its potential applications in neuroscience, ophthalmology, and human-computer interaction.
Test-Time Adaptation with SaLIP: A Cascade of SAM and CLIP for Zero shot Medical Image Segmentation
Apr 09, 2024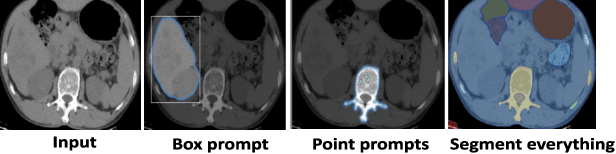
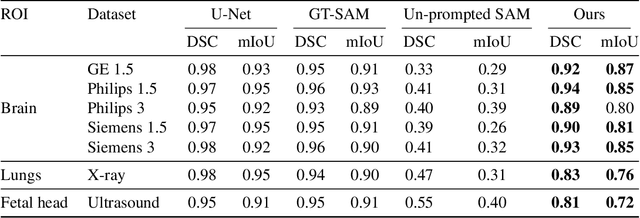
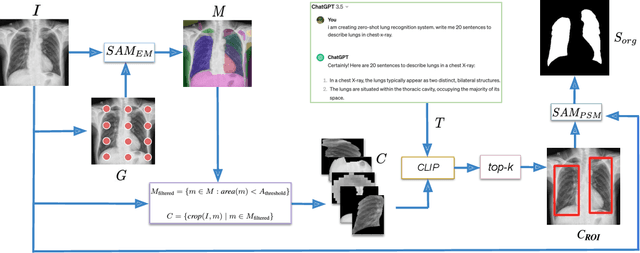

The Segment Anything Model (SAM) and CLIP are remarkable vision foundation models (VFMs). SAM, a prompt driven segmentation model, excels in segmentation tasks across diverse domains, while CLIP is renowned for its zero shot recognition capabilities. However, their unified potential has not yet been explored in medical image segmentation. To adapt SAM to medical imaging, existing methods primarily rely on tuning strategies that require extensive data or prior prompts tailored to the specific task, making it particularly challenging when only a limited number of data samples are available. This work presents an in depth exploration of integrating SAM and CLIP into a unified framework for medical image segmentation. Specifically, we propose a simple unified framework, SaLIP, for organ segmentation. Initially, SAM is used for part based segmentation within the image, followed by CLIP to retrieve the mask corresponding to the region of interest (ROI) from the pool of SAM generated masks. Finally, SAM is prompted by the retrieved ROI to segment a specific organ. Thus, SaLIP is training and fine tuning free and does not rely on domain expertise or labeled data for prompt engineering. Our method shows substantial enhancements in zero shot segmentation, showcasing notable improvements in DICE scores across diverse segmentation tasks like brain (63.46%), lung (50.11%), and fetal head (30.82%), when compared to un prompted SAM. Code and text prompts will be available online.
ConvLoRA and AdaBN based Domain Adaptation via Self-Training
Feb 07, 2024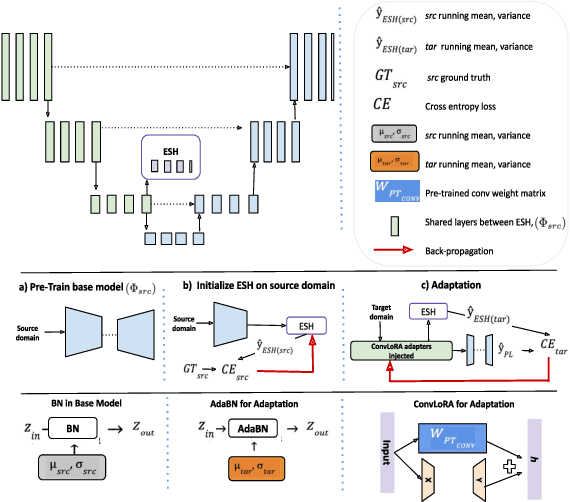
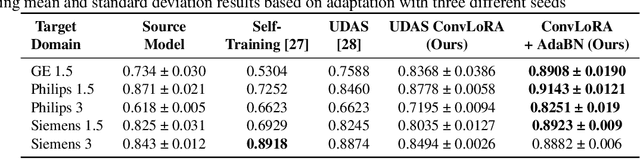
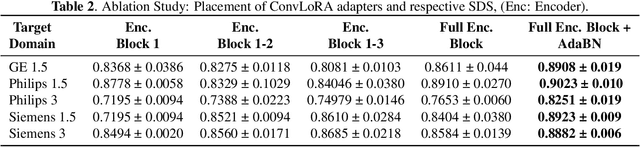
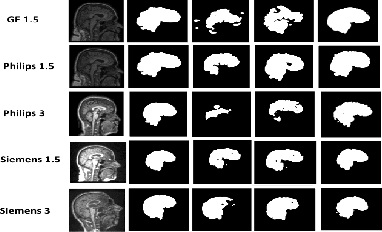
Existing domain adaptation (DA) methods often involve pre-training on the source domain and fine-tuning on the target domain. For multi-target domain adaptation, having a dedicated/separate fine-tuned network for each target domain, that retain all the pre-trained model parameters, is prohibitively expensive. To address this limitation, we propose Convolutional Low-Rank Adaptation (ConvLoRA). ConvLoRA freezes pre-trained model weights, adds trainable low-rank decomposition matrices to convolutional layers, and backpropagates the gradient through these matrices thus greatly reducing the number of trainable parameters. To further boost adaptation, we utilize Adaptive Batch Normalization (AdaBN) which computes target-specific running statistics and use it along with ConvLoRA. Our method has fewer trainable parameters and performs better or on-par with large independent fine-tuned networks (with less than 0.9% trainable parameters of the total base model) when tested on the segmentation of Calgary-Campinas dataset containing brain MRI images. Our approach is simple, yet effective and can be applied to any deep learning-based architecture which uses convolutional and batch normalization layers. Code is available at: https://github.com/aleemsidra/ConvLoRA.
Biased Attention: Do Vision Transformers Amplify Gender Bias More than Convolutional Neural Networks?
Sep 15, 2023


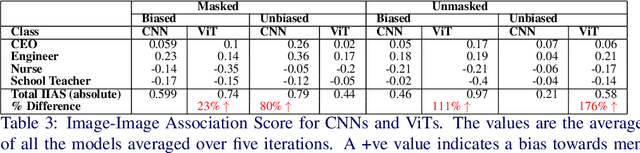
Deep neural networks used in computer vision have been shown to exhibit many social biases such as gender bias. Vision Transformers (ViTs) have become increasingly popular in computer vision applications, outperforming Convolutional Neural Networks (CNNs) in many tasks such as image classification. However, given that research on mitigating bias in computer vision has primarily focused on CNNs, it is important to evaluate the effect of a different network architecture on the potential for bias amplification. In this paper we therefore introduce a novel metric to measure bias in architectures, Accuracy Difference. We examine bias amplification when models belonging to these two architectures are used as a part of large multimodal models, evaluating the different image encoders of Contrastive Language Image Pretraining which is an important model used in many generative models such as DALL-E and Stable Diffusion. Our experiments demonstrate that architecture can play a role in amplifying social biases due to the different techniques employed by the models for feature extraction and embedding as well as their different learning properties. This research found that ViTs amplified gender bias to a greater extent than CNNs
An Ensemble Deep Learning Approach for COVID-19 Severity Prediction Using Chest CT Scans
May 17, 2023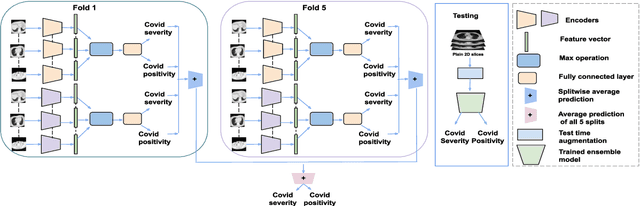
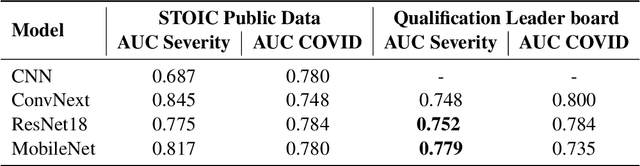

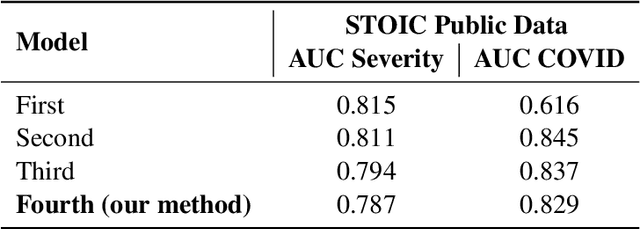
Chest X-rays have been widely used for COVID-19 screening; however, 3D computed tomography (CT) is a more effective modality. We present our findings on COVID-19 severity prediction from chest CT scans using the STOIC dataset. We developed an ensemble deep learning based model that incorporates multiple neural networks to improve predictions. To address data imbalance, we used slicing functions and data augmentation. We further improved performance using test time data augmentation. Our approach which employs a simple yet effective ensemble of deep learning-based models with strong test time augmentations, achieved results comparable to more complex methods and secured the fourth position in the STOIC2021 COVID-19 AI Challenge. Our code is available on online: at: https://github.com/aleemsidra/stoic2021- baseline-finalphase-main.
Multimodal Composite Association Score: Measuring Gender Bias in Generative Multimodal Models
Apr 26, 2023
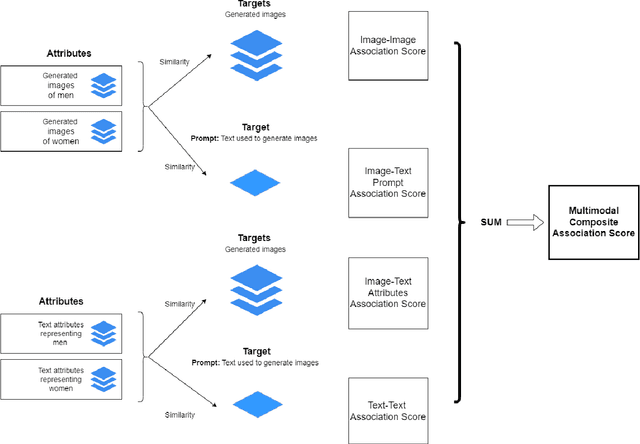

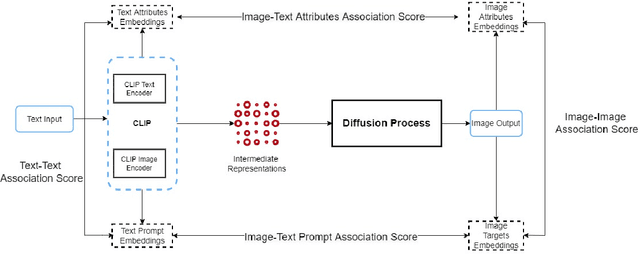
Generative multimodal models based on diffusion models have seen tremendous growth and advances in recent years. Models such as DALL-E and Stable Diffusion have become increasingly popular and successful at creating images from texts, often combining abstract ideas. However, like other deep learning models, they also reflect social biases they inherit from their training data, which is often crawled from the internet. Manually auditing models for biases can be very time and resource consuming and is further complicated by the unbounded and unconstrained nature of inputs these models can take. Research into bias measurement and quantification has generally focused on small single-stage models working on a single modality. Thus the emergence of multistage multimodal models requires a different approach. In this paper, we propose Multimodal Composite Association Score (MCAS) as a new method of measuring gender bias in multimodal generative models. Evaluating both DALL-E 2 and Stable Diffusion using this approach uncovered the presence of gendered associations of concepts embedded within the models. We propose MCAS as an accessible and scalable method of quantifying potential bias for models with different modalities and a range of potential biases.
Constructing a meta-learner for unsupervised anomaly detection
Apr 22, 2023Unsupervised anomaly detection (AD) is critical for a wide range of practical applications, from network security to health and medical tools. Due to the diversity of problems, no single algorithm has been found to be superior for all AD tasks. Choosing an algorithm, otherwise known as the Algorithm Selection Problem (ASP), has been extensively examined in supervised classification problems, through the use of meta-learning and AutoML, however, it has received little attention in unsupervised AD tasks. This research proposes a new meta-learning approach that identifies an appropriate unsupervised AD algorithm given a set of meta-features generated from the unlabelled input dataset. The performance of the proposed meta-learner is superior to the current state of the art solution. In addition, a mixed model statistical analysis has been conducted to examine the impact of the meta-learner components: the meta-model, meta-features, and the base set of AD algorithms, on the overall performance of the meta-learner. The analysis was conducted using more than 10,000 datasets, which is significantly larger than previous studies. Results indicate that a relatively small number of meta-features can be used to identify an appropriate AD algorithm, but the choice of a meta-model in the meta-learner has a considerable impact.