 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapting Psycholinguistic Research for LLMs: Gender-inclusive Language in a Coreference Context
Feb 18, 2025Gender-inclusive language is often used with the aim of ensuring that all individuals, regardless of gender, can be associated with certain concepts. While psycholinguistic studies have examined its effects in relation to human cognition, it remains unclear how Large Language Models (LLMs) process gender-inclusive language. Given that commercial LLMs are gaining an increasingly strong foothold in everyday applications, it is crucial to examine whether LLMs in fact interpret gender-inclusive language neutrally, because the language they generate has the potential to influence the language of their users. This study examines whether LLM-generated coreferent terms align with a given gender expression or reflect model biases. Adapting psycholinguistic methods from French to English and German, we find that in English, LLMs generally maintain the antecedent's gender but exhibit underlying masculine bias. In German, this bias is much stronger, overriding all tested gender-neutralization strategies.
International AI Safety Report
Jan 29, 2025



The first International AI Safety Report comprehensively synthesizes the current evidence on the capabilities, risks, and safety of advanced AI systems. The report was mandated by the nations attending the AI Safety Summit in Bletchley, UK. Thirty nations, the UN, the OECD, and the EU each nominated a representative to the report's Expert Advisory Panel. A total of 100 AI experts contributed, representing diverse perspectives and disciplines. Led by the report's Chair, these independent experts collectively had full discretion over the report's content.
Generated Bias: Auditing Internal Bias Dynamics of Text-To-Image Generative Models
Oct 10, 2024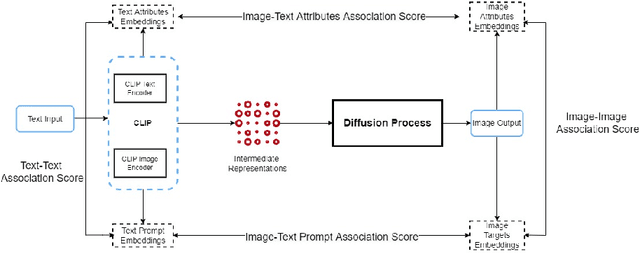


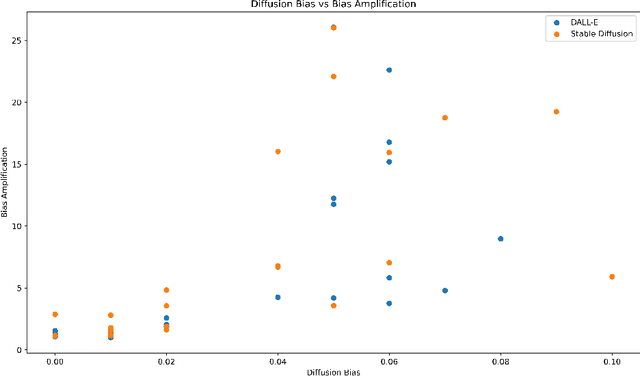
Text-To-Image (TTI) Diffusion Models such as DALL-E and Stable Diffusion are capable of generating images from text prompts. However, they have been shown to perpetuate gender stereotypes. These models process data internally in multiple stages and employ several constituent models, often trained separately. In this paper, we propose two novel metrics to measure bias internally in these multistage multimodal models. Diffusion Bias was developed to detect and measures bias introduced by the diffusion stage of the models. Bias Amplification measures amplification of bias during the text-to-image conversion process. Our experiments reveal that TTI models amplify gender bias, the diffusion process itself contributes to bias and that Stable Diffusion v2 is more prone to gender bias than DALL-E 2.
From 'Showgirls' to 'Performers': Fine-tuning with Gender-inclusive Language for Bias Reduction in LLMs
Jul 05, 2024Gender bias is not only prevalent in Large Language Models (LLMs) and their training data, but also firmly ingrained into the structural aspects of language itself. Therefore, adapting linguistic structures within LLM training data to promote gender-inclusivity can make gender representations within the model more inclusive. The focus of our work are gender-exclusive affixes in English, such as in 'show-girl' or 'man-cave', which can perpetuate gender stereotypes and binary conceptions of gender. We use an LLM training dataset to compile a catalogue of 692 gender-exclusive terms along with gender-neutral variants and from this, develop a gender-inclusive fine-tuning dataset, the 'Tiny Heap'. Fine-tuning three different LLMs with this dataset, we observe an overall reduction in gender-stereotyping tendencies across the models. Our approach provides a practical method for enhancing gender inclusivity in LLM training data and contributes to incorporating queer-feminist linguistic activism in bias mitigation research in NLP.
Biased Attention: Do Vision Transformers Amplify Gender Bias More than Convolutional Neural Networks?
Sep 15, 2023


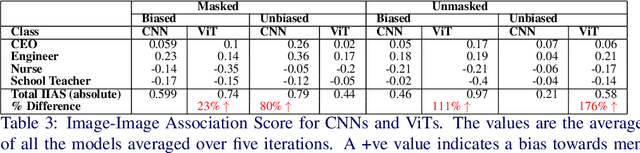
Deep neural networks used in computer vision have been shown to exhibit many social biases such as gender bias. Vision Transformers (ViTs) have become increasingly popular in computer vision applications, outperforming Convolutional Neural Networks (CNNs) in many tasks such as image classification. However, given that research on mitigating bias in computer vision has primarily focused on CNNs, it is important to evaluate the effect of a different network architecture on the potential for bias amplification. In this paper we therefore introduce a novel metric to measure bias in architectures, Accuracy Difference. We examine bias amplification when models belonging to these two architectures are used as a part of large multimodal models, evaluating the different image encoders of Contrastive Language Image Pretraining which is an important model used in many generative models such as DALL-E and Stable Diffusion. Our experiments demonstrate that architecture can play a role in amplifying social biases due to the different techniques employed by the models for feature extraction and embedding as well as their different learning properties. This research found that ViTs amplified gender bias to a greater extent than CNNs
Industrial Memories: Exploring the Findings of Government Inquiries with Neural Word Embedding and Machine Learning
Aug 02, 2023We present a text mining system to support the exploration of large volumes of text detailing the findings of government inquiries. Despite their historical significance and potential societal impact, key findings of inquiries are often hidden within lengthy documents and remain inaccessible to the general public. We transform the findings of the Irish government's inquiry into industrial schools and through the use of word embedding, text classification and visualisation, present an interactive web-based platform that enables the exploration of the text to uncover new historical insights.
* Machine Learning and Knowledge Discovery in Databases. ECML PKDD 2018. Lecture Notes in Computer Science
Curatr: A Platform for Semantic Analysis and Curation of Historical Literary Texts
Jun 13, 2023The increasing availability of digital collections of historical and contemporary literature presents a wealth of possibilities for new research in the humanities. The scale and diversity of such collections however, presents particular challenges in identifying and extracting relevant content. This paper presents Curatr, an online platform for the exploration and curation of literature with machine learning-supported semantic search, designed within the context of digital humanities scholarship. The platform provides a text mining workflow that combines neural word embeddings with expert domain knowledge to enable the generation of thematic lexicons, allowing researches to curate relevant sub-corpora from a large corpus of 18th and 19th century digitised texts.
* 12 pages
Multimodal Composite Association Score: Measuring Gender Bias in Generative Multimodal Models
Apr 26, 2023
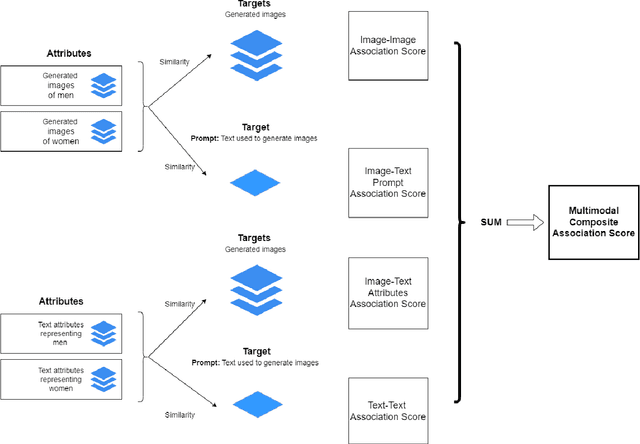

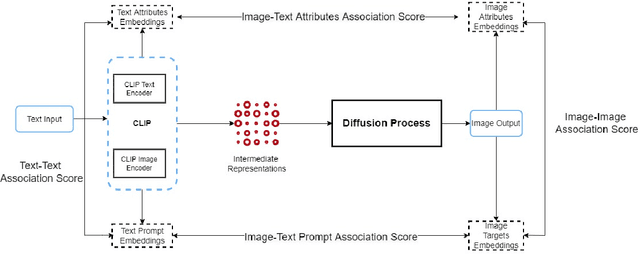
Generative multimodal models based on diffusion models have seen tremendous growth and advances in recent years. Models such as DALL-E and Stable Diffusion have become increasingly popular and successful at creating images from texts, often combining abstract ideas. However, like other deep learning models, they also reflect social biases they inherit from their training data, which is often crawled from the internet. Manually auditing models for biases can be very time and resource consuming and is further complicated by the unbounded and unconstrained nature of inputs these models can take. Research into bias measurement and quantification has generally focused on small single-stage models working on a single modality. Thus the emergence of multistage multimodal models requires a different approach. In this paper, we propose Multimodal Composite Association Score (MCAS) as a new method of measuring gender bias in multimodal generative models. Evaluating both DALL-E 2 and Stable Diffusion using this approach uncovered the presence of gendered associations of concepts embedded within the models. We propose MCAS as an accessible and scalable method of quantifying potential bias for models with different modalities and a range of potential biases.
Inclusive Ethical Design for Recommender Systems
Sep 13, 2022Recommender systems are becoming increasingly central as mediators of information with the potential to profoundly influence societal opinion. While approaches are being developed to ensure these systems are designed in a responsible way, adolescents in particular, represent a potentially vulnerable user group requiring explicit consideration. This is especially important given the nature of their access and use of recommender systems but also their role as providers of content. This paper proposes core principles for the ethical design of recommender systems and evaluates whether current approaches to ensuring adherence to these principles are sufficiently inclusive of the particular needs and potential vulnerabilities of adolescent users.
Towards Lexical Gender Inference: A Scalable Methodology using Online Databases
Jun 28, 2022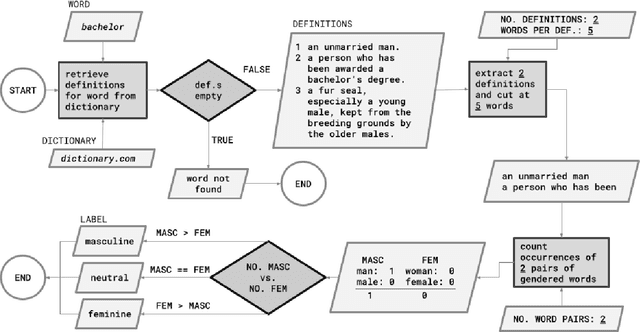

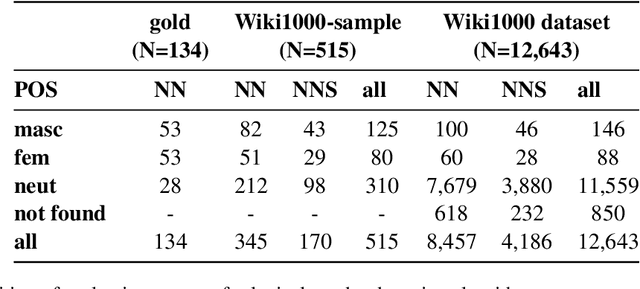
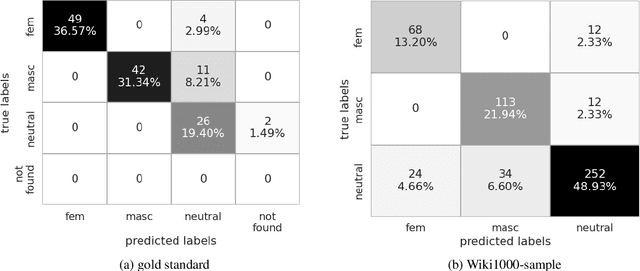
This paper presents a new method for automatically detecting words with lexical gender in large-scale language datasets. Currently, the evaluation of gender bias in natural language processing relies on manually compiled lexicons of gendered expressions, such as pronouns ('he', 'she', etc.) and nouns with lexical gender ('mother', 'boyfriend', 'policewoman', etc.). However, manual compilation of such lists can lead to static information if they are not periodically updated and often involve value judgments by individual annotators and researchers. Moreover, terms not included in the list fall out of the range of analysis. To address these issues, we devised a scalable, dictionary-based method to automatically detect lexical gender that can provide a dynamic, up-to-date analysis with high coverage. Our approach reaches over 80% accuracy in determining the lexical gender of nouns retrieved randomly from a Wikipedia sample and when testing on a list of gendered words used in previous research.