 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Lexical Gender Inference: A Scalable Methodology using Online Databases
Paper and Code
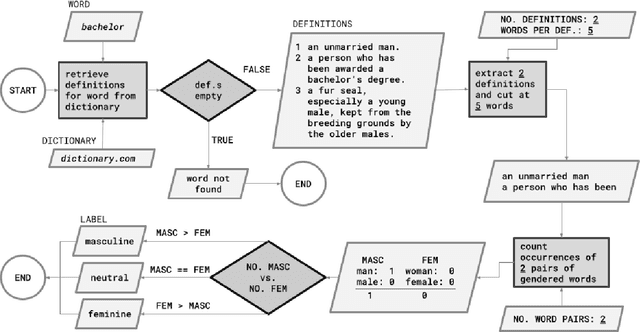

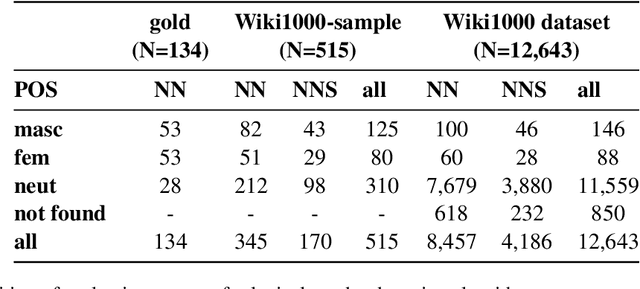
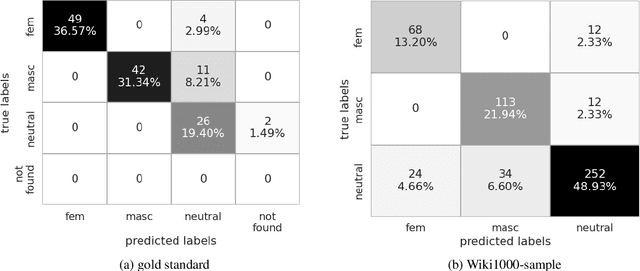
This paper presents a new method for automatically detecting words with lexical gender in large-scale language datasets. Currently, the evaluation of gender bias in natural language processing relies on manually compiled lexicons of gendered expressions, such as pronouns ('he', 'she', etc.) and nouns with lexical gender ('mother', 'boyfriend', 'policewoman', etc.). However, manual compilation of such lists can lead to static information if they are not periodically updated and often involve value judgments by individual annotators and researchers. Moreover, terms not included in the list fall out of the range of analysis. To address these issues, we devised a scalable, dictionary-based method to automatically detect lexical gender that can provide a dynamic, up-to-date analysis with high coverage. Our approach reaches over 80% accuracy in determining the lexical gender of nouns retrieved randomly from a Wikipedia sample and when testing on a list of gendered words used in previous research.