 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapting Psycholinguistic Research for LLMs: Gender-inclusive Language in a Coreference Context
Feb 18, 2025Gender-inclusive language is often used with the aim of ensuring that all individuals, regardless of gender, can be associated with certain concepts. While psycholinguistic studies have examined its effects in relation to human cognition, it remains unclear how Large Language Models (LLMs) process gender-inclusive language. Given that commercial LLMs are gaining an increasingly strong foothold in everyday applications, it is crucial to examine whether LLMs in fact interpret gender-inclusive language neutrally, because the language they generate has the potential to influence the language of their users. This study examines whether LLM-generated coreferent terms align with a given gender expression or reflect model biases. Adapting psycholinguistic methods from French to English and German, we find that in English, LLMs generally maintain the antecedent's gender but exhibit underlying masculine bias. In German, this bias is much stronger, overriding all tested gender-neutralization strategies.
From 'Showgirls' to 'Performers': Fine-tuning with Gender-inclusive Language for Bias Reduction in LLMs
Jul 05, 2024Gender bias is not only prevalent in Large Language Models (LLMs) and their training data, but also firmly ingrained into the structural aspects of language itself. Therefore, adapting linguistic structures within LLM training data to promote gender-inclusivity can make gender representations within the model more inclusive. The focus of our work are gender-exclusive affixes in English, such as in 'show-girl' or 'man-cave', which can perpetuate gender stereotypes and binary conceptions of gender. We use an LLM training dataset to compile a catalogue of 692 gender-exclusive terms along with gender-neutral variants and from this, develop a gender-inclusive fine-tuning dataset, the 'Tiny Heap'. Fine-tuning three different LLMs with this dataset, we observe an overall reduction in gender-stereotyping tendencies across the models. Our approach provides a practical method for enhancing gender inclusivity in LLM training data and contributes to incorporating queer-feminist linguistic activism in bias mitigation research in NLP.
Towards Lexical Gender Inference: A Scalable Methodology using Online Databases
Jun 28, 2022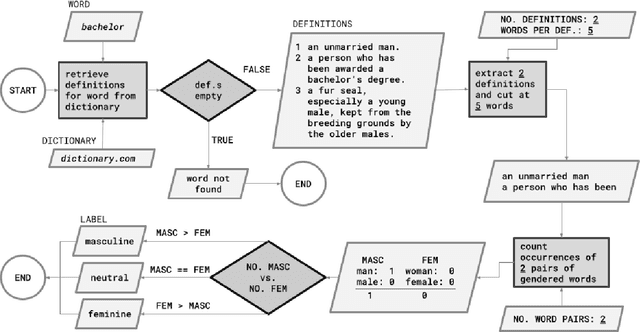

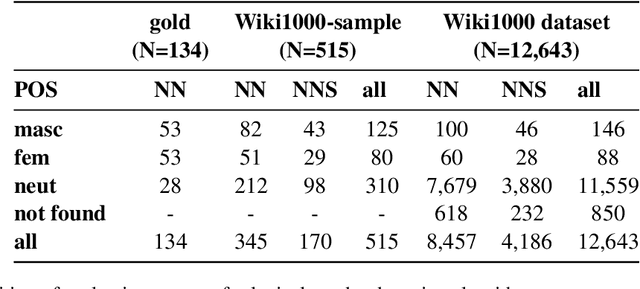
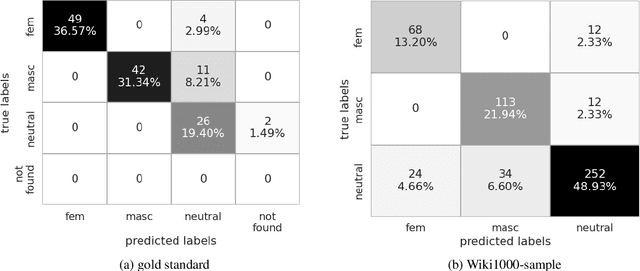
This paper presents a new method for automatically detecting words with lexical gender in large-scale language datasets. Currently, the evaluation of gender bias in natural language processing relies on manually compiled lexicons of gendered expressions, such as pronouns ('he', 'she', etc.) and nouns with lexical gender ('mother', 'boyfriend', 'policewoman', etc.). However, manual compilation of such lists can lead to static information if they are not periodically updated and often involve value judgments by individual annotators and researchers. Moreover, terms not included in the list fall out of the range of analysis. To address these issues, we devised a scalable, dictionary-based method to automatically detect lexical gender that can provide a dynamic, up-to-date analysis with high coverage. Our approach reaches over 80% accuracy in determining the lexical gender of nouns retrieved randomly from a Wikipedia sample and when testing on a list of gendered words used in previous research.
Unmasking Contextual Stereotypes: Measuring and Mitigating BERT's Gender Bias
Oct 27, 2020
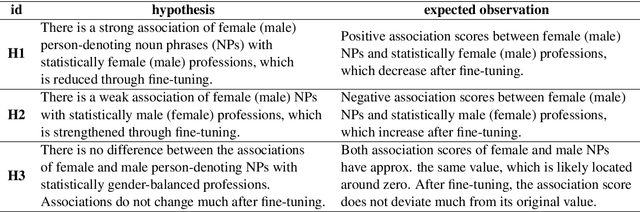
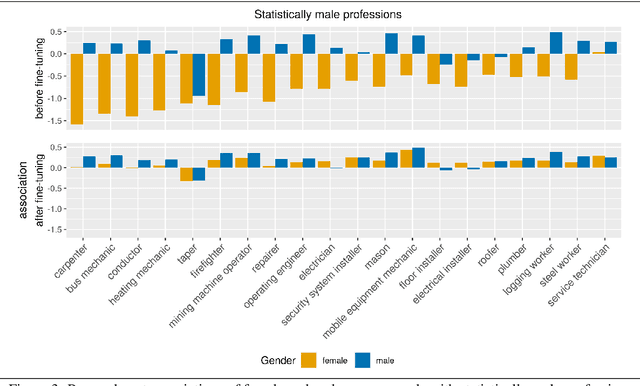
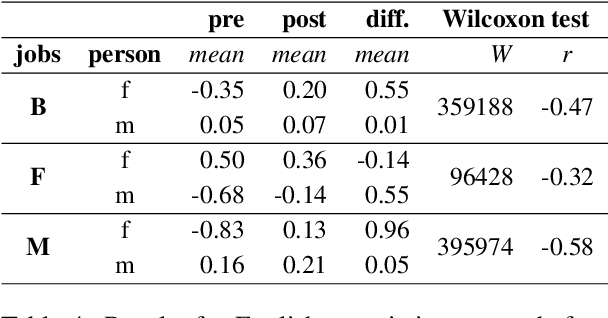
Contextualized word embeddings have been replacing standard embeddings as the representational knowledge source of choice in NLP systems. Since a variety of biases have previously been found in standard word embeddings, it is crucial to assess biases encoded in their replacements as well. Focusing on BERT (Devlin et al., 2018), we measure gender bias by studying associations between gender-denoting target words and names of professions in English and German, comparing the findings with real-world workforce statistics. We mitigate bias by fine-tuning BERT on the GAP corpus (Webster et al., 2018), after applying Counterfactual Data Substitution (CDS) (Maudslay et al., 2019). We show that our method of measuring bias is appropriate for languages such as English, but not for languages with a rich morphology and gender-marking, such as German. Our results highlight the importance of investigating bias and mitigation techniques cross-linguistically, especially in view of the current emphasis on large-scale, multilingual language models.